Enhance Efficiency: Fastest LLM API for Developers

Unlock the power of the fastest LLM API for enhanced performance. Streamline your processes with our advanced technology.
Key Highlights
- Understanding the factors affecting API speed is crucial. Setup, technology, and optimization techniques all play a significant role in efficiency. Gear and tech are essential for optimal API performance.
- Utilizing methods like caching, data compression, and task optimization can reduce wait times.
- Comparing different LLM APIs helps developers choose the fastest and most effective option.
- Implementing caching, reducing API calls, optimizing code efficiency, and leveraging asynchronous processing are key strategies to speed up an LLM API’s performance.
- Novita AI unveiled the LLM API on its AI API platform. The LLM API is cost-effective and user-friendly, catering to developers and large enterprises to produce faster on a large scale with advanced conversational AI.
Introduction
This blog explores the impact of LLM APIs, with a focus on LLM APIs and their speed capabilities. Emphasizing the significance of response time in API performance, we will examine factors influencing their efficiency and recommend top-performing APIs, as well as provide integration tips. The guide aims to enhance operational efficiency by enhancing understanding of API response time in LLMs. Stay tuned for insights on future advancements in these technologies.
Understanding LLM API
To maximize LLM APIs mastering the nuances is crucial. These systems are complex, focusing on enhancing computer language comprehension. Familiarity with their intricacies is essential for optimal usage and seamless operations. The online forum and provider’s website like Novita AI is a valuable resource where developers exchange tips on setup and issue resolution. Developers can unlock the full potential of LLM APIs for groundbreaking AI projects by exploring diverse applications.
The Basics of LLM API
LLM APIs play a crucial role in natural language tasks, utilizing advanced deep learning methods to understand and generate coherent responses. By leveraging LLM models, you tap into a realm of knowledge. Understanding how these models interpret language, and context, and provide accurate answers is key. LLM APIs can be customized for different purposes, such as enhancing chatbots or summarizing content efficiently, showcasing their versatility across various contexts.
Why Speed Matters in API Implementations
In the digital service realm, API speed is crucial for user satisfaction and system performance. Fast API responses lead to improved functionality and user productivity. API speed is vital for smooth user interactions, system reliability, and success.
Poor API performance can lead to bottlenecks, slow response times, and even outages due to the high dependence of applications and systems on APIs. Performance monitoring is crucial for proactive issue resolution, detecting anomalies, unusual patterns, and bottlenecks, and enabling developers to promptly address any arising issues.
Key Factors Influencing API Performance
API performance includes speed, reliability, and efficiency in processing requests and delivering responses. Key metrics are response time, throughput, and scalability. Smooth operations and pipeline optimization are essential for top-notch performance.
Infrastructure and Technology Stack
A high-performance tech stack includes programming languages, frameworks, libraries, and databases. Server strength, setup efficiency, and smooth operation are vital factors. Quantization compresses models for efficient deployment, and selecting the right technology mix is crucial for a responsive and efficient API.
Response Time
The efficiency and performance of an API heavily rely on the response time, which is influenced by factors like the complexity of the request, data size, network latency, server load, and API quality. Response time is typically measured in milliseconds or seconds, with faster responses enhancing user experience.
Latency
API Latency is the time taken for an API to process a request and send a response, including network or processing delays. Factors like network speed, API processing time, and data size can affect latency. Low latency is ideal for quick API responses.
Throughput
Throughput refers to the number of requests that an API can handle within a specific time frame. Factors affecting API throughput include network bandwidth, data size, server processing power, and implementation efficiency. It is measured by requests or transactions per second.
