How and Why Do Larger Language Models Do In-context Learning Differently?

Introduction
How and why do larger language models do in-context learning differently? In this article, we will explore the concept of “in-context learning” (ICL), discuss the latest findings about in-context learning behaviors of models of different sizes in plain English, and delve into ways that can leverage different LLM’s ICL behaviors. If you are interested, keep reading!
What Is “In-context Learning”?
In-context learning is an exciting capability that has emerged from the development of large language models (LLMs). It refers to the ability of these models to perform well on new, unseen tasks based solely on a brief series of task examples provided within the input context. This is a remarkable feat, as the models are able to adapt and apply their knowledge to novel situations without requiring any updates or fine-tuning to their underlying parameters.
The key aspect of in-context learning is that the model leverages the contextual information given as part of the input prompt to inform its response, rather than relying solely on its pre-existing knowledge or training. For instance, if you present a language model with a few examples of how to solve linear equations, it can then use that context to solve a brand new linear equation it has never encountered before. The model is able to infer the underlying pattern and apply it to the new problem, without needing to be explicitly trained on that specific type of equation.
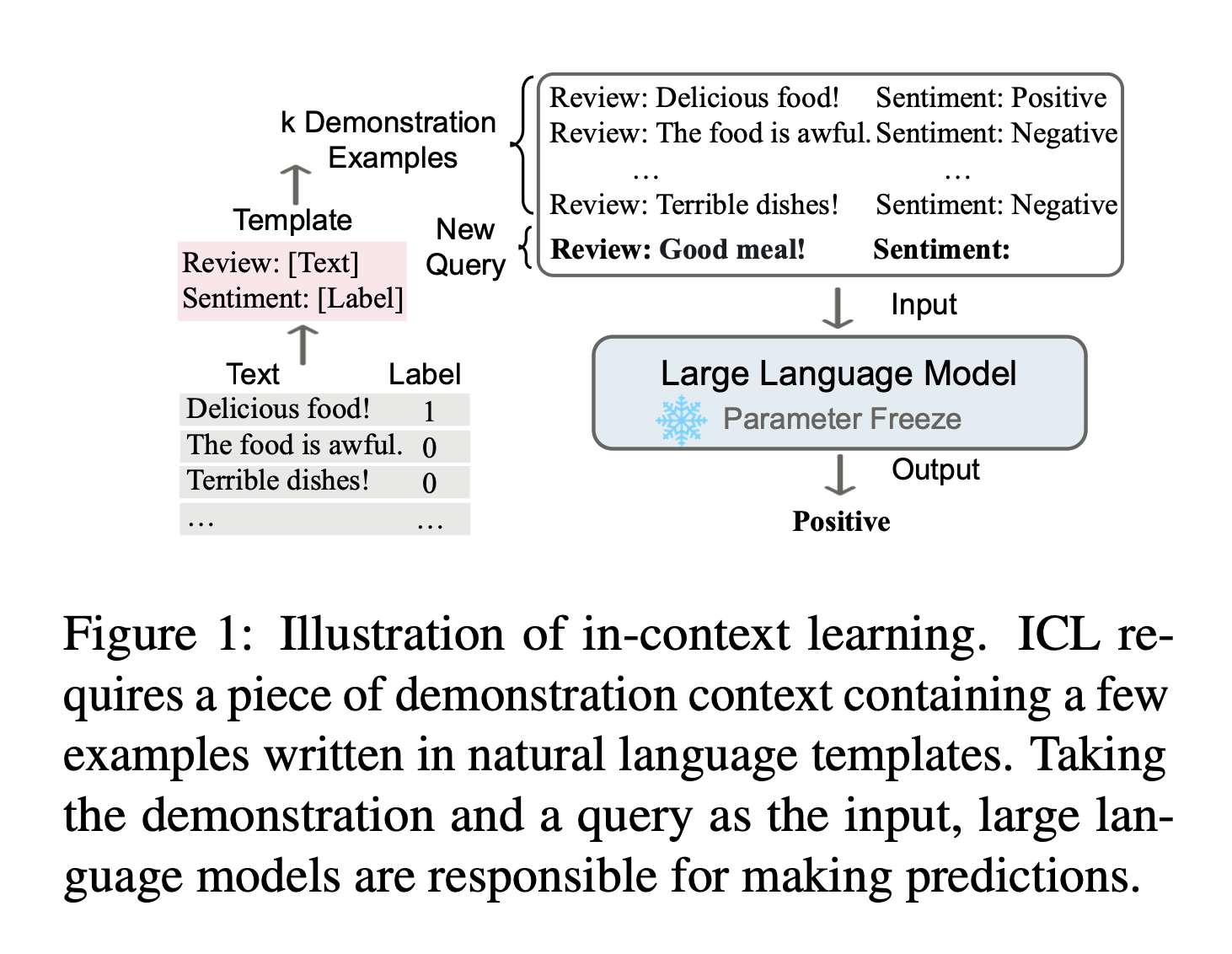
What Are the Benefits of “In-context Learning”?
