Explore Llama 3.1 Paper: An In-Depth Manual

Key Highlights
- Comprehensive Multilingual Support: Llama 3.1 excels in handling eight languages, making it ideal for global multilingual applications.
- Massive Scale and Compute Efficiency: With 405 billion parameters, Llama 3.1 is compute-optimized for high performance without excessive resources.
- Cutting-Edge Performance Across Benchmarks: It competes with top models like GPT-4, excelling in coding, math, and long-context tasks.
- Enhanced Model Architecture and Alignment: Advanced techniques like DPO align outputs with human preferences, boosting reliability.
- Open-Source Accessibility: Meta provides open access to Llama 3.1, fostering collaboration and innovation in AI.
- Unmatched Coding and Reasoning Abilities: The model delivers top performance in coding and complex problem-solving tasks.
Introduction
In the fast-changing world of Artificial Intelligence (AI), large language models (LLMs) represent some of the best new technology. These models, trained using huge amounts of data, are very good at understanding and creating text that sounds like a person wrote it. This blog post will explore the Llama 3.1 paper from Meta. It will give you a clear look at its design, abilities, and importance as a basic model in the field of NLP.
An Overview of Llama 3.1

Meta’s latest flagship language model, Llama 3.1, with 405 billion parameters, showcases Meta’s dedication to AI advancement. It excels in various tasks and languages, paving the way for new models based on Meta’s research and innovation.
Model Information
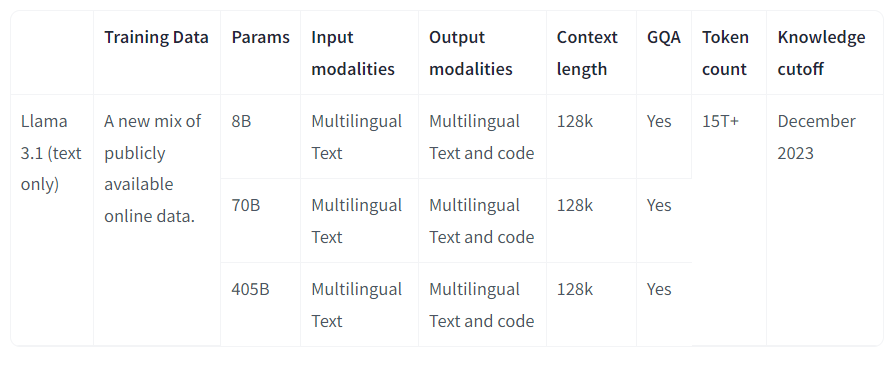
The Meta Llama 3.1 suite includes multilingual large language models (LLMs) in 8B, 70B, and 405B sizes, pre-trained and fine-tuned for generative text tasks. These text-only Llama 3.1 models excel in multilingual dialogue applications and outperform many industry benchmarks.
The model supports eight languages officially: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. The underlying training suggests capabilities beyond these languages.
Model Architecture
Llama 3.1 is an autoregressive language model built on an optimized transformer architecture. Its enhanced versions are refined through supervised fine-tuning (SFT) and reinforced learning from human feedback (RLHF), tailored to meet human standards for helpfulness and safety.
How Llama 3.1 differs