Best Examples of Fast LLM API
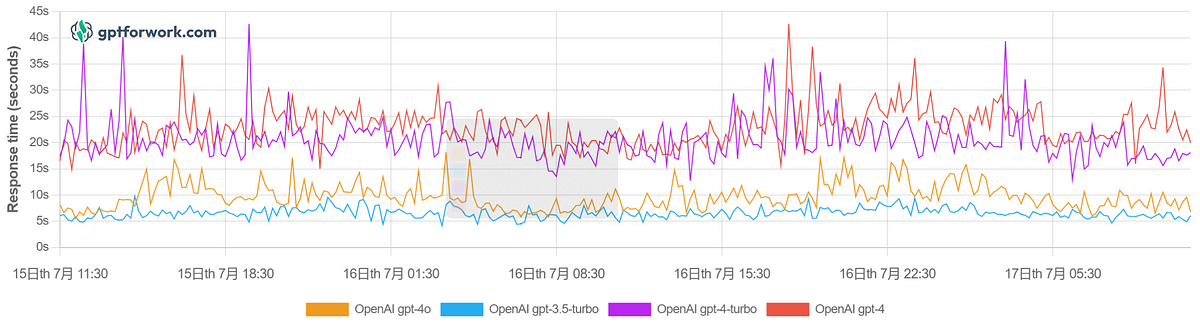
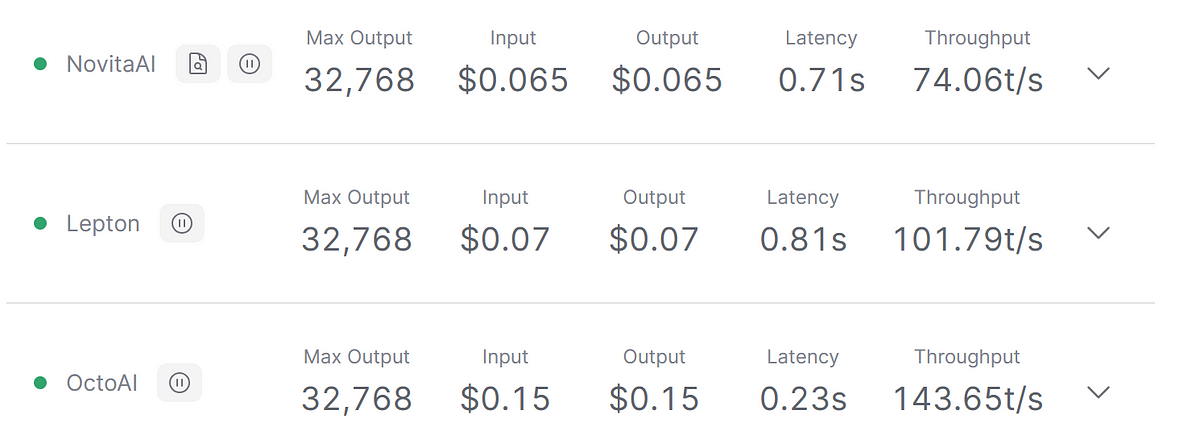
As shown in the figure above, speed is a crucial performance aspect in the LLM API, so let’s explore some fast LLM APIs. These APIs cater to different language tasks, showcasing exceptional speed and precision in NLP challenges. Tool choices significantly affect speed and reliability in API implementation.
OpenAI
OpenAI provides ChatGP families and LLM API that offers powerful natural language generation capabilities. The OpenAI API serves various purposes, including natural language generation and image processing. However, the cost of OpenAI is high for businesses to produce scalably.
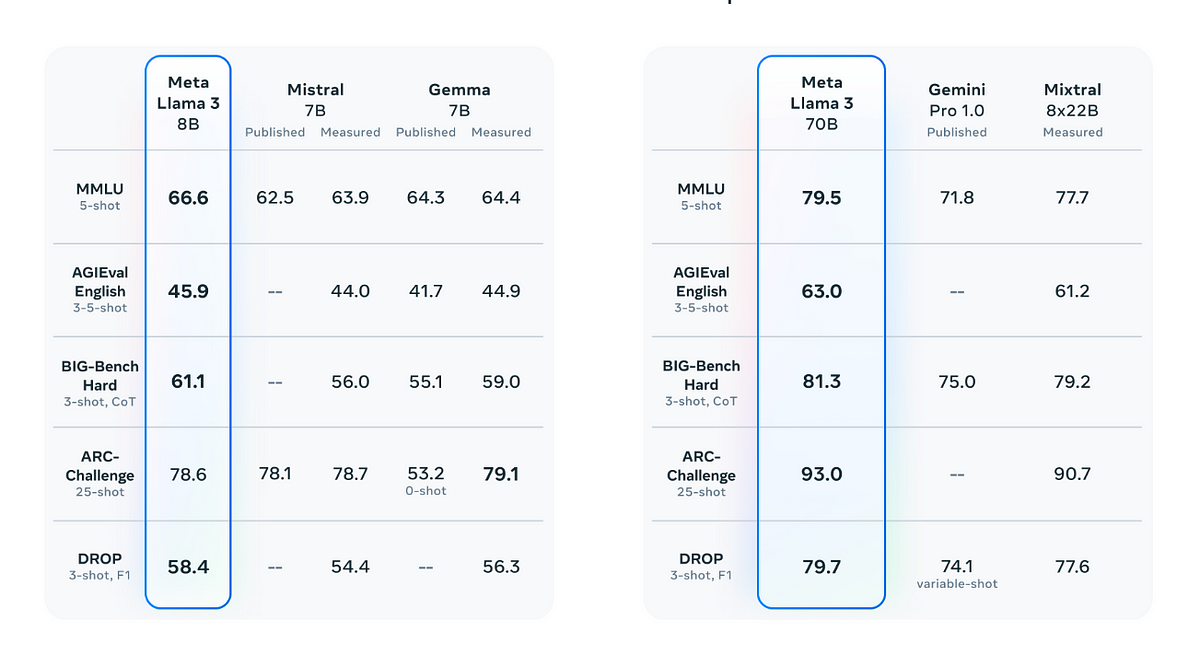
Meta
The API developed by Meta provides a way to interact with the advertising platform programmatically, allowing for more efficient and customized ad management processes. Connect with customers and improve efficiency.