Versatility and Adaptability
- ICL enables large language models to be applied across a wide range of tasks and domains without extensive retraining.
- This allows the models to continuously expand their capabilities by learning new skills through ICL.
Sample Efficiency
- ICL requires relatively few examples to learn new tasks, reducing data needs compared to traditional supervised learning.
- This is valuable when labeled data is scarce or expensive to obtain.
Computational Efficiency
- ICL can be performed with a single forward pass through the model, without parameter updates.
- This computational efficiency is important for real-time applications and resource-constrained deployments.
Emergent Capabilities
- Large language models can often perform well on unseen tasks through ICL, exceeding the performance of models trained explicitly on those tasks.
- This suggests the models can effectively leverage contextual information to solve new problems.
Insights into Model Behavior
- Understanding ICL can provide valuable insights into how large language models represent and utilize knowledge.
- This can inform the development of more robust and reliable AI systems.
A Big Finding: Larger Language Models Do In-context Learning Differently
The paper “Larger Language Models Do In-context Learning Differently” by Jerry Wei, Jason Wei, Yi Tay and others discuss whether in-context learning relies more on semantic priors from pretraining or learning input-label mappings from the exemplars.
If the research details do not interest you, just take this conclusion and jump to the next section: the larger the language model is, the less dependent it is on semantic prior (the inherent meaning and associations that language models learn during pretraining) and the more capable it is to learn from input contexts.
I Want to Dig Deeper
Background
- Language models can perform various downstream tasks through in-context learning (ICL), where they are given a few exemplars as part of the prompt.
- There is debate around whether ICL relies more on semantic priors from pretraining or learning input-label mappings from the exemplars.
Theoretical Settings
The authors investigate two setups to probe the interplay between semantic priors and input-label mappings:
- Flipped-label ICL: Labels in exemplars are flipped, forcing models to override semantic priors.
- Semantically-unrelated label ICL (SUL-ICL): Labels are semantically unrelated to the task, removing semantic priors.
Experiment Design
- Experiments conducted on 7 NLP tasks across 5 model families (GPT-3, InstructGPT, Codex, PaLM, Flan-PaLM) of varying sizes.
- Evaluate performance in the regular ICL, flipped-label ICL, and SUL-ICL settings.
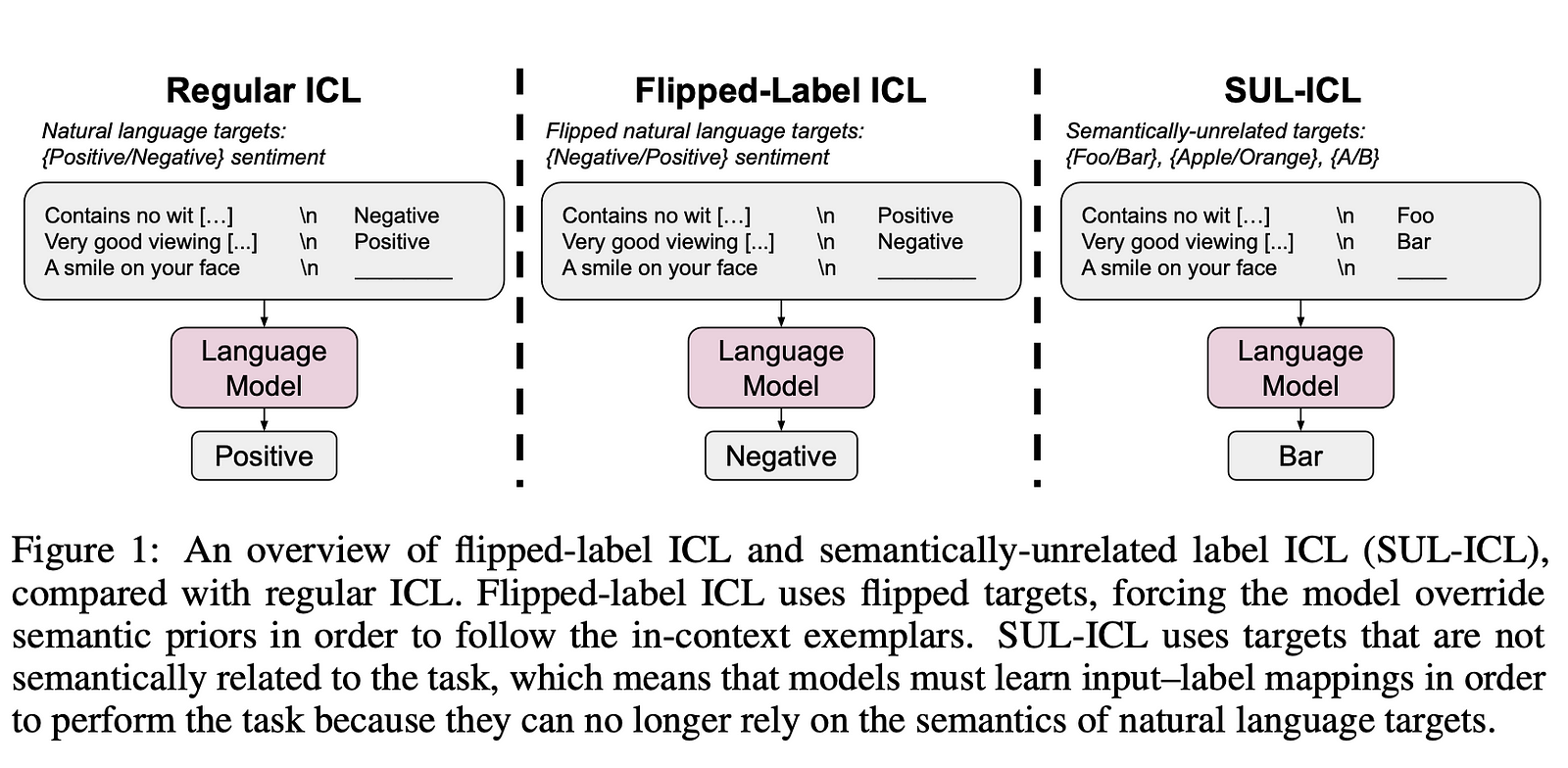
Key Findings
- Flipped-label ICL: Small models cannot override semantic priors, but large models can learn to follow flipped exemplar labels.
- SUL-ICL: Small models rely more on semantic priors, while large models can learn input-label mappings without semantic priors.

- The ability to override semantic priors and learn input-label mappings emerges with model scale.
