Deep Dive into Mixture of Experts for LLM Models

Key Highlights
- Evolution of MoE in AI: Explore how MoE has evolved from its inception in 1991 to become a cornerstone in enhancing machine learning capabilities beyond traditional neural networks.
- Core Components of MoE Architecture: Delve into the experts, gating mechanisms, and routing algorithms that define MoE models, enabling efficient handling of complex data and tasks.
- Advancements in LLMs with MoE: Discover how MoE empowers Large Language Models (LLMs) to handle diverse linguistic patterns and improve computational efficiency.
- Practical Applications: Explore real-world applications across natural language processing (NLP), computer vision, and multimodal learning, showcasing MoE’s versatility and performance enhancements.
- Integration with MoE LLM API: Learn about seamless integration opportunities with MoE LLM API, facilitating easier adoption and customization of advanced MoE capabilities in AI-driven applications.
Introduction
What makes Mixture of Experts (MoE) LLM a game-changer in AI? How does this architecture enhance machine learning beyond traditional neural networks? These questions are pivotal as we delve into the evolution and core components of MoE models.
Originating from pioneering work in 1991, MoE introduces a collaborative framework where specialized networks — experts — pool their strengths to tackle complex tasks. This blog explores how MoE models optimize computational efficiency, handle diverse datasets, and pave the way for more nuanced AI applications. Join us as we unravel the intricacies and potential of MoE in shaping the future of artificial intelligence.
The Evolution of MoE in Machine Learning
The Mixture of Experts (MoE) is like a super-smart system in the world of AI that brings together several specialized networks to boost how well machines can learn and perform tasks.
Back in the early days of machine learning, around 1991, a guy named Robert A. Jacobs and his team came up with something called Mixture of Experts (MoE) in their study “Adaptive Mixtures of Local Experts.” This idea was pretty new back then and it helped kickstart MoE as a way to do machine learning.

At that point, artificial neural networks were all the rage for figuring out complicated stuff. But these researchers thought that just one neural network might not cut it for really tricky problems. So they suggested using what they called adaptive mixtures of local experts instead. In this setup, you have several specialists working together on tough issues. Each specialist knows a lot about a certain part of the problem and adds their two cents to come up with an answer.
This groundbreaking work on MoE opened doors for more research into making machine learning even better at dealing with complex information and big data challenges over time. The growth of Moe in the field has been key to boosting how well models perform and tackling hard tasks head-on.
Core Components of MoE Architecture
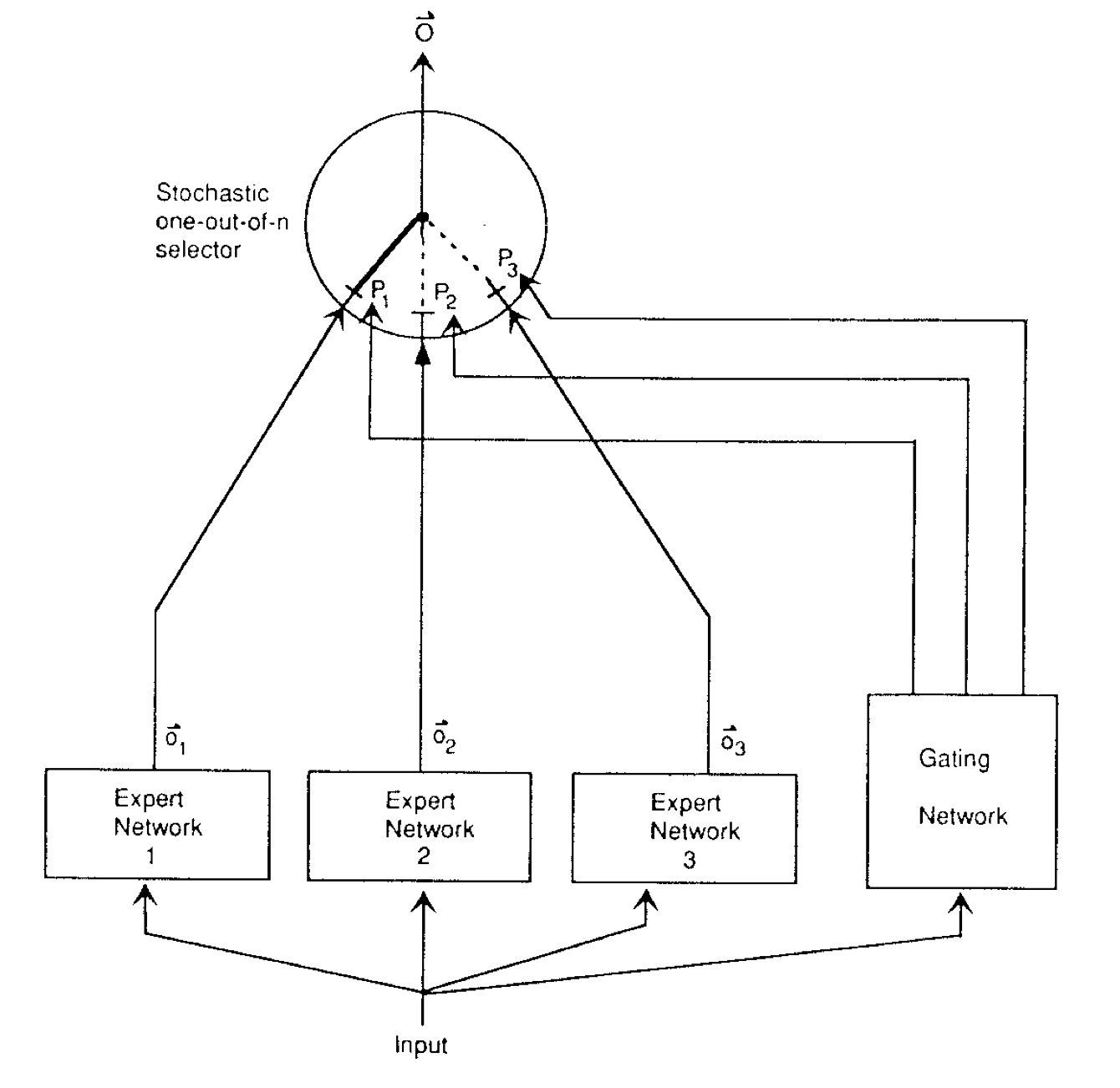
Experts