Llama 3.1 distinguishes itself from earlier versions and competitors in several important aspects:
- Scale: With 405 billion parameters, it’s substantially larger than its predecessors. The Llama 3.1 paper reveals, “We trained a model on a scale much larger than previous Llama models: our flagship language model used 3.8 × 10²⁵ FLOPs, nearly 50 times more than the largest Llama 2 version.”
- Compute-optimal size: The choice of 405 billion parameters is strategically based on scaling laws, as noted in the Llama 3.1 paper: “This size is compute-optimal according to scaling laws given our data and training budget.”
- Multilingual capabilities:Llama 3.1 rivals top AI models like GPT-4 across various benchmarks, with the Llama 3.1 paper stating, “Our experimental evaluation suggests that our flagship model matches leading language models like GPT-4 in a range of tasks, nearing state-of-the-art performance.”
Accessing and Understanding the Llama 3.1 Paper
The Llama 3.1 paper is a milestone in the open-source AI community, providing insights into the robust large language model (LLM). It explains the model’s architecture, training processes, and performance, fostering learning and innovation in understanding LLMs and their functionality, applications, and limitations.
- The Value of the Llama 3.1 Paper: The Llama 3.1 paper is essential for AI professionals as it offers in-depth insights into the model’s design, human-centric performance evaluations, and approaches to safety and alignment, fostering transparency and trust in AI systems.
- Downloading the Llama 3.1 Paper PDF: Meta’s commitment to open science is exemplified by the free availability of the Llama 3.1 paper in PDF format, enhancing accessibility and encouraging broader engagement in AI research.
Intended Use
Llama 3.1 revolutionizes AI research by offering a powerful language model for global researchers. Its advanced language abilities benefit real-life applications like enhancing chatbots and AI systems for better communication in customer service, education, and healthcare.
Intended Use Cases
Llama 3.1 is designed for both commercial and research applications across multiple languages. The instruction-tuned text-only models are specifically geared for assistant-like chat functions, while the pre-trained models are versatile enough to be adapted for a range of natural language generation tasks. Additionally, the Llama 3.1 model collection facilitates the enhancement of other models through the use of its outputs, including synthetic data generation and distillation. The Llama 3.1 Community License supports these varied use cases.
How to use
This repository includes two versions of the Meta-Llama-3.1–70B, one compatible with transformers and the other with the original Llama codebase.
Use with transformers
Beginning with transformers >= 4.43.0 onward, you can perform conversational inference using the Transformers pipeline abstraction or by utilizing the Auto classes with the generate() function.
Be sure to upgrade your transformers installation by running pip install --upgrade transformers.
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-70B"
pipeline = transformers.pipeline(
pipeline("Hey how are you doing today?")
Llama 3.1’s training dataset
The Llama 3.1 pre-training dataset was a carefully curated, well-balanced mixture of various general domains, meticulously processed to ensure high-quality and diverse training inputs.
Pre Training Data
The dataset construction involves four main stages:
- Quality Filtering: Non-English and low-quality captions are removed using heuristic measures like CLIP scores.
- Perceptual Deduplication: An internal SSCD copy-detection model deduplicates images on a large scale, retaining one image-text pair per duplicate group.
- Resampling: To ensure diversity, n-grams are created from high-quality text sources, and data is resampled based on their frequencies.
- Optical Character Recognition: Text within images is extracted using a proprietary OCR pipeline and combined with captions.
To enhance document understanding, the dataset also includes:
- Document Transcription: Document pages are rendered as images with paired text.
- Content Safety: Techniques like perceptual hashing are used to eliminate unsafe content such as CSAM.
- The dataset is refined to approximately 350 million image-caption pairs and enriched with an additional 150 million examples from various sources, including visual grounding, screenshot parsing, question-answer pairs, synthetic captions, and synthetically generated structured images.
Post Training Data
SFT Data:
- For images: Academic datasets are transformed into Q&A pairs through templates and LLM rewrites. Human annotators create diverse dialogues from multimodal data to enhance model-generated content.
- For synthetic data: Text representations of images are used with text-input LLMs to create question-answer pairs for corresponding images. This process involves converting Q&A texts and table data into synthetic images using captions and OCR extractions to generate conversational data.
- For videos: Academic datasets with annotations are turned into textual instructions and target responses for questions. Humans annotate videos with complex questions and answers requiring more than a single frame for context.
Preference Data:
The dataset includes model outputs rated “chosen” or “rejected” on a 7-point scale, with human annotations for preferences and corrections. Synthetic preference pairs are created using text-only LLMs to introduce errors into the fine-tuning dataset, generating negative samples through rejection sampling from unselected high-quality responses.
Applying DPO to Llama 3.1
Meta implemented Direct Preference Optimization (DPO) as a crucial part of the post-training process for Llama 3.1 to better align the model with human preferences. Here’s a breakdown of how this process was carried out:
Initial Setup:
- The process starts by training on human-annotated preference data, building on the most successful models from previous alignment rounds.
- The main objective is to ensure that the training data closely matches the distribution of the policy model being optimized in each cycle, which helps progressively enhance the model’s performance.
- Preference Data Collection:

- Preference data is gathered from human annotators who evaluate multiple model-generated responses for each prompt. These evaluations are based on the responses’ quality and preference, with clear rankings such as edited > chosen > rejected.
- This data encompasses responses sorted into various preference levels (significantly better, better, slightly better, or marginally better) and occasionally includes edited responses to further refine the chosen response.
Experiment of Llama 3.1
Llama 3.1’s Vision Experiments evaluate its image and video recognition performance. Speech Experiments showcase its speech recognition capabilities. The results highlight the model’s resilience and potential applications in AI.
Vision Experiments of Llama 3.1
Image Recognition Results