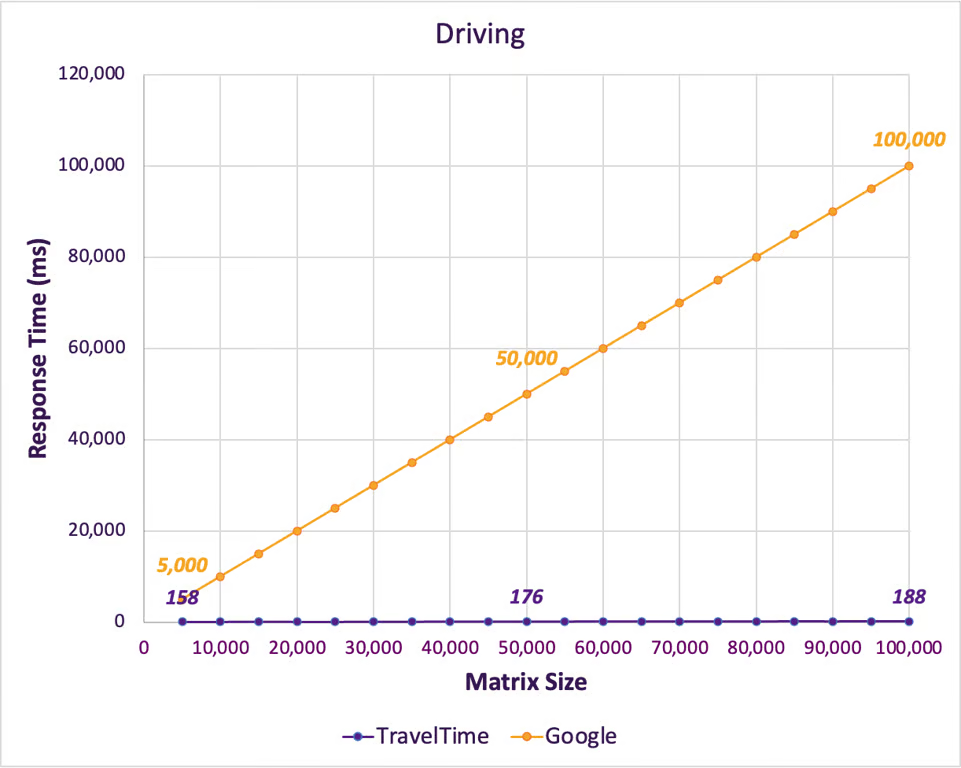
Developers can utilize Google APIs to connect with Google products, computing power, and information. These APIs enable the integration of custom tools, services, or libraries into a developer’s applications and codebase. This tool is particularly useful with Google products.
Anthropic
The Anthropic API consistently receives JSON in requests and sends back JSON in responses, designed to access Anthropic’s state-of-the-art conversational AI model by setting up an access key. It has a high requirement for code learning.