At the heart of MoE models are the “expert” subnetworks. These experts are independent modules within the larger neural network, each capable of processing input data. The concept is that different experts specialize in different aspects of the input data, allowing the model to leverage specialized knowledge effectively.
Gating Mechanism
The gating mechanism is a critical component that directs the input to the appropriate expert networks. It operates based on a set of gating values that determine the engagement of each expert. The gating mechanism can be implemented as a dense or sparse structure, with the latter being more computationally efficient due to its selective activation of a subset of experts.
Routing Algorithms
In sparse MoE models, routing algorithms play a pivotal role in deciding which experts are activated for a given input. These algorithms can range from simple to complex, aiming to balance model accuracy and computational efficiency. The choice of routing algorithm can significantly influence the model’s performance and inference speed.
Closer Into the Architecture of Moe
Structural Configurations
Dense vs. Sparse MoE
Dense MoE activates all expert networks during each iteration, which can lead to higher accuracy but increased computational overhead. In contrast, sparse MoE activates only a selected subset of experts, enhancing computational efficiency while maintaining competitive performance.
Soft MoE
Soft MoE is a fully differentiable approach that merges the outputs of all experts with gating-weighted averages. This method avoids the discrete expert selection and balances computational demands without sacrificing the model’s capacity.
System Design Considerations
Computation Efficiency
MoE models introduce challenges related to computational efficiency due to their dynamic and sparse nature. Strategies such as optimized gating mechanisms, expert capacity adjustments, and dynamic expert placement are employed to address load imbalances and synchronization overheads.
Communication Overhead
The need for efficient communication during model training is critical, especially as MoE models scale. Hierarchical communication strategies and topology-aware routing are used to reduce inter-node communication burdens and leverage high-bandwidth connections.
Storage Optimizations
The increasing parameters of MoE models pose challenges for memory capacity. Solutions like selective parameter retention and prefetching techniques are implemented to manage memory constraints effectively.
Advancements of Mixture of Experts LLM
MoE has enabled LLMs to expand their capacity by incorporating a multitude of expert subnetworks. This allows the model to handle more complex patterns and relationships within the data.
Subtlety in Expertise
- Fine-Grained Specialization: Each expert within an MoE LLM model can develop specialized knowledge, contributing to the overall model’s understanding of diverse topics.
Improved Computational Efficiency
- Sparse Activation: By activating only a subset of experts for each input, MoE LLM models optimize computational resources, leading to significant efficiency gains.