- The Llama 3-V 405B model surpasses GPT-4V in all benchmarks, though it slightly trails behind Gemini 1.5 Pro and Claude 3.5 Sonnet.
- It shows particular strength in document understanding tasks.
Video Recognition Results

- Llama 3 excels in video recognition, particularly with the 8B and 70B parameter models being assessed.
- It performs exceptionally well on the PerceptionTest, indicating a robust capacity for complex temporal reasoning.
- In long-form activity understanding tasks, such as ActivityNet-QA, Llama 3 delivers strong results even though it processes only up to 64 frames. This means that for a three-minute video, the model processes just one frame every three seconds.
Speech Experiments of Llama 3.1

A real-time streaming text-to-speech (TTS) system is now part of Llama 3, creating speech waveforms while decoding. This TTS system uses Llama 3 embeddings for improved latency, accuracy, and naturalness during inference.
What is annealing, and how does it work?
Training large language models like Llama 3.1 involves ‘annealing,’ which fine-tunes the model for better task performance. The term is borrowed from metallurgy, where annealing toughens materials by heating and slowly cooling them.
The annealing process for Llama 3.1 involves several key components:
- Gradual Reduction of Learning Rate: The learning rate is systematically decreased to zero, stabilizing parameters and enhancing generalization by minimizing overfitting.
- Upsampling High-Quality Data: The training data mix is adjusted to prioritize high-quality sources, improving model performance and accuracy.
- Polyak Averaging: This technique averages parameters from various checkpoints during annealing to create a stable pre-trained model.
Overall, the annealing process ensures smooth convergence, enhances stability through smaller parameter updates, and results in a robust and precise model well-equipped for generalization to new data.
Improving Llama 3.1’s coding, multilingual capabilities, and more
Emphasis was put on enhancing Llama 3.1’s capabilities through additional training in coding, multilingual abilities, math reasoning, long-context handling, tool use, accuracy, and steerability. Human evaluations and annotations ensured top-quality performance in these optimized features.
Llama 3.1’s coding skills

Llama 3.1 shows robust performance across a range of coding benchmarks. The evaluations utilize the pass@N metric, which measures the success rate of a set of unit tests across N generations. Key findings include:
Python Code Generation:
- HumanEval: Llama 3 8B scores 72.6±6.8, 70B reaches 80.5±6.1, and 405B achieves 89.0±4.8.
- MBPP: Llama 3 8B scores 60.8±4.3, 70B achieves 75.4±3.8, and 405B reaches 78.8±3.6.
- HumanEval+: The results are 67.1±7.2 for Llama 3 8B, 74.4±6.7 for 70B, and 82.3±5.8 for 405B.
Multi-Programming Language Code Generation:
- Evaluations are conducted using MultiPL-E, which features translations of problems from HumanEval and MBPP into various programming languages such as C++, Java, PHP, TypeScript, and C#.
- For HumanEval in C++: Llama 3 8B scores 52.8 ±7.7, and Llama 3 405B achieves 82.0 ±5.9.
- For MBPP in C++: Llama 3 8B scores 53.7 ±4.9, and Llama 3 405B achieves 67.5 ±4.6.
Llama 3.1’s math and reasoning capabilities

Llama 3.1 has shown remarkable performance on various math and reasoning benchmarks, underscoring its proficiency in these areas. Below are the key results from the evaluations:
GSM8K (8-shot, Chain of Thought — CoT):
- Llama 3 8B: 57.2±2.7
- Llama 3 70B: 83.0±7.4
- Llama 3 405B: 90.0±5.9
MATH (0-shot, CoT):
- Llama 3 8B: 20.3±1.1
- Llama 3 70B: 41.4±1.4
- Llama 3 405B: 53.8±1.4
ARC Challenge (0-shot):
- Llama 3 8B: 79.7±2.3
- Llama 3 70B: 92.9±1.5
- Llama 3 405B: 96.1±1.1
Meta faced several challenges in enhancing Llama 3.1’s mathematical and reasoning abilities, including:
- Lack of Prompts
- Lack of Ground Truth Chain of Thought
- Incorrect Intermediate Steps
- Teaching Models to Use External Tools
- Discrepancy Between Training and Inference
How Llama 3.1 performs in long-context scenarios?