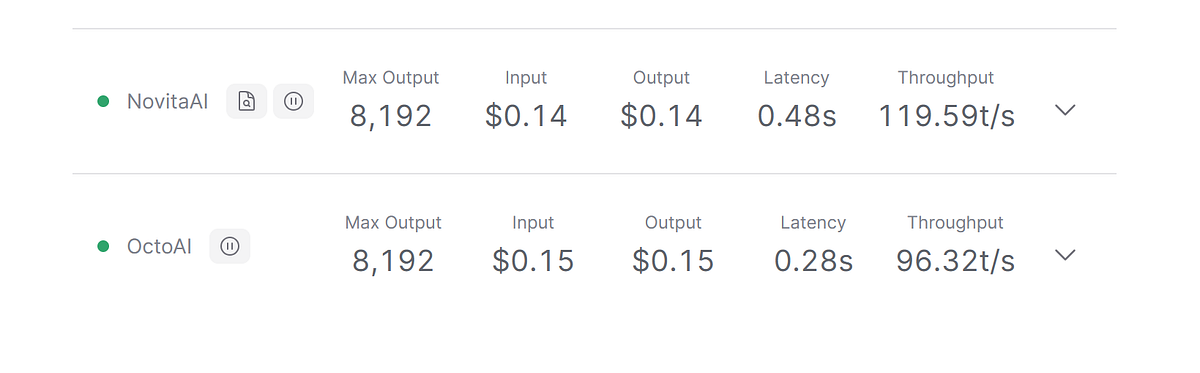
Novita AI
Novita AI is an AI API platform. The LLM API platform offers many LLM choices with low prices and strong performances. Novita AI maintains low latency and fast response time. If you don’t have particularly high latency requirements, Novita AI is your perfect cost-effective choice.
How to Use LLM API with Novita AI
As mentioned before, Novita AI is a reliable, cost-effective and auto-scaling AI API platform. With Novita AI’s service, you can quickly develop your own LLM API. Now let’s give it a try with the platform.