Flop-Efficiency
- Reduced Computational Requirements: MoE’s sparse nature means fewer operations are needed per parameter, making the models more flop-efficient.
Scalability and Training Innovations
- Dense-to-Sparse Training: Models can start dense and transition to sparse, leveraging the strengths of both architectures during training.
Progressive Specialization
- Evolutionary Approach: Starting with generalist experts and progressively specializing them can lead to more effective MoE models.
System Design Adaptations
- Parallelism in Training: MoE LLM models benefit from various parallelization strategies, including data, model, and pipeline parallelism, which enhance training speed and efficiency.
Communication Optimization
- Reducing Inter-Node Traffic: Strategies such as hierarchical communication and topology-aware routing minimize the communication overhead during distributed training.
Load Balancing and Gating Mechanisms
- Auxiliary Loss Functions: To prevent some experts from being overburdened while others remain underutilized, MoE models employ specialized loss functions to balance the load.
Advanced Routing Algorithms
- Sophisticated Routing: Advanced algorithms determine which experts are best suited to process specific inputs, improving model performance and efficiency.
Application-Specific MoE Models
- Domain-Focused Experts: MoE LLM models can be tailored to focus on particular domains, such as law, medicine, or science, where specialized knowledge is crucial.
Task-Oriented Configurations
- Customizing Expertise: By configuring the model to emphasize certain types of expertise, MoE architectures can be fine-tuned for specific tasks or applications.
Generalization and Robustness
- Broader Applicability: MoE LLM models are designed to generalize well across different datasets and tasks, enhancing their robustness in various scenarios.
Regularization Techniques
- Preventing Overfitting: Employing techniques such as dropout and token dropping helps MoE models maintain robust performance.
Interpretability and Transparency
- Understanding Expertise: With the complexity of MoE models, there is a growing focus on making the models more interpretable and transparent, allowing users to understand the decision-making process of the model.
Visualization Tools
- Exploring Expert Contributions: Development of tools to visualize how different experts contribute to the final output can aid in understanding and trust.
Integration with Parameter-Efficient Fine-Tuning (PEFT)
- Hybrid Models: Combining MoE with PEFT techniques allows for the efficient adaptation of large pre-trained models to specific tasks without excessive computational costs.
Modular Components
- Plug-and-Play Integration: Creating modular MoE components that can be easily integrated into existing frameworks facilitates broader adoption and application.
What Are Some Popular MoE LLMs?
DBRX: A New Benchmark in LLM Efficiency

- Performance: DBRX outperforms GPT-3.5 and rivals Gemini 1.0 Pro in standard benchmarks and surpasses CodeLLaMA-70B in coding tasks.
- Efficiency and Size: DBRX achieves up to double the inference speed of LLaMA2–70B and maintains a compact size with both total and active parameter counts being about 40% smaller than Grok-1.
Grok: The First Open MoE Model of 300B+ Size

- Grok-1: A 314 billion-parameter model by xAI that uses MoE architecture, with only about 86 billion parameters active at a time, reducing computational demands.
Mixtral: Fine-Grained MoE for Enhanced Performance

- Mixtral 8x7B: Developed by Mistral AI, this model consists of eight experts, each with 7 billion parameters, and only two experts are activated per token during inference.
- Performance: It surpasses the 70 billion parameter Llama model in performance metrics and offers significantly faster inference times.
- Multilingual Support: Mixtral supports multiple languages, including English, French, Italian, German, and Spanish, showcasing its versatility in handling diverse linguistic datasets.
Practical Applications of MoE Models
Natural Language Processing (NLP)
MoE models have been instrumental in enhancing performance across NLP tasks such as machine translation, question answering, and code generation. The integration of MoE into LLMs allows for handling more complex linguistic patterns and generating more nuanced responses.
Computer Vision
Inspired by the success in NLP, MoE models have been applied to computer vision tasks, demonstrating the potential to discern distinct image semantics through specialized experts, thus improving efficiency and accuracy in image recognition.
Multimodal Learning
MoE architecture is well-suited for multimodal applications, where models process and integrate various data types. The ability of expert layers to learn distinct modality partitioning makes MoE an attractive choice for developing efficient and effective multimodal learning systems.
Challenges of Training MoE Models
Training Mixture of Experts (MoE) LLM models introduces several challenges due to their architectural complexity and the need to manage sparse activations. Here are some of the key challenges associated with training MoE models:
Load Balancing
Ensuring an even distribution of computational load across different experts to prevent some from being overutilized while others remain underutilized.
