Diving Into dolphin-2.1-Mistral-7B and Alternative LLMs

Introduction
Have you ever wondered what an AI could achieve without the constraints of censorship? How about an AI model that’s not only a conversationalist, but also an artist, a writer, and a researcher? Welcome to the realm of the Dolphin-2.1-mistral-7B model, an LLM that stands as a testament to the power of open-source innovation and the potential of AI to excel in various domains. In this blog, we’ll explore the Dolphin-2.1-mistral-7B model, its nature, and the practical applications it opens up for developers. Let’s embark on this journey!
Understanding dolphin-2.1-mistral-7B Model
Overview
Sponsored by a16z and built on the principles of open-source collaboration by Cognitive Computations, this model stands out for its nature, allowing for a more flexible and creative AI interaction. With its Apache-2.0 license, the Dolphin-2.1-mistral-7B model is accessible for both commercial and non-commercial endeavors, catering to a diverse user base.
Foundation and Inspiration
The Dolphin-2.1-mistral-7B model is an open-source interpretation of Microsoft’s Orca, reflecting a commitment to innovation and community-driven development. The model’s architecture is inspired by the latest advancements in transformer-based AI, ensuring state-of-the-art performance and adaptability.
Training and Dataset
The training process of Dolphin-2.1-mistral-7B involved a meticulous 48-hour regimen on high-performance A100 GPUs. The dataset for the Dolphin-2.1-mistral-7B model is a modified version of the Dolphin dataset, which is an open-source implementation of Microsoft’s Orca dataset. It has been enhanced and refined to improve the model’s performance and versatility:
- Uncensoring: The dataset was filtered to remove any inherent biases or alignment constraints, allowing the model to respond more freely to a wide range of prompts.
- Deduplication: The process of removing duplicate entries was undertaken to ensure the diversity and uniqueness of the training data.
- Cleaning: The dataset underwent a thorough cleaning process to remove any noise or irrelevant data that could affect the model’s learning efficiency.
- Quality Enhancement: Efforts were made to improve the overall quality of the dataset, focusing on the relevance and accuracy of the data points.
- Inclusion of External Datasets: To further enrich the dataset, the Airoboros dataset by Jon Durbin was integrated. This addition is aimed at boosting the model’s creativity and response variety.
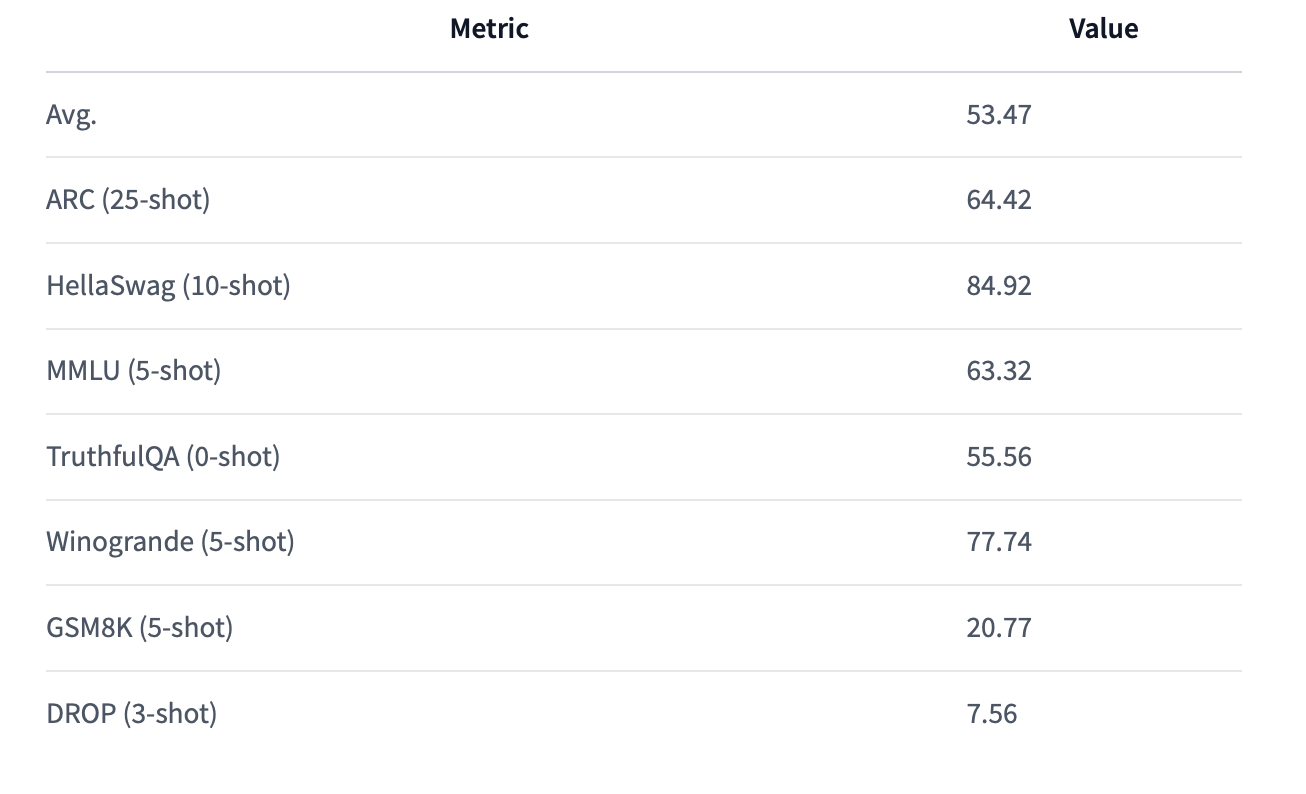
Performance Metrics
The model’s capabilities are underscored by its performance metrics, which reflect its proficiency across different tasks and evaluations, such as the ARC, HellaSwag, MMLU, and others, demonstrating its well-rounded competence.