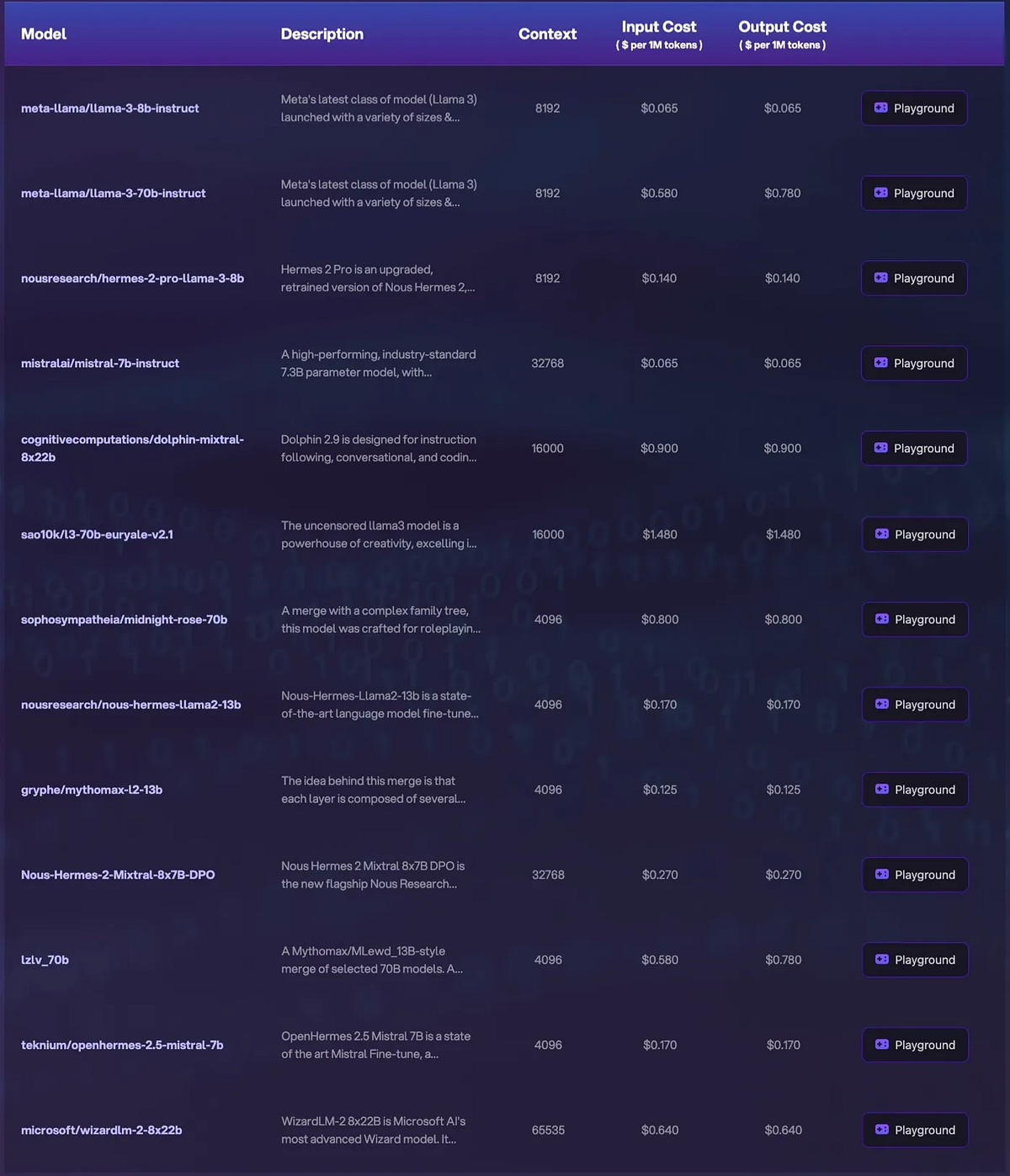
A step-by-step guide to using Novita AI LLM API
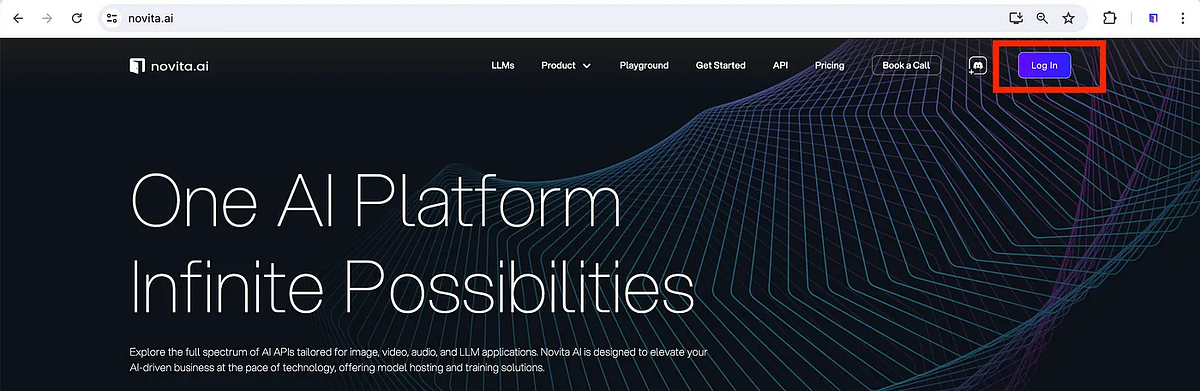
- Step 1: Register an Account. Navigate to the Novita AI website and click the “Log In” button in the top menu. You can sign in using a Google or GitHub account. Upon logging in, you will be awarded an amount of quota for free.
- Step 2: Generate an API Key. Click the “Key” under the menu. To authenticate with the API, we will provide you with a new API key. Entering the “Manage Keys“ page, you can copy the API key as indicated in the image.