Llama 3.1 excels in long-context benchmarks, showcasing its ability to efficiently handle and retrieve information from lengthy documents. Here are the key evaluation results:
- Needle-in-a-Haystack: It achieves a 100% success rate in retrieving hidden information from long documents and nearly perfect results in the Multi-needle variation.
- ZeroSCROLLS: The 405B and 70B models match or surpass competitors in natural language understanding over extended texts.
- InfiniteBench: The 405B model outperforms all competitors in tasks requiring long-context understanding, notably excelling in question-answering over novels (En.QA).
After reviewing the LLaMA 3.1 paper, its scholarly contributions shine in real-world scenarios. The LLM API simplifies complex research for developers by bridging academic theory with practical implementation efficiently. Let’s explore how the LLM API achieves this.
Utilizing Llama 3.1 Variants on Novita.AI
Novita AI is a robust platform for managing Llama 3.1 models, offering an intuitive interface and powerful APIs that simplify integration into real-world applications. It automates system management, scales resources efficiently, and ensures high performance while prioritizing security and data privacy. By enabling easy access to advanced LLMs, Novita AI empowers developers and businesses to accelerate AI projects and drive innovation across various industries.
How to deploy LLM API on Novita.AI?
Adhere to these structured steps carefully to develop powerful language processing applications using the Llama 3.1 API on Novita AI. This detailed guide ensures a smooth and efficient process, meeting the needs of modern developers who are in search of an advanced AI platform.
Step 1: Sign up and log into Novita AI

Step 2: Navigate to the Dashboard tab on Novita AI to obtain your API key. You can also choose to create a new key.

Step 3: After reaching the Manage Keys page, click “Copy” to easily retrieve your key.

Step 4: Go to the LLM API reference to discover the “APIs” and “Models” offered by Novita AI.

Step 5: Choose the model that best suits your requirements. Set up your development environment and adjust settings like content, role, name, and detailed prompt accordingly.

Step 6: Conduct several tests to confirm the API’s consistent performance.
How to experience the LLM Playground on Novita AI?
Before you officially deploy the LLM API on Novita AI, you can explore and experiment with it in the LLM Playground. We offer developers a free usage quota. Next, I’ll guide you step-by-step through the process of getting started.
Step 1: Access the Playground: Go to the Products tab in the menu, select Model API, and begin exploring by choosing the LLM API.

Step 2: Select from Various Models: Choose the llama model that best suits your evaluation needs.

Step 3: Enter Your Prompt and Generate Output: Input the prompt you want to use in the designated field. This area is where you type the text or question for the model to process.
Conclusion
The Llama 3.1 paper talks about a new model that has amazing skills in many areas. It covers everything from how the model is built to the results of tests and what it can be used for. This guide gives useful information for tech lovers and researchers. If you want to learn more, you should check out the Llama 3.1 paper PDF. This will help you understand its math, reasoning skills, and ability to work in different languages. Llama 3.1 has the power to change how AI works. Its different versions on Novita.AI provide great chances to use this technology. Explore advanced AI with Llama 3.1 for a notable change.
Frequently Asked Questions
Can Llama 3.1 Be Used for Generating Creative Content?
Yes, Llama 3.1 can generate creative content. Its generative AI features allow it to make different types of text. This includes poems, scripts, and even music. This shows how versatile it is in many creative uses.
How Does Llama 3.1 Handle User Privacy and Data Security?
Llama 3.1 features Llama Guard to ensure user privacy and data security, promoting responsible AI use. It prevents misuse, supports ethical choices, and employs encryption for data safety.
Is Llama 3.1 better than GPT-4?
If you prioritize accuracy and efficiency in coding tasks, Llama 3 might be the better choice.
What is Llama 3.1 405B?
The Llama 3.1 models, with 8B, 70B, and 405B parameters, showcase top performance on industry benchmarks and provide new capabilities for generative AI applications.
Why is llama a big deal?
Llama, a significant AI advancement, offers impressive capabilities and open accessibility. Its release democratizes AI research, fostering creativity and collaboration to drive innovation across various domains.
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
1.Enhance Your Projects with Llama 3.1 API Integration