Training Stability
The discrete nature of gating, which determines which experts are activated for a given input, can lead to instability during training.
Expert Specialization
Encouraging each expert to develop focused knowledge without overlap, which is essential for the model to effectively leverage its increased capacity.
Communication Overhead
In distributed training scenarios, MoE models can introduce significant communication overhead due to the need to coordinate activations and gradients across multiple experts.
Scalability
As MoE models scale up in size, the challenge of efficiently training and deploying them across distributed systems becomes more pronounced.
Sparse Activation
Utilizing the benefits of sparse activations in practice can be difficult due to the non-uniformity of sparse operations within hardware accelerators.
Generalization and Robustness
MoE models may overfit to specific tasks or datasets, which can affect their ability to generalize to new, unseen data.
Interpretability and Transparency
The complexity of MoE models and their dynamic gating mechanisms can make it difficult to understand and explain the model’s decision-making process.
Optimal Expert Architecture
Selecting the right types and numbers of experts, and determining their allocation across different layers, is crucial for the model’s performance but can be challenging to optimize.
Integration with Existing Frameworks
Seamlessly integrating MoE models into existing large language models without the need for retraining from scratch is important for practical adoption but can be complex.
Hardware and Software Optimization
MoE models require specialized hardware and software support to efficiently handle their sparse and dynamic computation patterns.
Hyperparameter Configuration
Finding the right hyperparameters, such as the number of experts, the sparsity of activations, and the gating mechanism, can be challenging and may require extensive experimentation.
Addressing these challenges is essential for the successful training and deployment of MoE models, and ongoing research is focused on developing techniques to overcome them.
Integrating MoE LLM Model With Ease
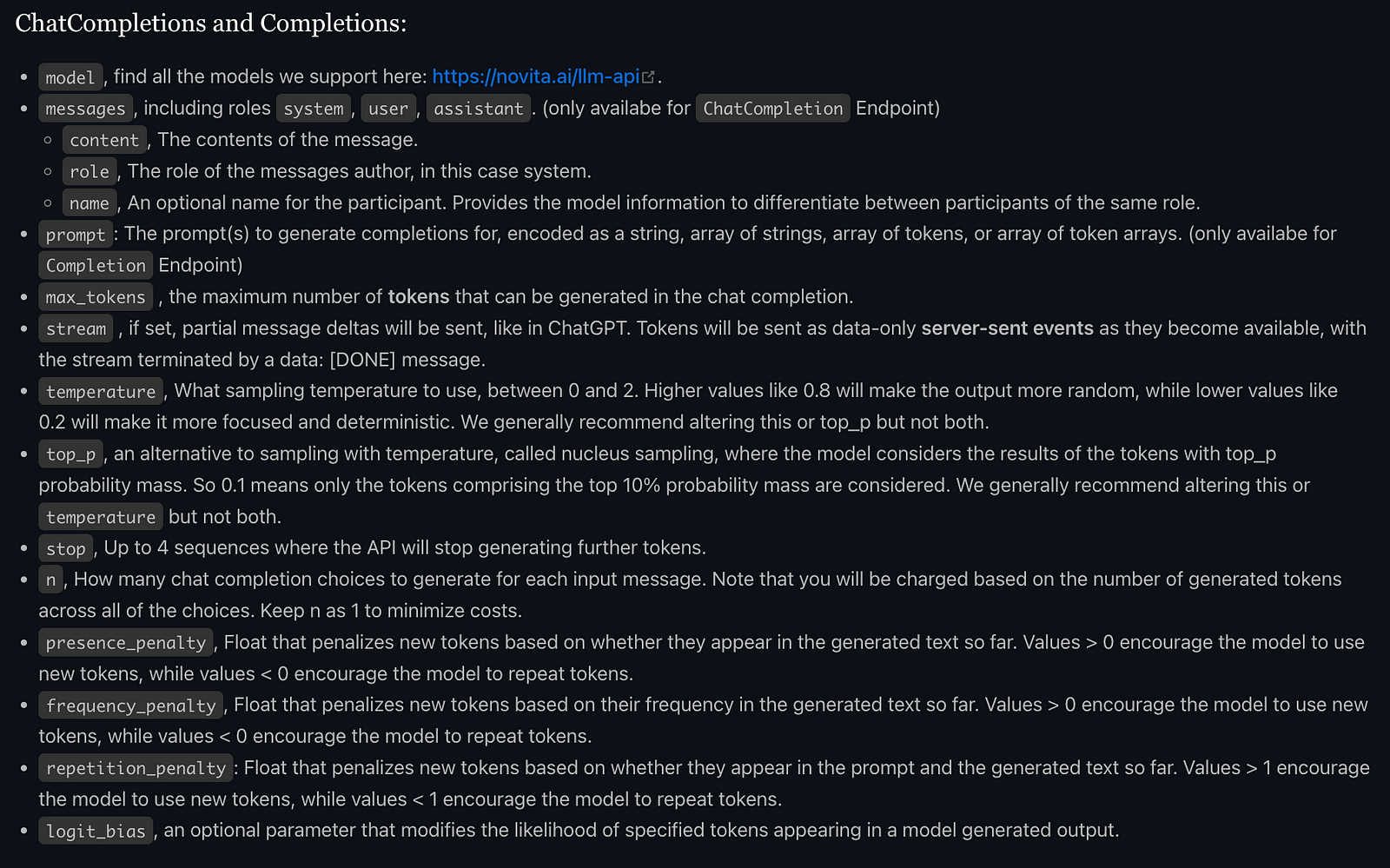
Instead of training or building your MoE model, using an MoE LLM Model API saves you a lot of trouble. Novita AI provides Nous Hermes 2 Mixtral 8x7B DPO — the new flagship Nous Research model trained over the Mixtral 8x7B MoE LLM. The model was trained on over 1,000,000 entries of primarily GPT-4 generated data, as well as other high quality data from open datasets across the AI landscape, achieving state of the art performance on a variety of tasks. Here is a step-by-step guide to integrating this model API:
Step 1: Create an Account
Visit Novita AI. Click the “Log In” button in the top navigation bar. At present, we only offer both Google login and Github login authentication method. After logging in, you can earn $0.5 in Credits for free!
Step 2: Create an API key
Currently authentication to the API is performed via Bearer Token in the request header (e.g. -H “Authorization: Bearer ***”). We’ll provision a new API key.