- Instruction tuning strengthens the use of semantic priors more than the capacity to learn input-label mappings.
Why Do Larger Language Models Do In-context Learning Differently?
Another paper “Why Do Larger Language Models Do In-context Learning Differently?” by Zhenmei Shi, Junyi Wei, Zhuoyan Xu, and Yingyu Liang discusses the reasons behind different in-context learning performances of large and small LLMs. Here we offer two versions: Plain English Version and Professional Version. Feel free to choose whatever version suits you.
I Prefer the Plain English Version
This paper explains the “why” behind the different ICL behaviors of larger and smaller language models:
The key reason is related to how the models allocate attention across different features during the in-context learning process.
Smaller models tend to focus more on the important, informative features that are relevant for the task. They emphasize these key features and are therefore more robust to noise or irrelevant information in the input context.
In contrast, larger language models have the capacity to attend to a wider range of features, including those that are less important or even noisy. While this allows them to capture more information, it also makes them more susceptible to being distracted by irrelevant or noisy aspects of the input context.
Essentially, the larger models cover a broader set of features, both relevant and irrelevant, while the smaller models prioritize the most salient features. This difference in attention allocation is what leads to the greater robustness of smaller models during in-context learning compared to their larger counterparts.
I Want to Dig Deeper
Background of the Research
The paper examines why larger language models (LLMs) exhibit different in-context learning (ICL) behaviors compared to smaller models. ICL is an important emergent ability of LLMs, where they can perform well on unseen tasks based on a brief series of task examples without updating the model parameters. Recent studies have observed that larger LLMs tend to be more sensitive to noise in the test context, performing worse than smaller models.
Theoretical Settings
To understand this phenomenon, the paper analyzes two stylized settings:
- Linear regression with one-layer single-head linear transformers
- Parity classification with two-layer multiple attention heads transformers
The goal is to provide theoretical insights into how the attention mechanism and model scale affect ICL behavior.
For both settings, the authors provide closed-form optimal solutions and characterize how the attention mechanism differs between smaller and larger models.
Experiment Design
The authors conduct in-context learning experiments on five prevalent NLP tasks using various sizes of the Llama model families. The experimental results are used to corroborate the theoretical analysis.
Key Findings
- Smaller models emphasize important hidden features, while larger models cover more features, including less important or noisy features.
- Smaller models are more robust to label noise and input noise during evaluation, while larger models are more easily distracted by such noises, leading to worse ICL performance.
