How Good Are Large Language Models at Program Synthesis?

Introduction
How good are large language models at program synthesis? Some scholars may say, “For the largest LLMs, good enough!”
In this blog, we will embark on the journey of understanding program synthesis with large language models, from its definition and functioning to the frontier study about empirical evaluations of LLM’s programming capabilities. At the end of the journey, a step-by-step guide is attached for you to generate codes with LLMs yourself. Let the journey begin!
What Is Program Synthesis With Large Language Models?
Program synthesis is the process of automatically generating executable computer programs from high-level specifications or descriptions. The goal is to abstract away the low-level details of programming and allow users to express their desired functionality in a more natural, human-understandable way.

The key idea behind program synthesis is to have a system or algorithm that can take these high-level inputs, such as natural language descriptions, examples, or sketches, and then automatically produce the corresponding source code to implement the desired behavior.
This is in contrast to traditional software development, where programmers have to manually write out all the detailed logic and syntax of a program. Program synthesis aims to simplify this process and make programming more accessible to non-experts.
Some common applications of program synthesis include:
- Automating repetitive or tedious programming tasks
- Assisting novice programmers by generating code from their descriptions
- Enabling end-users to create custom applications without extensive coding knowledge
- Generating code from high-level specifications in domains like data analysis, machine learning, and system configuration
How Does LLM Work When Being Used to Generate Codes?
Large language models, such as GPT-3 and Codex, are advanced neural network architectures that have been trained on vast corpora of natural language and source code data. This training allows the models to develop a deep understanding of the semantic relationships, syntactic structures, and common patterns inherent in programming languages.
When tasked with generating code from natural language inputs, the LLM leverages this learned knowledge in the following manner:
Input Processing
The natural language description of the programming task is provided as input to the LLM. The model analyzes the semantics, intent, and context embedded within the input text.
Code Generation
Using its understanding of code structure, the LLM generates the most probable sequence of tokens (e.g., keywords, variables, operators) that would implement the desired functionality. This is an iterative process, where the model predicts the next most likely token based on the context of the partially generated code.
Code Refinement
The initial code generated by the LLM may not be complete or entirely correct. The model can then be prompted to refine the code, address any errors or inconsistencies, and expand on the initial generation to produce a more robust and comprehensive solution.
Output Formatting
The final generated code is formatted and presented as the output, ready for further review, testing, or deployment by the user.
The performance of LLMs in code generation tasks can vary based on factors such as the complexity and specificity of the natural language input, the quality and diversity of the training data, and the architectural capabilities of the particular LLM being used.
How Good Are Large Language Models at Program Synthesis?
In this section, we are going to explore the details of the study titled “Program Synthesis with Large Language Models”. As always, if you are not interested, just take this conclusion and skip to the next section: program synthesis performance scales log-linearly with model size. For the new dataset presented by the authors, LLMs with about 200 parameters can solve about 60% of problems even without fine-tuning.
Introduction and Background
The paper explores the potential of using large language models for program synthesis in general-purpose programming languages like Python. This is a longstanding goal in AI research, but previous work has largely been limited to restricted domain-specific languages. The authors note that recent advances in large language models, as well as the growing ability to apply machine learning techniques directly to source code text, suggest that a new approach to program synthesis in general-purpose languages may now be viable.
Datasets and Experiments
To evaluate large language models for this task, the authors introduce two new benchmark datasets — Mostly Basic Programming Problems (MBPP) and MathQA-Python. These datasets consist of short Python programming problems along with natural language descriptions, designed to test the models’ ability to synthesize code from text.

The authors evaluate a range of large language models, varying in size from 244 million to 137 billion parameters, on these datasets. They assess performance in both few-shot learning and fine-tuning regimes. They also study the models’ ability to engage in dialog and incorporate human feedback to improve their code synthesis.
Additionally, the researchers explore the semantic understanding of these models by fine-tuning them to predict the outputs of program execution.
Results
The results show that program synthesis performance scales log-linearly with model size. The largest models can solve around 60% of the MBPP problems using few-shot learning, and fine-tuning provides an additional 10 percentage point improvement.

On the more complex MathQA-Python dataset, the largest fine-tuned model achieves 83.8% accuracy. The authors find that incorporating human feedback can significantly reduce the error rate compared to the model’s initial predictions.
However, the models struggle to accurately predict the output of programs given specific inputs, suggesting limitations in their deeper understanding of program semantics.

How Can I Generate Codes With Large Language Models?