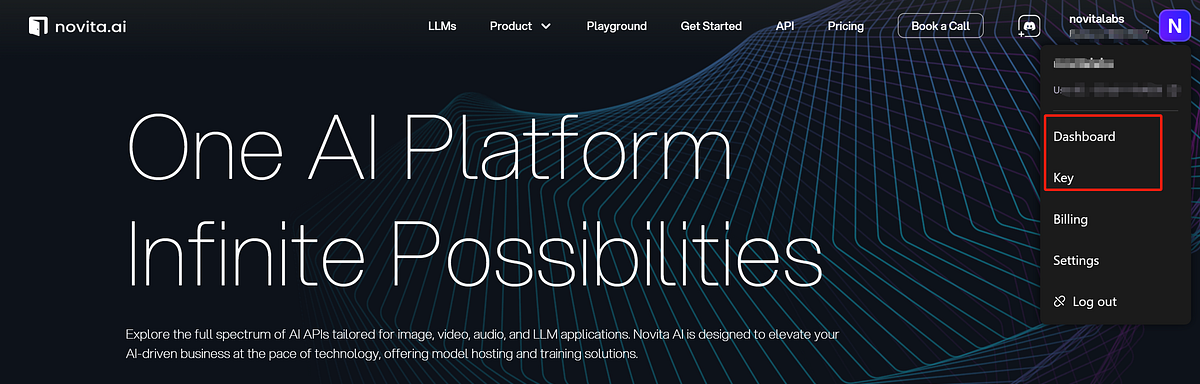
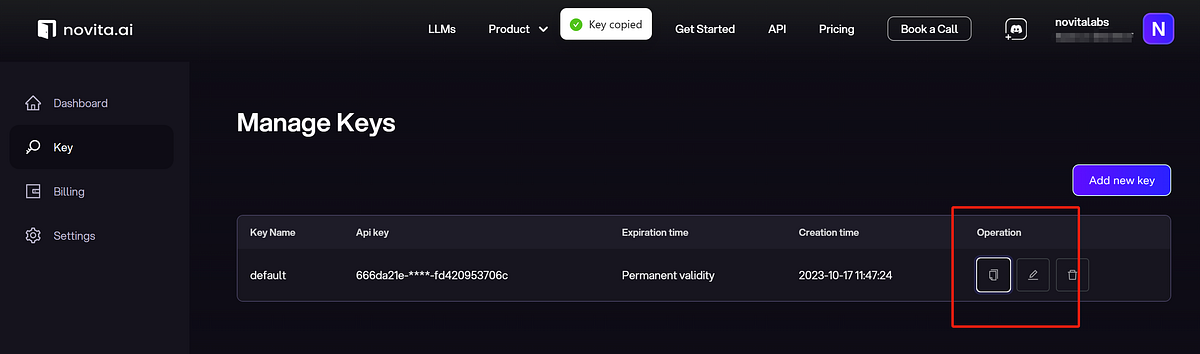
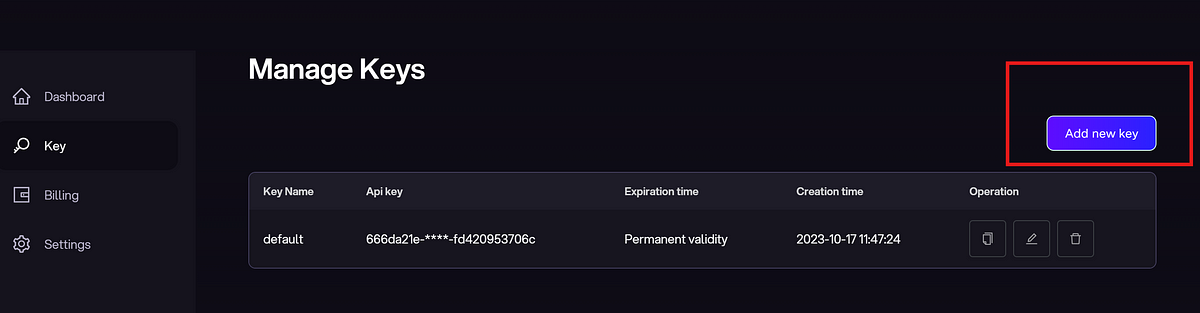
You can also create your own key by selecting “Add new key”.