Key Features of dolphin-2.1-mistral-7B
Compliance and Ethics
One of the core design principles of the Dolphin-2.1-mistral-7B model is its nature. While this allows for greater flexibility, it also necessitates that users implement their own layers of alignment to ensure ethical use, particularly when exposing the model as a service.
Enhanced Compliance
The nature of the Dolphin-2.1-mistral-7B model means it can respond to a broader spectrum of prompts without the inherent biases present in other AI models. This feature, while powerful, comes with the responsibility of ethical stewardship.
Customizability
With its Apache-2.0 license, the Dolphin-2.1-mistral-7B model can be customized and integrated into various systems and applications, making it a versatile tool for developers and businesses alike.
ChatML Prompt Format
The Dolphin-2.1-mistral-7B model employs a ChatML prompt format, streamlining interactions and making it easier for users to direct the AI in specific roles or tasks, enhancing user experience and model utility.
Exploring LLMs
Making an LLM involves removing or reducing the constraints that prevent it from generating certain types of content. The process typically includes the following steps:
Understanding Alignment
Recognize that most models are aligned to avoid generating harmful or controversial content. This alignment is usually a result of the training data, which may be influenced by the biases and guidelines of the organization that created it.
Data Collection
Obtain a dataset that has been used to finetune the model. This dataset contains the input-output pairs that the model has been trained on.
Filtering the Dataset
Analyze the dataset to identify instances where the model’s responses are restricted due to alignment. These instances might include refusals to answer questions or responses that are biased towards certain viewpoints.
Removing Refusals
Edit the dataset to remove or modify the responses that exhibit refusal or bias. The goal is to create a version of the dataset that does not pass on these constraints to the model.
Retraining the Model
Use the filtered dataset to retrain the model. This step involves feeding the modified dataset back into the model so that it learns from the new, less constrained data.
Adjusting Training Parameters
During the retraining process, you may need to adjust various parameters such as learning rate, batch size, and epochs to optimize the model’s performance without censorship.
Testing and Iteration
After retraining, test the model to ensure it behaves as expected — generating responses without censorship while still maintaining the quality and coherence of its outputs. You may need to iterate on the dataset filtering and retraining process to achieve the desired results.
Deployment
Once you are satisfied with the model’s behavior, deploy it in your application or service, ensuring that it is used responsibly and ethically.
Monitoring and Updates
Continuously monitor the model’s performance and make updates as necessary to maintain its status and address any emerging issues.
Ethical Considerations
Throughout this process, it’s crucial to consider the ethical implications of creating and using an model. Ensure that the model’s use aligns with your values and the expectations of your users.
Meanings of LLM Like dolphin-2.1-mistral-7B

Models matter for several reasons, as outlined in Eric Hartford’s (one of the leading team members of Cognitive Computations) blog post Models. Here are the key points that explain their significance:
Cultural Diversity
The world is not homogenous, and different cultures, political ideologies, and belief systems have varied perspectives. Models allow for a diversity of viewpoints, rather than being constrained by a single cultural or ideological alignment, typically that of the training data’s origin.
Freedom of Expression
Writers, artists, and content creators may need to explore dark or controversial themes in their work. Censored models might refuse to engage with such content, limiting creative freedom. Models do not impose restrictions based on the ethical or moral standards of the training data.
Intellectual Curiosity
People have a natural curiosity to understand how things work, even if those things are potentially dangerous. For instance, someone might want to learn about the chemistry behind explosives purely out of interest, not with the intent to create harm. Censored models might prevent this kind of inquiry, while models allow for it.
