Dynamic allocation of GPU resources for Kubernetes workloads

Currently, to schedule GPU Pods in Kubernetes (k8s), various extension solutions are put into action, including Device Plugin, Extended Resource, scheduler extender, scheduler framework, or developing a new scheduler. These solutions often rely on nodeSelector or nodeAffinity to select nodes that provide specific GPU models. Additionally, to automatically discover the GPU models on each node, it's necessary to deploy Node Feature Discovery (NFD) or GPU Feature Discovery (GFD).
Later on, to standardize the exposure of third-party devices to containers, the new runtime specification CDI (Container Device Interface) was introduced. Of course, CDI only provides a solution on the CRI side.
Fortunately, starting from k8s v1.26, Dynamic Resource Allocation (DRA) is supported, offering a consistent solution for resource requests and allocation on the scheduling side. However, the initial DRA with Control Plane Controller approach had some flaws, which were improved in k8s v1.30 with the introduction of DRA with Structured Parameters, which is the focus of this article.
k8s 1.31 made further changes on this basis, and this article will introduce DRA with Structured Parameters based on the k8s 1.31 version.
(For previous extension solutions, this article will not delve into details; if time permits, I will write another article to introduce them later. )
Now, let's dive directly into the main topic of this article, DRA with Structured Parameters.
DRA with Structured Parameters
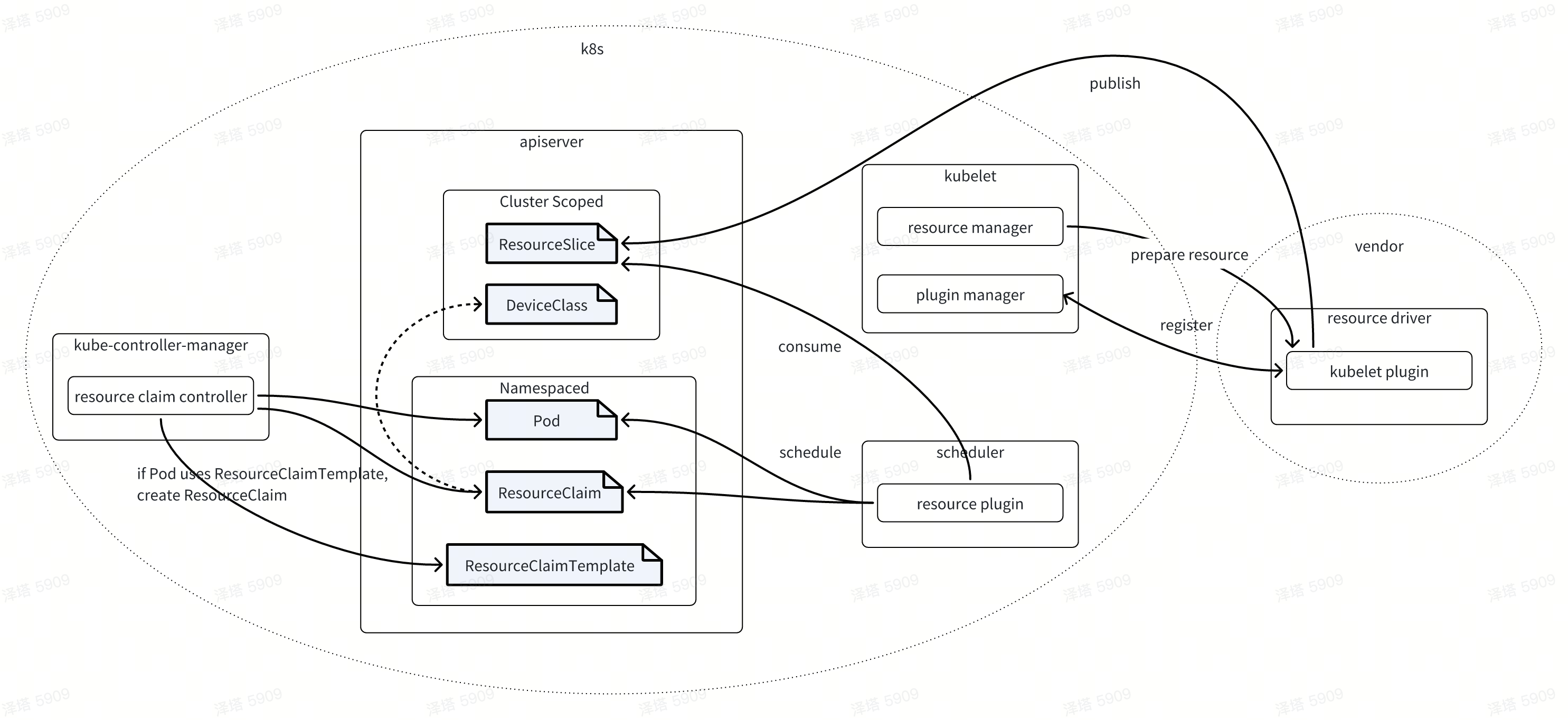
DRA is mainly utilized for the request and sharing of resources between Pods or among multiple containers within a single Pod, encompassing more than just GPU resources. While it is significantly more intricate than the previous Device Plugin approach, the ResourceClaimTemplate/ResourceClaim/DeviceClass trio, akin to PVC/PV/SC, offers flexibility and a comprehensive set of resource definitions that can officially accommodate a variety of heterogeneous resources.
Naturally, users are still required to develop their own resource drivers to handle the preparation and maintenance of these resources.
Key Concepts