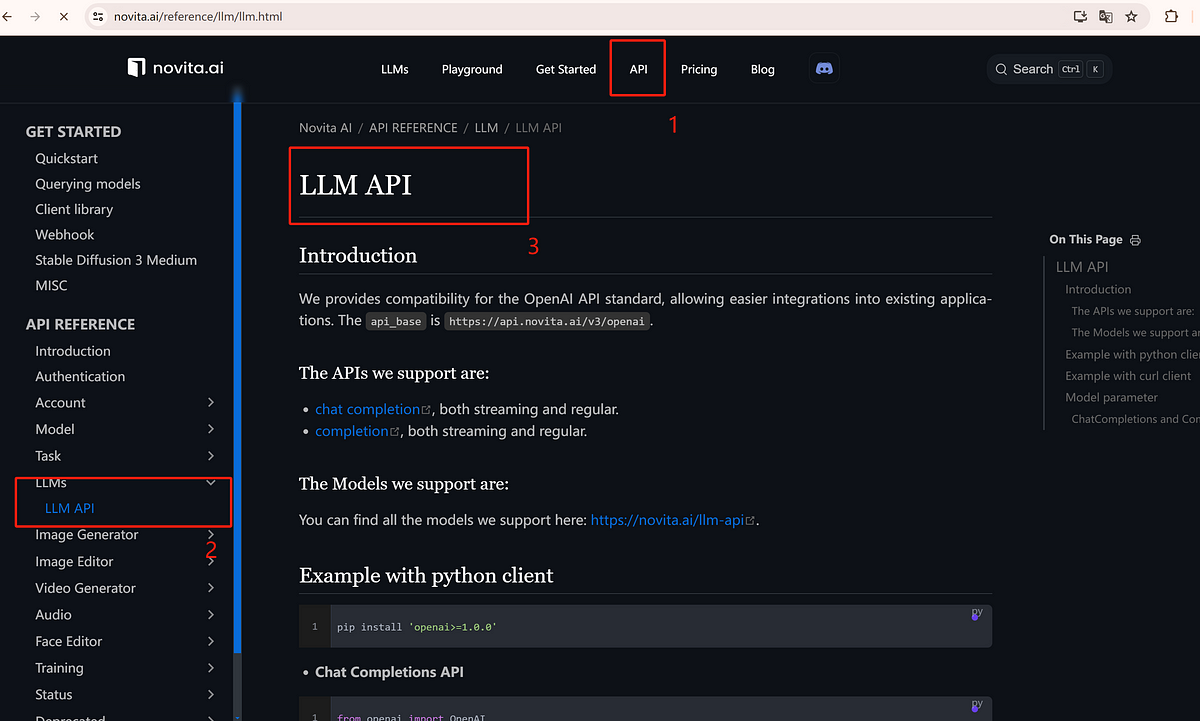
- Step 3: Navigate to API and find the “LLM” under the “LLMs” tab. Install the Novita AI API using the package manager specific to your programming language.
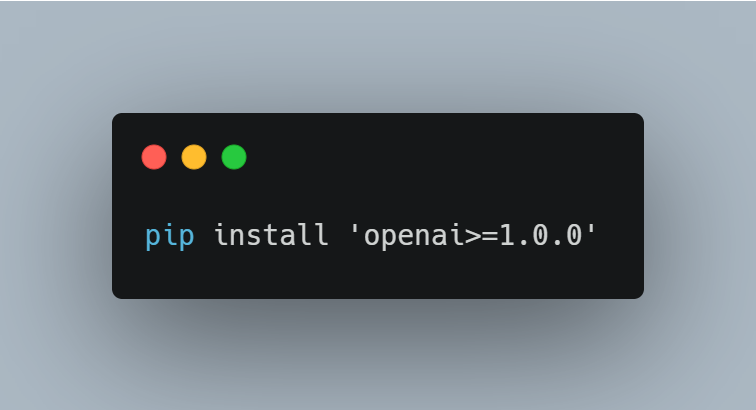
For Python users, this might involve a simple command like:
You can install the Javascript client library with npm, like

- Step 5: After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM.
- Step 6: Adjust parameters like model, messages, prompt, and max tokens to train your new models. You can now use the Novita AI LLM API to perform various NLP tasks.
- Step 7: Thoroughly test the LLM API until it can be fully implemented.