Step 1: Identify Appropriate Use Cases
Recognize that large language models excel at tasks like code completion, translation, and generating boilerplate code, but may struggle with complex algorithmic problems or highly domain-specific tasks. Align your expectations and use cases accordingly.
Moreover, based on your user case, you may need to compare different LLM options since they have differentiated features.

Step 2: Set up a Development Environment
Ensure you have the necessary hardware, software, and API access to work with your chosen large language model. This may involve setting up cloud computing resources, installing appropriate libraries and SDKs, and obtaining necessary API keys or credentials.
Novita AI provides LLM API keys with different LLM options as well as GPU Pods for setting up your development environment.
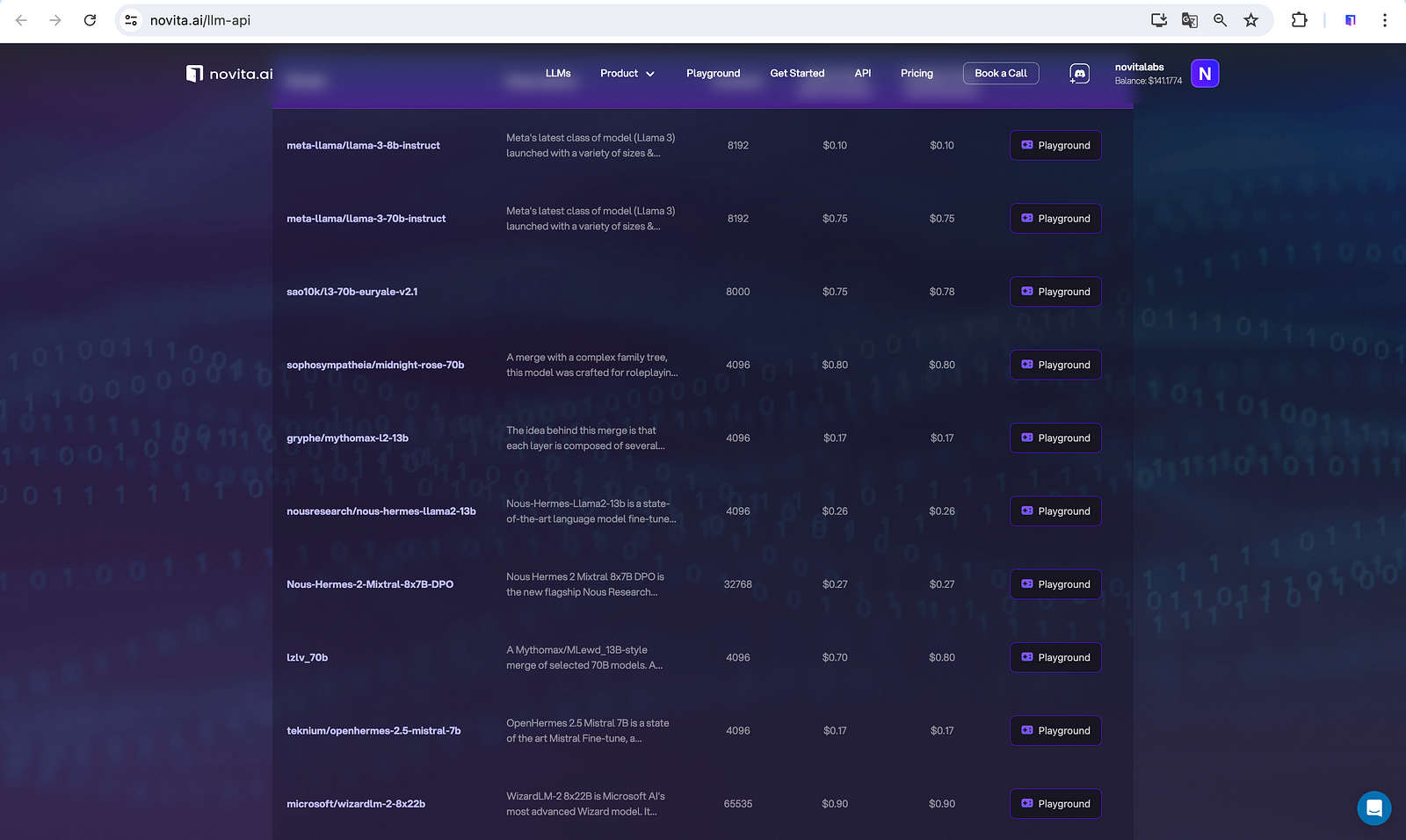
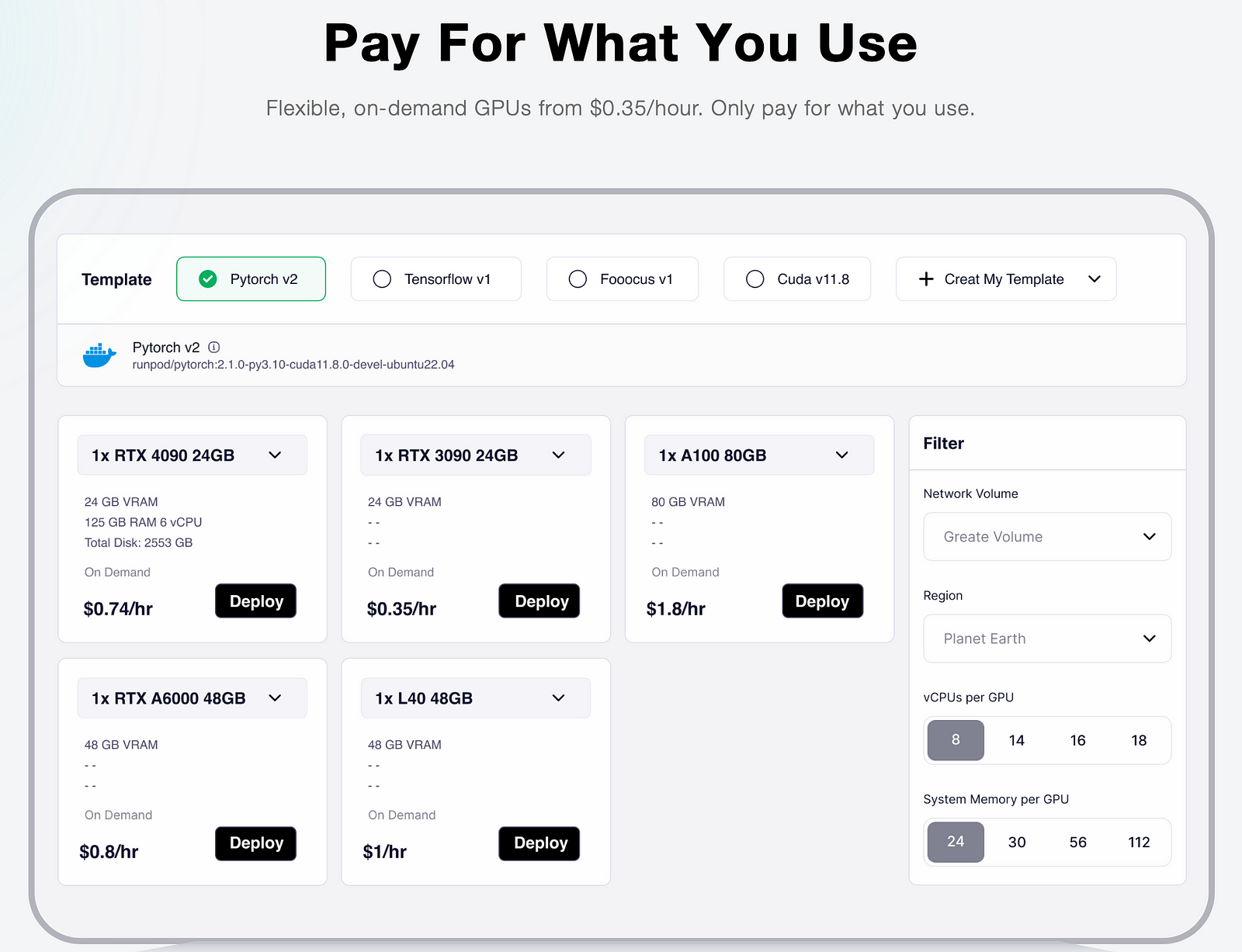
Step 3: Collect Relevant Training Data
If you plan to fine-tune a model, gather a high-quality dataset of code examples, problem descriptions, and solutions that are relevant to your target domain and use case.
Step 4: Experiment with Prompting Strategies
Learn effective techniques for crafting prompts that elicit the desired code generation behavior from the language model. This includes understanding how to provide context, specify requirements, and guide the model’s output.
Step 5: Implement Iterative Refinement
Plan for an iterative development process where you generate initial code, evaluate its correctness and quality, and then provide feedback to the model to improve subsequent generations.