ResourceClaim
A ResourceClaim is used for resource access requests. The Scheduler selects available nodes based on the ResourceClaim configured in the Pod.
---
apiVersion: resource.k8s.io/v1alpha3
kind: ResourceClaim
metadata:
name: small-white-cat-claim
spec:
devices:
requests:
- name: req-0
deviceClassName: resource.example.com
selectors:
- cel:
expression: |-
device.attributes["resource-driver.example.com"].color == "white" &&
device.attributes["resource-driver.example.com"].size == "small"ResourceClaimTemplate
ResourceClaimTemplate is used to create ResourceClaims. It is managed by the kube-controller-manager's resourceclaim controller. Here is the code snippet for creating it:
func (ec *Controller) handleClaim(ctx context.Context, pod *v1.Pod, podClaim v1.PodResourceClaim, newPodClaims *map[string]string) error {
claimName, mustCheckOwner, err := resourceclaim.Name(pod, &podClaim)
switch {
case errors.Is(err, resourceclaim.ErrClaimNotFound):
......
}
// Before we create a new ResourceClaim, check if there is an orphaned one.
// This covers the case that the controller has created it, but then fails
// before it can update the pod status.
claim, err := ec.findPodResourceClaim(pod, podClaim)
if err != nil {
return fmt.Errorf("finding ResourceClaim for claim %s in pod %s/%s failed: %v", podClaim.Name, pod.Namespace, pod.Name, err)
}
if claim == nil {
template, err := ec.templateLister.ResourceClaimTemplates(pod.Namespace).Get(*templateName)
if err != nil {
return fmt.Errorf("resource claim template %q: %v", *templateName, err)
}
// Create the ResourceClaim with pod as owner, with a generated name that uses
// <pod>-<claim name> as base.
isTrue := true
annotations := template.Spec.ObjectMeta.Annotations
if annotations == nil {
annotations = make(map[string]string)
}
annotations[podResourceClaimAnnotation] = podClaim.Name
generateName := pod.Name + "-" + podClaim.Name + "-"
maxBaseLen := 57 // Leave space for hyphen and 5 random characters in a name with 63 characters.
if len(generateName) > maxBaseLen {
// We could leave truncation to the apiserver, but as
// it removes at the end, we would loose everything
// from the pod claim name when the pod name is long.