Sample Chat Completions API
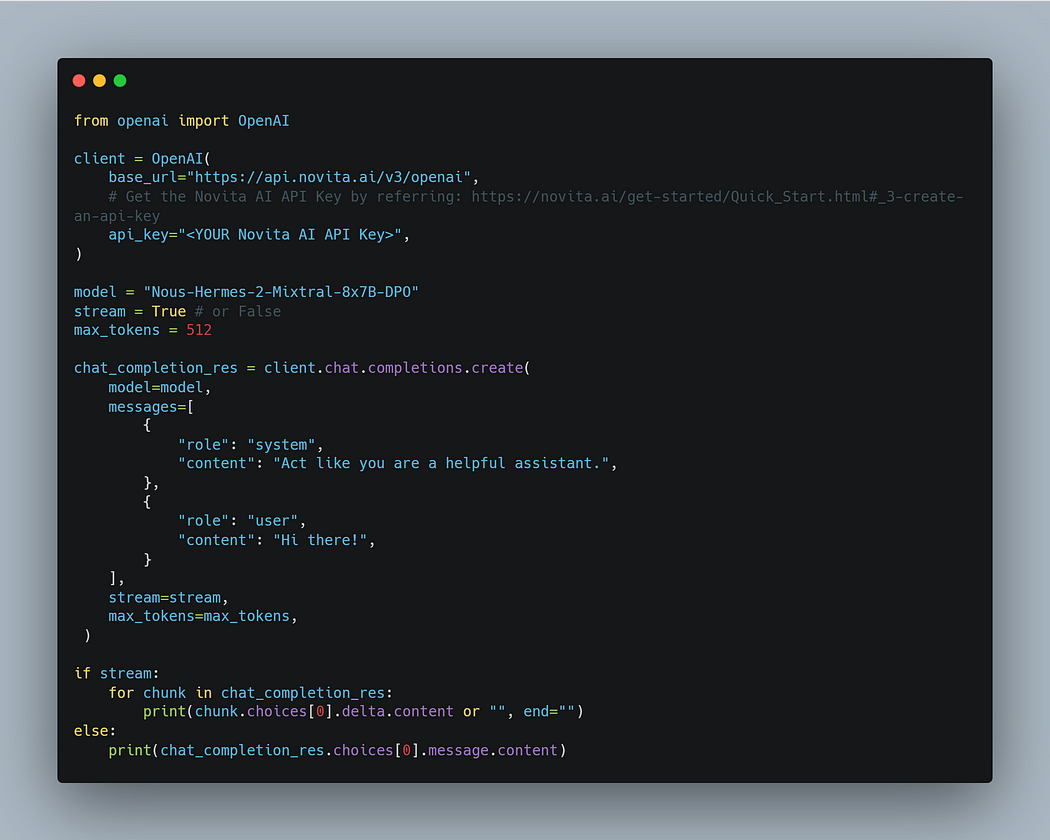
Tips for Faster Integration
To make sure you’re getting the best out of the quickest LLM APIs, here’s what you should do:
- Start by delving into the API documentation to understand it well.
- Use tools like GitHub for easier setup.
- Monitor latency metrics regularly for speed optimization.
- Consider how big transformer models align with your projects.
- Explore quantization methods to maintain speed and accuracy in results.
Future Trends in LLM API Development
Advancements in LLMs are revolutionizing the AI field. Expect faster inference speed, improved efficiency, and the ability to handle complex tasks seamlessly. Incorporating AI models will enhance LLM APIs further. Stay updated on technologies like quantization and transformer architectures for even smarter and quicker API operations.
Innovations to Watch Out For
In the world of LLM APIs, watch out for updates like improved AI skills, smarter inference models, and streamlined processes. Explore advancements in big brain transformer models for personalized responses in AI-powered API enhancements.
The Role of AI in Enhancing API Performance
Using AI can enhance API performance by enabling smarter and faster responses through advanced guessing methods. Integrating AI features improves API efficiency across various domains. Stay updated on this topic by exploring resources like the OpenAI Developer Forum for fresh ideas.
Conclusion
In the world of LLM API setups, being quick is key. If you get a good handle on the basics and really focus on making things run better, you can make everything work more smoothly. Selecting the right setup, utilizing cutting-edge technology, and monitoring usage are key for future updates and growth. Incorporating AI can enhance your API performance further. In the fast-paced world of API creation, innovation mixed with proven methods is key to staying ahead. Embrace this challenge and elevate your API projects to new heights.
Frequently Asked Questions
What is the average response time for top LLM APIs?
The top LLM APIs typically offer response times ranging from milliseconds to about one second, based on setup complexity.
How can developers optimize their own LLM API implementations for speed?
Specify the particular task you require the LLM to execute. Subsequently, explore methods to minimize LLM API expenses and hasten AI introductions: immediate engineering, caching, and local model deployment.
What factors should businesses consider when choosing an LLM API implementation for speed and efficiency?
When setting up an LLM API, consider the technology stack, optimization techniques, and scalable infrastructure for quick and smooth operation. These factors improve response times and overall performance.
Are there any potential challenges or drawbacks to implementing fast LLM APIs?
You may face challenges like data security, quota and rate limit restriction, compatibility with older systems, and managing increased traffic smoothly.
How to get a faster response time?
Developers can speed up LLM API by enhancing algorithms, utilizing smart data structures, caching common data, and optimizing infrastructure and resources. You can also break down your executions into smaller ones.
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.
Recommended Reading