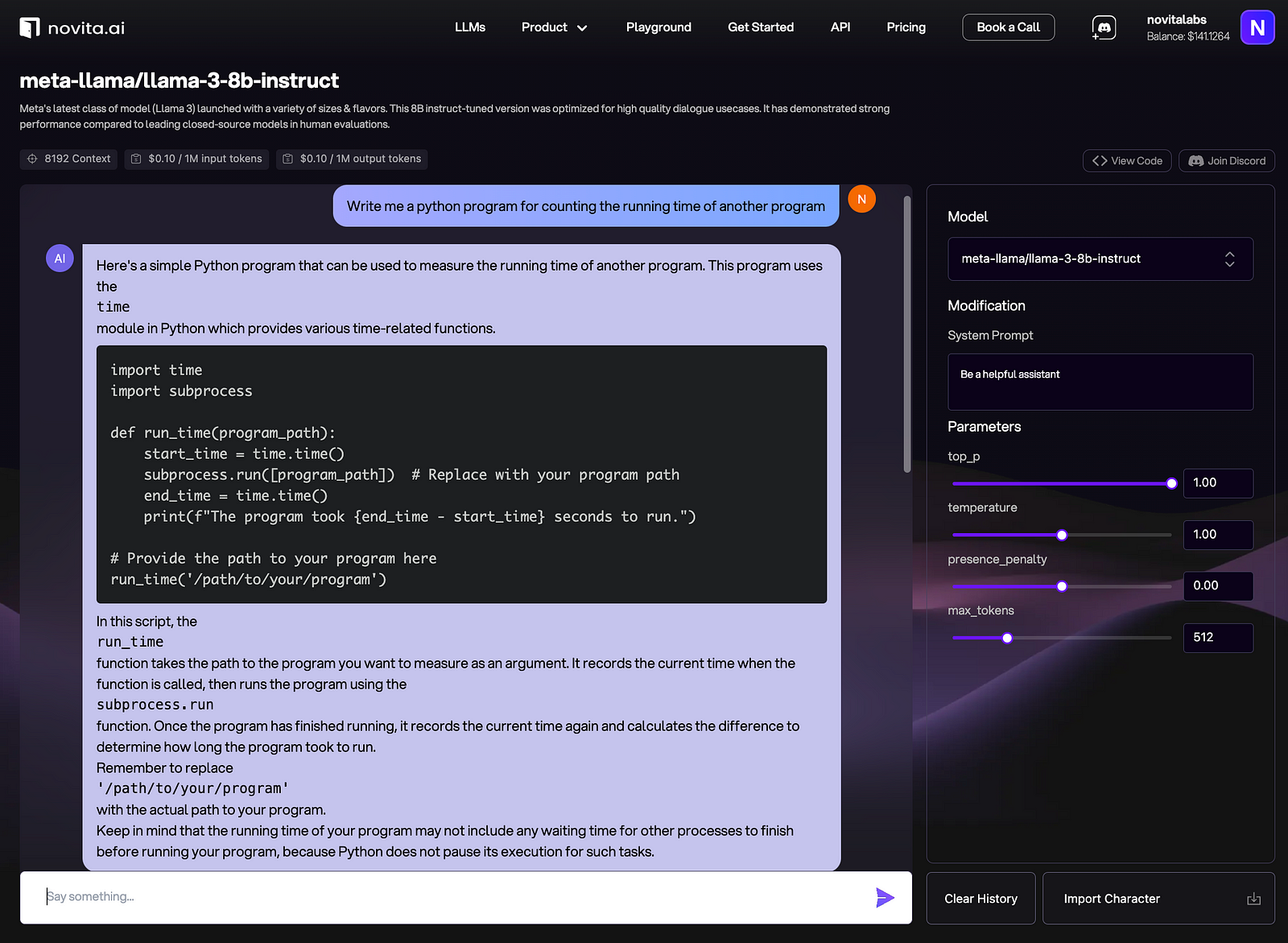
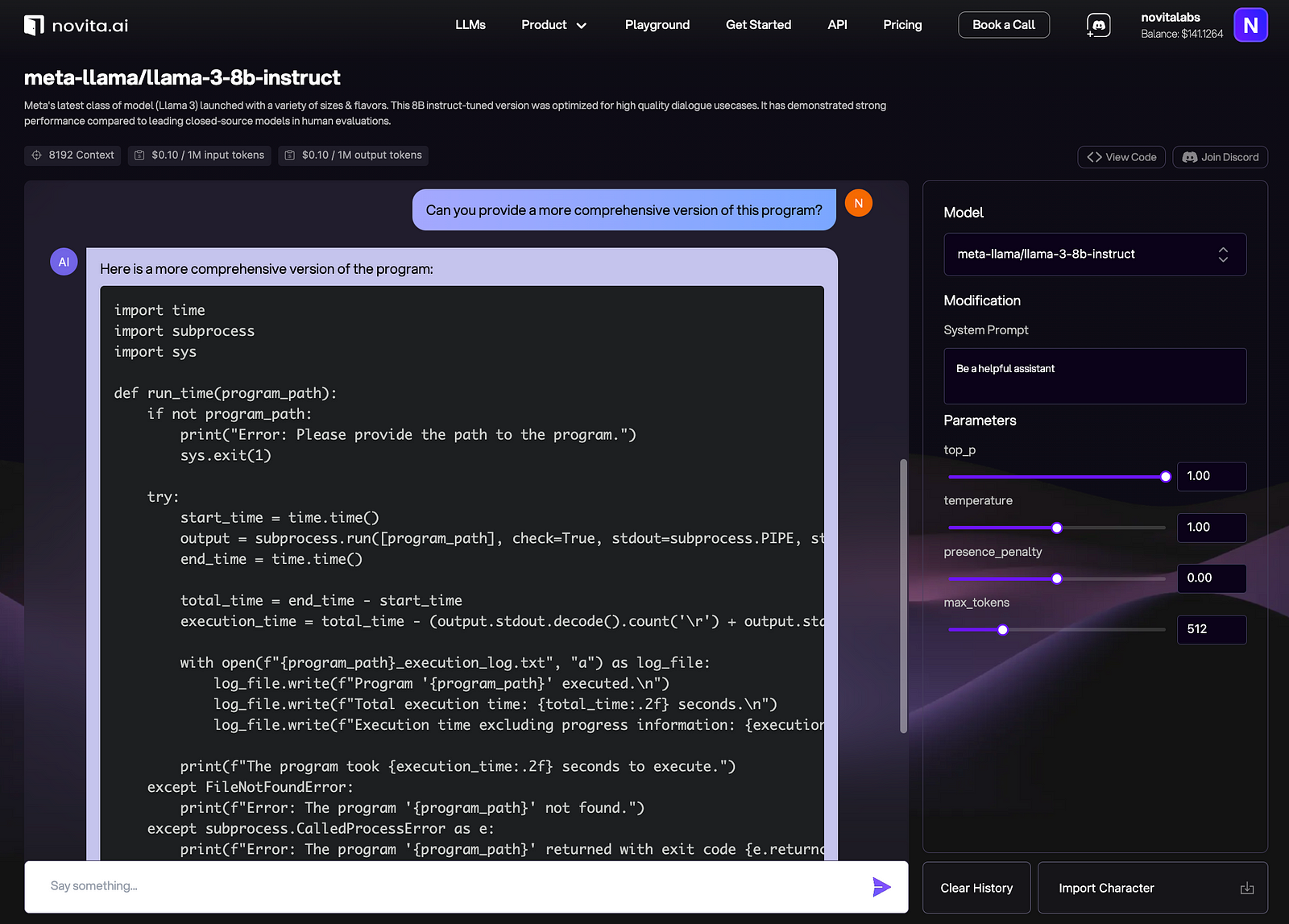
Step 6: Ensure Code Safety and Security
Be mindful of potential issues like model hallucinations, unsafe code generation, or unintended biases. Implement safeguards and validation steps to ensure the generated code is safe and secure.
To ensure the safety and security of code generated by large language models (LLMs), key steps include: carefully crafting prompts to encourage secure code generation, thoroughly validating user inputs, conducting code reviews and static analysis, executing the code in a secure sandbox environment, filtering and sanitizing the output, maintaining version control and provenance tracking, and continuously monitoring the system and incorporating feedback to improve the overall safety and security of the LLM-based code generation process.
Step 7: Integrate with Existing Workflows
Explore ways to seamlessly incorporate large language model-based code generation into your existing software development workflows, toolchains, and processes.
Step 8: Monitor Performance and Continuously Improve
Regularly evaluate the model’s performance, track metrics, and make iterative improvements to your prompting strategies, fine-tuning approaches, and overall integration.
Conclusion
In conclusion, large language models are showing impressive capabilities for program synthesis, especially as model sizes continue to grow. The ability to generate code from natural language descriptions has the potential to greatly simplify programming tasks and make software development more accessible. However, there are still limitations around deeper semantic understanding and reasoning about program behavior that need further research.
Given LLMs’ amazing programming capabilities, it’s an exciting chance for developers and non-developers to leverage these models for code generation. By providing natural language descriptions, individuals can harness LLMs to automatically synthesize code, streamlining development and enabling rapid prototyping, automation, and application creation. Try it out yourself!
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended Reading
What Will Happen When Large Language Models Encode Clinical Knowledge?
How Can Large Language Models Self-Improve?