How to Access Llama 3.2: Streamlining Your AI Development Process
Learn how to access and implement Llama 3.2 models for your AI projects. Explore vision-enabled and lightweight LLMs, deployment options, and practical applications.

Llama 3.2 represents a significant leap in language model technology, introducing vision-enabled and lightweight models that expand the possibilities for AI applications. This article guides developers through accessing and implementing Llama 3.2, exploring its key features, deployment options, and practical use cases. Whether you're building for cloud, edge, or mobile platforms, Llama 3.2 offers powerful tools to enhance your projects.
Table of Contents
- Unveiling Llama 3.2: A Game-Changer in Language Models
- Llama 3.2 vs. Llama 3.1: Evolution in Action
- Llama 3.2 in the LLM Landscape
- Hands-on with Llama 3.2: Local Implementation Guide
- Accelerate Your AI Projects with Novita AI's Llama 3.2 Solutions
- Getting Started: Your Llama 3.2 Journey with Novita AI
Unveiling Llama 3.2: A Game-Changer in Language Models
Llama 3.2 introduces two groundbreaking categories of models that are set to revolutionize AI development:
Vision-Enabled LLMs (11B and 90B parameters)
These models represent a significant advancement in multimodal AI, capable of processing and understanding both text and images. Key features include:
- Multimodal Capabilities: Llama 3.2 can analyze images, answer questions based on visual content, and generate image captions.
- Document Understanding: The ability to extract information from documents containing charts, graphs, and other visual elements.
- 128k Token Context Length: This extensive context window allows for multi-turn conversations and complex reasoning tasks.
- Flexible Tile Sizes: Support for different image tile sizes (448 for 11B base, 560 for instruct and 90B models) enables adaptability to various input formats.
Lightweight LLMs for Edge and Mobile (1B and 3B parameters)
Designed for on-device AI, these models bring advanced language processing capabilities to resource-constrained environments:
- Optimized for Mobile Hardware: Runs efficiently on Arm processors, Qualcomm, and MediaTek chipsets.
- Real-Time Processing: Enables faster response times by eliminating the need for cloud communication.
- Enhanced Privacy: Keeps user data on the device, addressing privacy concerns.
- Multilingual Support: Handles multiple languages including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
Key Features Across All Models
- Multimodal Capabilities: From image understanding in larger models to efficient text processing in smaller ones.
- Extended Context Length: 128k tokens across all models, enabling more complex and context-rich interactions.
- Multilingual Support: Enhancing accessibility and global applicability.
Llama 3.2 vs. Llama 3.1: Evolution in Action
The transition from Llama 3.1 to 3.2 marks a significant evolution in the capabilities and applications of these language models:
Introduction of Vision-Enabled Models
- Multimodal Processing: Llama 3.2 introduces the ability to understand and reason over images, a capability absent in Llama 3.1.
- Architecture Enhancements: Combines Llama 3.1 language models with a vision tower and image adapter for comprehensive visual understanding.
- Training Data Expansion: Utilizes a massive dataset of 6 billion image-text pairs, significantly broadening the model's knowledge base.
New Lightweight Models for On-Device AI
- Efficiency Through Innovation: Employs pruning and distillation techniques to create compact yet powerful models.
- Hardware Optimization: Specifically designed for mobile and edge devices, opening up new possibilities for on-device AI applications.
Llama Stack: Standardized APIs and Deployment Infrastructure
- Unified Development Environment: Introduces Llama Stack, a comprehensive framework for building and deploying Llama models across various platforms.
- Pre-Built Solutions: Offers ready-to-use components for common tasks, accelerating development cycles.
- Cross-Platform Compatibility: Ensures seamless deployment across cloud, on-premises, single-node, and mobile/edge environments.
Llama Guard 3: Vision-Enabled Safety Model
- Enhanced Safety Measures: Updates the safety model to handle multimodal content, crucial for responsible AI deployment.
- Proactive Content Moderation: Classifies both model inputs and outputs to detect potentially harmful content, including in multimodal prompts.
These advancements collectively represent a significant leap forward, expanding the potential applications of Llama models and simplifying the development process for AI practitioners.
Llama 3.2 in the LLM Landscape
To understand Llama 3.2's position in the rapidly evolving field of language models, it's essential to compare its performance and capabilities with other prominent LLMs:
Comparison with Leading Models
GPT-4o-mini: Llama 3.2 performs comparably in multilingual tasks (MGSM benchmark). GPT-4o-mini shows superior performance in mathematical reasoning tasks (MMMU-Pro Vision and MATH benchmarks).
Claude 3 Haiku: Llama 3.2 outperforms Claude 3 Haiku in chart and diagram understanding tasks (AI2 Diagram and DocVQA benchmarks).
Benchmark Performance
AI2 Diagram and DocVQA: Llama 3.2 excels in these benchmarks, demonstrating strong capabilities in visual document understanding.