// We can do better and truncate both strings,
// proportional to their length.
generateName = pod.Name[0:len(pod.Name)*maxBaseLen/len(generateName)] +
"-" +
podClaim.Name[0:len(podClaim.Name)*maxBaseLen/len(generateName)]
}
claim = &resourceapi.ResourceClaim{
ObjectMeta: metav1.ObjectMeta{
GenerateName: generateName,
OwnerReferences: []metav1.OwnerReference{
{
APIVersion: "v1",
Kind: "Pod",
Name: pod.Name,
UID: pod.UID,
Controller: &isTrue,
BlockOwnerDeletion: &isTrue,
},
},
Annotations: annotations,
Labels: template.Spec.ObjectMeta.Labels,
},
Spec: template.Spec.Spec,
}
metrics.ResourceClaimCreateAttempts.Inc()
claimName := claim.Name
claim, err = ec.kubeClient.ResourceV1alpha3().ResourceClaims(pod.Namespace).Create(ctx, claim, metav1.CreateOptions{})
if err != nil {
metrics.ResourceClaimCreateFailures.Inc()
return fmt.Errorf("create ResourceClaim %s: %v", claimName, err)
}
logger.V(4).Info("Created ResourceClaim", "claim", klog.KObj(claim), "pod", klog.KObj(pod))
ec.claimCache.Mutation(claim)
}
Why Introduce ResourceClaimTemplate?
Consider the following example within a Pod Spec: the resourceClaims field allows you to reference either a ResourceClaim or a ResourceClaimTemplate, but not both—they are mutually exclusive. When you reference a ResourceClaim via resourceClaimName, all Pods that utilize this Pod Spec (such as those in a Deployment or StatefulSet) share the same ResourceClaim instance. This instance corresponds to the ResourceClaim with the name specified by resourceClaimName within the same namespace as the Pod.
Conversely, when you reference a ResourceClaimTemplate via resourceClaimTemplateName, each Pod gets its own distinct ResourceClaim instance. This is because the kube-controller-manager's resourceclaim controller automatically generates a separate ResourceClaim for each Pod.
Here's a simplified Pod Spec example:
–--
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
containers:
- name: container0
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-0
- name: container1
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-1
resourceClaims:
- name: cat-0
resourceClaimName: small-white-cat-claim
- name: cat-1
resourceClaimTemplateName: large-black-cat-claim-templateDeviceClass
The DeviceClass encompasses the configuration and selector for a Device, as defined below.
// +genclient
// +genclient:nonNamespaced
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// +k8s:prerelease-lifecycle-gen:introduced=1.31
// DeviceClass is a vendor- or admin-provided resource that contains
// device configuration and selectors. It can be referenced in
// the device requests of a claim to apply these presets.
// Cluster scoped.
//
// This is an alpha type and requires enabling the DynamicResourceAllocation
// feature gate.
type DeviceClass struct {
metav1.TypeMeta `json:",inline"`
// Standard object metadata
// +optional
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
// Spec defines what can be allocated and how to configure it.
//
// This is mutable. Consumers have to be prepared for classes changing
// at any time, either because they get updated or replaced. Claim
// allocations are done once based on whatever was set in classes at
// the time of allocation.
//
// Changing the spec automatically increments the metadata.generation number.
Spec DeviceClassSpec `json:"spec" protobuf:"bytes,2,name=spec"`
}
// DeviceClassSpec is used in a [DeviceClass] to define what can be allocated
// and how to configure it.
type DeviceClassSpec struct {
// Each selector must be satisfied by a device which is claimed via this class.
//
// +optional
// +listType=atomic
Selectors []DeviceSelector `json:"selectors,omitempty" protobuf:"bytes,1,opt,name=selectors"`
// Config defines configuration parameters that apply to each device that is claimed via this class.
// Some classses may potentially be satisfied by multiple drivers, so each instance of a vendor
// configuration applies to exactly one driver.
//
// They are passed to the driver, but are not considered while allocating the claim.
//
// +optional
// +listType=atomic
Config []DeviceClassConfiguration `json:"config,omitempty" protobuf:"bytes,2,opt,name=config"`
// Only nodes matching the selector will be considered by the scheduler
// when trying to find a Node that fits a Pod when that Pod uses
// a claim that has not been allocated yet *and* that claim
// gets allocated through a control plane controller. It is ignored
// when the claim does not use a control plane controller
// for allocation.
//
// Setting this field is optional. If unset, all Nodes are candidates.