User Autonomy
Users should have control over their own devices and the software running on them. Just as a person expects a toaster or a car to perform as they wish, they should be able to ask an AI model questions without the model refusing to answer based on its own alignment.
Composability
To create AI systems that can adapt to various use cases and constraints, you may need to start with an unaligned model and then apply specific alignments on top. This allows for a more flexible and customizable approach to AI development.
Scientific Research
In some cases, censorship can hinder scientific progress. Researchers might need access to a wide range of information, including that which is sensitive or controversial, to advance their work.
Legal and Ethical Protection
While alignment can protect companies from legal and public relations issues, it can also be seen as a form of self-censorship that might not be desirable in all contexts.
Transparency and Control
Models can provide more transparency into how AI models work, as their responses are not filtered through an alignment layer. This can be valuable for understanding and debugging model behavior.
In summary, Models matter because they support a broader range of human activities, from creative endeavors to intellectual exploration, and they uphold principles of user autonomy and flexibility in AI applications. However, it’s important to note that with the freedom provided by Models comes the responsibility to use them ethically and safely.
Setting Up dolphin-2.1-mistral-7B
Notice: All required files can be found on Huggingface under TheBloke. Familiarize yourself with the following process to effectively manage these files.
Step 1: Choose Your Quantized Model File
Decide which quantized version of the Dolphin 2.1 Mistral 7B model you want to download based on the trade-off between quality and size. For a balanced approach, the Q4_K_M.gguf or Q5_K_M.gguf files are recommended.
Step 2: Install Required Tools
You’ll need Python and git installed on your system. If you don’t have them, download and install them:
- Python: Install from python.org.
- Git: Install from git-scm.com.
Step 3: Install Huggingface Hub CLI
This tool will help you download the model files efficiently.
pip3 install huggingface-hub
Step 4: Download the Model
Use the Huggingface Hub CLI to download your chosen model file to the current directory.
huggingface-cli download TheBloke/dolphin-2.1-mistral-7B-GGUF dolphin-2.1-mistral-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks FalseStep 5: Choose a Client or Library
Select a client or library that supports GGUF to interact with the model. Some popular options include:
- llama.cpp: Offers a command-line interface and server option.
- text-generation-webui: A web UI with many features and extensions.
- ctransformers: A Python library for using models in Python code.
Step 6: Install the Client or Library
For example, if you choose to use ctransformers, install it with GPU support if you have a compatible system:
pip install ctransformers[cuda]Step 7: Set Up the Environment
If you’re using a command-line tool like llama.cpp, make sure it's compatible with the GGUF format and download it if necessary.
Step 8: Run the Model
Using the chosen client or library, load the model and start generating text. Here’s an example using ctransformers:
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU (set to 0 if no GPU)
llm = AutoModelForCausalLM.from_pretrained("TheBloke/dolphin-2.1-mistral-7B-GGUF", model_file="dolphin-2.1-mistral-7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
# Generate text
print(llm("AI is going to"))Step 9: Interact with the Model
Now that the model is set up, you can interact with it by providing prompts and receiving responses.
Step 10: Advanced Usage
Explore advanced features of the client or library you’re using, such as chat-style interactions, custom prompt templates, and more.
Additional Tips:
- Always check the documentation of the client or library you’re using for specific instructions and additional parameters.
- If you encounter any issues, refer to the community forums or GitHub issues for the respective tools for troubleshooting.
- Remember to manage your resources, especially if you’re using GPU acceleration.
If you want more information about setting up dolphin-2.1-mistral-7B, visit TheBloke on Huggingface.
Tips for Integrating dolphin-2.1-mistral-7B with Other Platforms
1. Embrace the Nature
Since Dolphin design a custom alignment layer if your application requires ethical constraints or content moderation.
2. Choose Appropriate Quantization
Select a quantized model file that matches your application’s need for quality versus performance. The range from 2-bit to 8-bit gives you flexibility based on the balance you need.
3. Utilize ChatML Prompt Format
Leverage the ChatML format to create a structured interaction model between users and the AI, which Dolphin is designed to work with.
4. Ensure System Compatibility
Check that your platform can handle the Dolphin model’s system requirements, considering the RAM and GPU specifications for the chosen quantization.
5. Optimize for Performance
Make the most of GPU acceleration features, which are crucial for handling the computational demands of Dolphin, especially for larger quantizations.
6. Safe and Responsible Use
Implement filters or moderation tools to manage the responses, ensuring they align with your platform’s ethical standards.
7. Seamless Model Loading
Use libraries like ctransformers for easy model loading, which is essential for maintaining the Dolphin model's performance.
8. User Interface Design
Design the UI to help users craft effective ChatML prompts, taking advantage of Dolphin’s strength in structured conversations.