MGSM (Multilingual Grade School Math): Performs competitively, showcasing its multilingual capabilities.
MMMU-Pro Vision and MATH: Faces challenges in these mathematical reasoning tasks compared to some competitors.
Strengths
Chart and Diagram Understanding: Llama 3.2's vision-enabled models show exceptional performance in tasks involving visual data interpretation.
Multilingual Tasks: Strong performance across various languages, making it suitable for global applications.
Customizability: As an open-source model, Llama 3.2 offers flexibility for adaptation to specific use cases.
Challenges
Mathematical Reasoning: While competent, Llama 3.2 may not match the top performers in complex mathematical tasks, especially those involving visual components.
Licensing Restrictions: Usage limitations for entities based in the European Union may affect some developers and organizations.
Understanding these comparisons helps developers choose the right model for their specific needs, balancing factors like task performance, deployment flexibility, and licensing considerations.
Hands-on with Llama 3.2: Local Implementation Guide
Implementing Llama 3.2 locally involves several steps, from accessing the models to deploying them for specific tasks. Here's a comprehensive guide to get you started:
Accessing Models
Official Sources : Meta's Llama Website offers direct downloads of model weights and associated files. Hugging Face provides easy access to models and integration with popular ML libraries.
Other Platforms: Available through platforms like Novita AI, AMD, AWS, Databricks, and Google Cloud, offering various deployment options.
Converting Models for Desktop Use
To use Llama 3.2 models in desktop applications, you'll need to convert them to the GGUF format:
- Download the model files from an official source.
- Use tools like
llama.cppto convert the models to GGUF format. - Load the converted model into compatible applications or libraries for local inference.
Deployment Options
Llama 3.2 offers flexible deployment to suit various environments:
- Cloud: Utilize cloud providers' infrastructure for scalable deployments.
- On-Premises: Deploy on your own servers or private cloud for enhanced control and security.
- Single-Node: Run on a single powerful machine for development or small-scale applications.
- Mobile/Edge: Use lightweight models for on-device inference on mobile phones or edge devices.
Accelerate Your AI Projects with Novita AI's Llama 3.2 Solutions
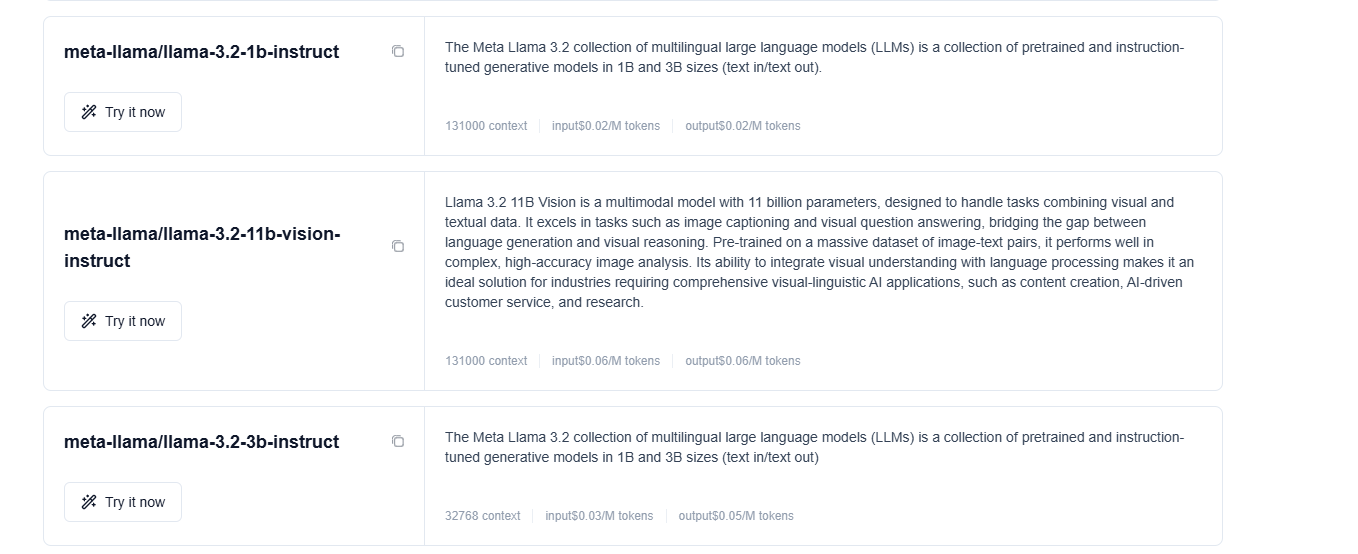
Novita AI offers a range of Llama 3.2 models tailored for various AI development needs, from edge computing to advanced multimodal applications. Let's explore how these solutions can accelerate your AI projects:
Llama 3.2 1B Instruct: On-device AI for Mobile and Edge Applications
This lightweight model is ideal for scenarios where low latency and privacy are paramount:
- Use Cases:
- Real-time text summarization on mobile devices
- On-device language translation
- Efficient chatbots for IoT devices
- Benefits:
- Minimal latency due to local processing
- Enhanced privacy by keeping data on-device
- Reduced cloud computing costs
Llama 3.2 3B Instruct: Enhanced Performance for Local Deployment
Striking a balance between efficiency and capability, this model is suitable for more complex local applications:
- Use Cases:
- Advanced personal assistants
- Content generation tools
- Code completion and analysis systems
- Benefits:
- Improved reasoning capabilities compared to the 1B model
- Still efficient enough for deployment on high-end mobile devices or edge servers
- Excellent performance in instruction-following tasks
Llama 3.2 11B Vision Instruct: Multimodal Capabilities for Advanced Tasks
This model unlocks the full potential of Llama 3.2's multimodal capabilities:
- Use Cases:
- Automated document analysis and data extraction
- Visual question answering systems
- Image captioning for accessibility applications
- Benefits:
- Comprehensive understanding of both text and visual data
- Ability to reason over complex documents with embedded visuals
- Superior performance in tasks requiring visual and textual context
Practical Applications

- Document Understanding:
Utilize the 11B Vision model to extract key information from financial reports, including data from charts and graphs. This can automate analysis and decision-making processes in financial institutions. - Visual Question Answering:
Implement an AI assistant that can answer questions about images, useful for e-commerce platforms or educational applications. Users can upload product images or diagrams and receive detailed explanations. - Image Captioning:
Enhance accessibility features of content management systems by automatically generating descriptive captions for images, making websites more inclusive for visually impaired users. - On-Device Text Analysis:
Use the 1B or 3B models to perform sentiment analysis, content categorization, or text summarization directly on mobile devices, ensuring user privacy and reducing server load. - Multilingual Customer Support:
Leverage the multilingual capabilities of Llama 3.2 models to create chatbots that can understand and respond in multiple languages, improving global customer support without the need for human translators.
By integrating these Llama 3.2 models into your projects, you can significantly enhance the capabilities of your AI applications while optimizing for performance and efficiency. Explore our LLM playground to test these models and see how they can benefit your specific use case.
Getting Started: Your Llama 3.2 Journey with Novita AI
Embarking on your Llama 3.2 journey with Novita AI is straightforward and rewarding. Here's a guide to help you get started:
1. Choose the Right Model
- Consider your application's requirements: computational resources, latency needs, and complexity of tasks.
- For on-device or edge applications, start with the 1B or 3B models.
- For complex, multimodal tasks, opt for the 11B Vision model.
2. Access the Models
- Sign up for a Novita AI account to access our Model APIs.
- Explore our LLM playground to experiment with different models at no cost.
3. Integration
- Use our Quick Start guide to integrate the Llama 3.2 API into your project.
- Our documentation provides code snippets and examples for various programming languages.
4. Scaling and Support
- As your project grows, leverage our GPU instances for increased processing power.
- Our support team is available to assist with any integration or optimization challenges.
By following these steps, you can quickly incorporate Llama 3.2's powerful capabilities into your AI projects, streamlining your development process and unlocking new possibilities in natural language processing and multimodal AI.
Conclusion
Llama 3.2 represents a significant advancement in language model technology, offering developers powerful tools for creating sophisticated AI applications. From vision-enabled models that can understand complex documents to lightweight versions optimized for edge devices, Llama 3.2 provides versatile solutions for a wide range of AI challenges. By leveraging Novita AI's seamless integration and support, developers can easily access and implement these cutting-edge models, accelerating their AI development process. As you embark on your Llama 3.2 journey, remember that the possibilities are vast, and the potential for innovation is limitless.
Frequently Asked Questions
- Is Llama 3.2 better?
Yes, Llama 3.2 offers significant advancements, including vision-enabled models and lightweight options for edge devices, enhancing its performance in multimodal tasks.
- Is Llama 3.2 better than ChatGPT?
Llama 3.2 excels in multimodal tasks (text and images), while the comparison depends on specific use cases; each has strengths in different areas.
- Can Llama 3.2 generate an image?
No, Llama 3.2 cannot generate images. It can process and analyze images for tasks like captioning and question answering.
- Is Llama 3.2 3B better than Gemma 2B?
Yes, Llama 3.2 3B outperforms Gemma in certain benchmarks, such as the ARC Challenge, particularly in reasoning tasks.
- Is Llama 3.2 free?
Llama 3.2 is open-source and available for download through Meta's website and Hugging Face, but users should be aware of licensing restrictions, especially for EU users.
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
1.Are Llama 3.1 Free? A Comprehensive Guide for Developers