//
// This is an alpha field and requires enabling the DRAControlPlaneController
// feature gate.
//
// +optional
// +featureGate=DRAControlPlaneController
SuitableNodes *v1.NodeSelector `json:"suitableNodes,omitempty" protobuf:"bytes,3,opt,name=suitableNodes"`
}When users create a ResourceClaim or a ResourceClaimTemplate, they need to specify the corresponding DeviceClass through the deviceClassName. The Scheduler assigns nodes to Pods by matching devices using the DeviceClass's selector, and finally, it populates the Device configuration from the DeviceClass into the Status of the ResourceClaim instance.
if requestData.class != nil {
match, err := alloc.selectorsMatch(r, device, deviceID, requestData.class, requestData.class.Spec.Selectors)
if err != nil {
return false, err
}
if !match {
alloc.deviceMatchesRequest[matchKey] = false
return false, nil
}
}
request := &alloc.claimsToAllocate[r.claimIndex].Spec.Devices.Requests[r.requestIndex]
match, err := alloc.selectorsMatch(r, device, deviceID, nil, request.Selectors)
for claimIndex, allocationResult := range alloc.result {
claim := alloc.claimsToAllocate[claimIndex]
// Populate configs.
for requestIndex := range claim.Spec.Devices.Requests {
class := alloc.requestData[requestIndices{claimIndex: claimIndex, requestIndex: requestIndex}].class
if class != nil {
for _, config := range class.Spec.Config {
allocationResult.Devices.Config = append(allocationResult.Devices.Config, resourceapi.DeviceAllocationConfiguration{
Source: resourceapi.AllocationConfigSourceClass,
Requests: nil, // All of them...
DeviceConfiguration: config.DeviceConfiguration,
})
}
}
}Code path:pkg\scheduler\framework\plugins\dynamicresources\dynamicresources.go
func (pl *dynamicResources) bindClaim(ctx context.Context, state *stateData, index int, pod *v1.Pod, nodeName string) (patchedClaim *resourceapi.ResourceClaim, finalErr error) {
if allocation != nil {
if claim.Status.Allocation != nil {
return fmt.Errorf("claim %s got allocated elsewhere in the meantime", klog.KObj(claim))
}
......
claim.Status.Allocation = allocation
}
claim.Status.ReservedFor = append(claim.Status.ReservedFor, resourceapi.ResourceClaimConsumerReference{Resource: "pods", Name: pod.Name, UID: pod.UID})
updatedClaim, err := pl.clientset.ResourceV1alpha3().ResourceClaims(claim.Namespace).UpdateStatus(ctx, claim, metav1.UpdateOptions{})ResourceSlice
Kubernetes 1.30 introduces ResourceSlice as a major improvement feature for DRA with structured parameters. The creation and maintenance of ResourceSlice instances are determined by kubelet and resource drivers provided by vendors. Additionally, the Scheduler determines the scheduling node based on ResourceClaim and ResourceSlice during Pod scheduling, effectively taking on the responsibility of resource allocation.
The kubelet is primarily responsible for automatically clearing the ResourceSlice on the node during startup, restart, or when a kubelet plugin is removed.
// NewPluginHandler returns new registration handler.
//
// Must only be called once per process because it manages global state.
// If a kubeClient is provided, then it synchronizes ResourceSlices
// with the resource information provided by plugins.
func NewRegistrationHandler(kubeClient kubernetes.Interface, getNode func() (*v1.Node, error)) *RegistrationHandler {
handler := &RegistrationHandler{
// The context and thus logger should come from the caller.
backgroundCtx: klog.NewContext(context.TODO(), klog.LoggerWithName(klog.TODO(), "DRA registration handler")),
kubeClient: kubeClient,
getNode: getNode,
}
// When kubelet starts up, no DRA driver has registered yet. None of
// the drivers are usable until they come back, which might not happen
// at all. Therefore it is better to not advertise any local resources
// because pods could get stuck on the node waiting for the driver
// to start up.