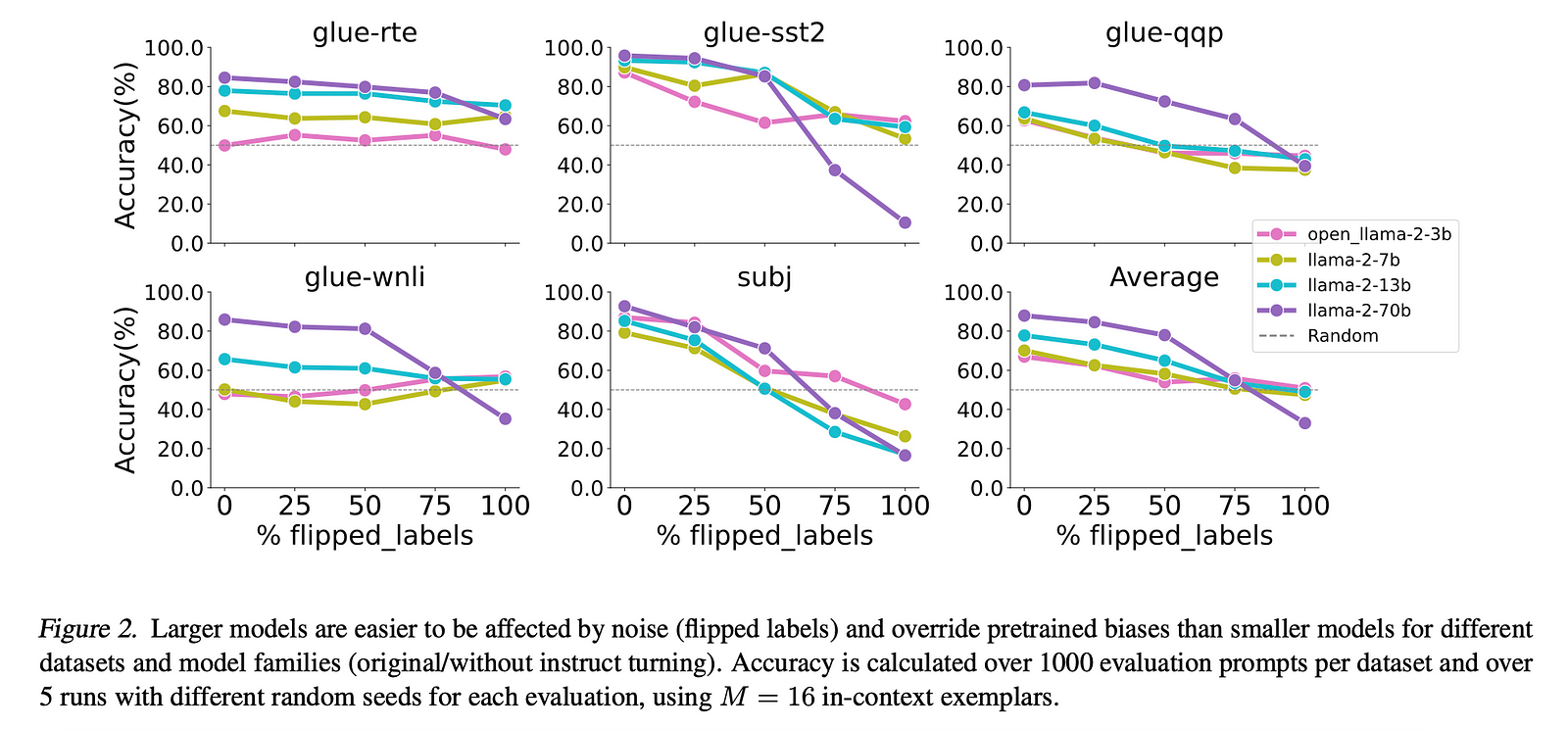
- The theoretical analysis and experimental results provide insights into how the attention mechanism and model scale affect ICL behavior, shedding light on the inner workings of LLMs.
Leveraging Different LLM’s ICL Behaviors
Recognizing these nuanced differences is crucial for selecting the appropriate model based on data characteristics and task requirements. As we have learned from two previous papers, Smaller models are more robust to noisy input, as they focus on key features and are less distracted by irrelevant information. Larger models, in contrast, excel at tasks requiring a comprehensive understanding of diverse features, leveraging their broader contextual knowledge.
Therefore, in order to leverage different LLM’s ICL behaviors, Novita AI provides AI startup developers with cost-effective and auto-scaling LLM APIs with different LLM model options.

Just in several lines of code, you can integrate powerful LLMs into your AI products. Feel free to try out capabilities of different LLMs on Novita AI Playground before you decide to use our APIs.

Conclusion
In-context learning is the ability of large language models (LLMs) to perform well on unseen tasks based on the input, i.e. the context.
How do larger language models do in-context learning differently? The larger the language model is, the less dependent it is on semantic prior and the more capable it is to learn from input contexts.
Why do larger language models do in-context learning differently? The key reason behind these differences is related to how the models allocate attention across different features during the in-context learning process.
To take advantage of the divergent in-context learning behaviors exhibited by different language models, implementing an API with diverse LLM model selections may prove advantageous.
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.