You can create your own key with the Add new key.
Step 3: Initialize Novita AI API Client
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>", # Replace with your actual API key
)
model = "Nous-Hermes-2-Mixtral-8x7B-DPO"Novita AI LLM API protocol allows parameter adjustments, including top p, presence penalty, temperature, and max tokens.
Future Directions of MoE in LLMs
The future of Mixture of Experts (MoE) LLM models is poised for significant advancements that will enhance their scalability and efficiency. As MoE models continue to grow in size, researchers are focusing on maintaining or even improving their computational efficiency. This involves optimizing the balance between model capacity and the computational cost per parameter, which is crucial for handling increasingly complex tasks. Addressing training instabilities and overfitting, which are common challenges in MoE models, will also be a priority. Strategies such as careful regularization, dataset augmentation, and advanced training algorithms will be essential to ensure robust model performance. Additionally, improving load balancing among experts and optimizing communication overhead in distributed training setups will be key areas of focus to achieve better resource utilization and faster training times.
In parallel, the integration of MoE with other cutting-edge techniques is set to unlock new capabilities. The combination with Parameter-Efficient Fine-Tuning (PEFT) and Mixture of Tokens (MoT) is particularly promising, as it could lead to models that are not only more efficient but also capable of richer data understanding and handling in natural language processing tasks. Furthermore, enhancing the interpretability and transparency of MoE models will be vital for building trust and ensuring the safe deployment of these models in critical applications.
Conclusion
The journey of Mixture of Experts (MoE) models, from their inception in 1991 to their integration into modern Large Language Models (LLMs), highlights their transformative impact on artificial intelligence. Initially conceived to address the limitations of single neural networks, MoE introduced a collaborative approach through specialized experts, enhancing model performance and efficiency across complex tasks and extensive datasets.
Today, MoE continues to evolve, tackling challenges such as computational efficiency, training stability, and model interpretability. Looking forward, these innovations are poised to usher in a new era of AI applications characterized by improved performance, robustness, and transparency across diverse domains.
Frequently Asked Questions
1. Is Mixture of Experts the path to AGI?
No. To be specific, AGI should be capable of performing tasks at a human cognitive level despite having limited background knowledge, like thinking machines with human-like comprehension abilities, not confined to domain-specific limitations.
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.
Recommended Reading
Introducing Mixtral-8x22B: The Latest and Largest Mixture of Expert Large Language Model
Grok API — Pros, Cons and Alternatives