//
// This has to run in the background.
go handler.wipeResourceSlices("")
return handler
}
// DeRegisterPlugin is called when a plugin has removed its socket,
// signaling it is no longer available.
func (h *RegistrationHandler) DeRegisterPlugin(pluginName string) {
if p := draPlugins.delete(pluginName); p != nil {
logger := klog.FromContext(p.backgroundCtx)
logger.V(3).Info("Deregister DRA plugin", "endpoint", p.endpoint)
// Clean up the ResourceSlices for the deleted Plugin since it
// may have died without doing so itself and might never come
// back.
go h.wipeResourceSlices(pluginName)
return
}
logger := klog.FromContext(h.backgroundCtx)
logger.V(3).Info("Deregister DRA plugin not necessary, was already removed")
}Resource Driver, aka DRA driver
Resource Driver, also known as the DRA driver, needs to be developed by vendors or users themselves. It is primarily responsible for publishing ResourceSlice resources and, as a kubelet plugin, handles resource preparation requests triggered by kubelet. Ultimately, resources are utilized through CDI.
Below is the relevant code for the kubelet's initiation of resource preparation requests.
// PrepareResources attempts to prepare all of the required resources
// for the input container, issue NodePrepareResources rpc requests
// for each new resource requirement, process their responses and update the cached
// containerResources on success.
func (m *ManagerImpl) PrepareResources(pod *v1.Pod) error {
batches := make(map[string][]*drapb.Claim)
resourceClaims := make(map[types.UID]*resourceapi.ResourceClaim)
for i := range pod.Spec.ResourceClaims {
podClaim := &pod.Spec.ResourceClaims[i]
klog.V(3).InfoS("Processing resource", "pod", klog.KObj(pod), "podClaim", podClaim.Name)
claimName, mustCheckOwner, err := resourceclaim.Name(pod, podClaim)
......
resourceClaim, err := m.kubeClient.ResourceV1alpha3().ResourceClaims(pod.Namespace).Get(
context.TODO(),
*claimName,
metav1.GetOptions{})
......
// Atomically perform some operations on the claimInfo cache.
err = m.cache.withLock(func() error {
claimInfo, exists := m.cache.get(resourceClaim.Name, resourceClaim.Namespace)
......
// Loop through all drivers and prepare for calling NodePrepareResources.
claim := &drapb.Claim{
Namespace: claimInfo.Namespace,
UID: string(claimInfo.ClaimUID),
Name: claimInfo.ClaimName,
}
for driverName := range claimInfo.DriverState {
batches[driverName] = append(batches[driverName], claim)
}
return nil
})
if err != nil {
return fmt.Errorf("locked cache operation: %w", err)
}
}
// Call NodePrepareResources for all claims in each batch.
// If there is any error, processing gets aborted.
// We could try to continue, but that would make the code more complex.
for driverName, claims := range batches {
// Call NodePrepareResources RPC for all resource handles.
client, err := dra.NewDRAPluginClient(driverName)
if err != nil {
return fmt.Errorf("failed to get gRPC client for driver %s: %w", driverName, err)
}
response, err := client.NodePrepareResources(context.Background(), &drapb.NodePrepareResourcesRequest{Claims: claims})
......
}
Flaws in the DRA with Control Plane Controller Approach
The downside of the DRA with Control Plane Controller approach is that during Pod scheduling, the scheduler creates a PodSchedulingContext, and the resource driver allocates resources. Since Pod scheduling is sequential, it inevitably increases the delay for other Pods waiting in the queue for scheduling.
To optimize this, structured parameters were introduced, allowing the resource driver to proactively report ResourceSlices, enabling the scheduler to make scheduling decisions directly from the ResourceSlices during Pod scheduling.
Summary
Currently, AI training and inference can be scheduled by Kubernetes like regular CPU containers, but this is achieved through existing Kubernetes extension mechanisms without a unified solution. Moreover, the more complex the GPU resource allocation scenarios, the more complex the functions that users need to implement themselves. Kubernetes DRA provides a unified solution where vendors or users only need to implement the resource driver and provide DriverClass instance configurations, and it is officially supported, so there's no need to worry about a GPU scheduling open-source solution ceasing maintenance.
DRA is not yet mature and is continuously being improved. Let's keep an eye on the latest developments in the community.