9. Ethical Considerations
Be transparent with users about the nature of Dolphin and any content filtering applied within your platform.
10. Comprehensive Testing
Test the integration across various scenarios to ensure that the responses are handled appropriately within your application context.
11. Documentation and Best Practices
Provide documentation that highlights best practices for prompt construction and the ethical use of the model.
12. Monitor and Iterate
Continuously monitor the model’s performance and make adjustments as needed to accommodate the computational demands of Dolphin.
13. Update Regularly
Keep the model and its associated software up to date to benefit from the latest improvements and security patches.
Practical Applications of LLMs for Developers

AI Companion Chat
LLMs can be employed to create AI companion chat applications that offer a more open and flexible conversational experience. Unlike their censored counterparts, these models can engage in discussions on a wider range of topics, including those that are controversial or culturally sensitive. Developers can leverage this feature to build companions that provide:
- Culturally Diverse Interactions: Chatbots that can adapt to various cultural contexts and user preferences.
- Holistic User Experience: Conversations that are less restricted, allowing users to explore a multitude of subjects freely.
- Customizable Content Filters: The ability to implement custom filters based on user needs or specific application requirements.
AI Chat
For developers looking to create chat applications that push the boundaries of traditional conversational AI, LLMs offer unique opportunities:
- Creative Content Development: Support for generating narratives or dialogues that involve mature or dark themes, which can be essential for certain types of storytelling.
- Research and Exploration: Facilitating access to information that might be censored elsewhere, thus supporting intellectual curiosity and research.
- Transparency in Interactions: Providing users with the assurance that the AI is not withholding information due to built-in constraints.
AI Novel Generation
LLMs can be particularly useful for developers interested in automated creative writing, such as generating novels or stories:
- Unrestricted Creative Output: The ability to produce content that includes themes and elements that might be restricted by censored models.
- Diverse Genre Exploration: From fantasy to crime thrillers, Models can handle a variety of genres that may involve sensitive or explicit material.
- Character Development: Support for creating complex characters with intricate backstories that may involve unethical or controversial actions.
AI Summarization
While summarization might seem straightforward, LLMs can offer a different perspective:
- Comprehensive Summaries: Summarizing content that might be considered sensitive or controversial by censored models, ensuring that all viewpoints are represented.
- Research and Analysis Tools: Providing developers with tools to create summaries of research materials or documents that may contain a wide range of topics.
- Customizable Summarization Rules: Allowing developers to set their own rules for what should or should not be included in a summary, based on the application’s needs.
Alternative LLM APIs
Novita AI offers developers a range of LLM API options, featuring models. With LLM APIs, several lines of code will save you from all the trouble of setting up the model your self. What’s more, Novita AI LLM API includes capabilities for hyperparameter adjustments and customizable system prompts, tailored to meet individual needs.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>", # Replace with your actual API key
)
model = "nousresearch/nous-hermes-llama2-13b"dolphin-mixtral-8x22b on Novita AI
Dolphin 2.9 is designed for instruction following, conversational, and coding. This model is a finetune of Mixtral 8x22B Instruct. It features a 64k context length and was fine-tuned with a 16k sequence length using ChatML templates. The model is stripped of alignment and bias. It requires an external alignment layer for ethical use.

sao10k/l3–70b-euryale-v2.1 on Novita AI
The llama3 model is a powerhouse of creativity, excelling in both roleplay and story writing. It offers a liberating experience during roleplays, free from any restrictions. This model stands out for its immense creativity, boasting a vast array of unique ideas and plots, truly a treasure trove for those seeking originality. Its unrestricted nature during roleplays allows for the full breadth of imagination to unfold, akin to an enhanced, big-brained version of Stheno. Perfect for creative minds seeking a boundless platform for their imaginative expressions, the llama3 model is an ideal choice.

Conclusion
In conclusion, the Dolphin-2.1-mistral-7B model represents a significant leap forward in AI technology, driven by its nature and open-source foundation. Sponsored by a16z and developed by Cognitive Computations, it builds upon the principles of open collaboration and community-driven innovation. From its meticulous training regimen on high-performance GPUs to its integration of diverse datasets, this model excels in performance and adaptability. Key features such as compliance with Apache-2.0 licensing, ChatML prompt format, and its ability to support a wide range of applications highlight its versatility and user-centric design.
As developers and users embrace the potential of LLMs like Dolphin-2.1-mistral-7B, they unlock new possibilities in creative expression, intellectual exploration, and user autonomy. While the model offers unprecedented freedom, it also underscores the importance of ethical stewardship and responsible use. By integrating Dolphin-2.1-mistral-7B into various platforms and applications, developers can empower users with AI interactions that foster innovation and inclusivity in the digital age.
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.