Choosing Between LlamaIndex and LangChain: A Comprehensive Guide

Key Highlights
- LlamaIndex: Specializes in data ingestion, structuring, and leveraging private or domain-specific data for tasks like advanced question-answering and document understanding.
- LangChain: Offers an open-source comprehensive framework for developing, deploying, and scaling applications with LLMs, supporting diverse use cases including conversational agents, translation, and complex workflows.
- Custom LLM Integration: Provides a comprehensive, step-by-step code guide for implementing Custom LLMs with LlamaIndex and LangChain frameworks, showcasing their respective approaches to integrating and leveraging external APIs such as Novita AI.
Introduction
In the rapidly evolving landscape of artificial intelligence and natural language processing, two frameworks have emerged as powerful tools for developers working with Large Language Models (LLMs): LlamaIndex and LangChain. This blog post aims to provide a comprehensive comparison of LlamaIndex vs LangChain, exploring their key features, use cases, and practical applications. By delving into the core functionalities, pricing models, and integration capabilities of each framework, we’ll equip you with the knowledge to make an informed decision on which tool best suits your specific needs.
What Is LlamaIndex?
LlamaIndex is a sophisticated data framework engineered to empower Large Language Models (LLMs) by providing them with contextually relevant, user-specific data. Unlike general-purpose LLMs that are pre-trained on public data, LlamaIndex enables these models to access and leverage private, domain-specific, or problem-centric data, which is often siloed behind APIs, within databases, or trapped in unstructured formats like PDFs.
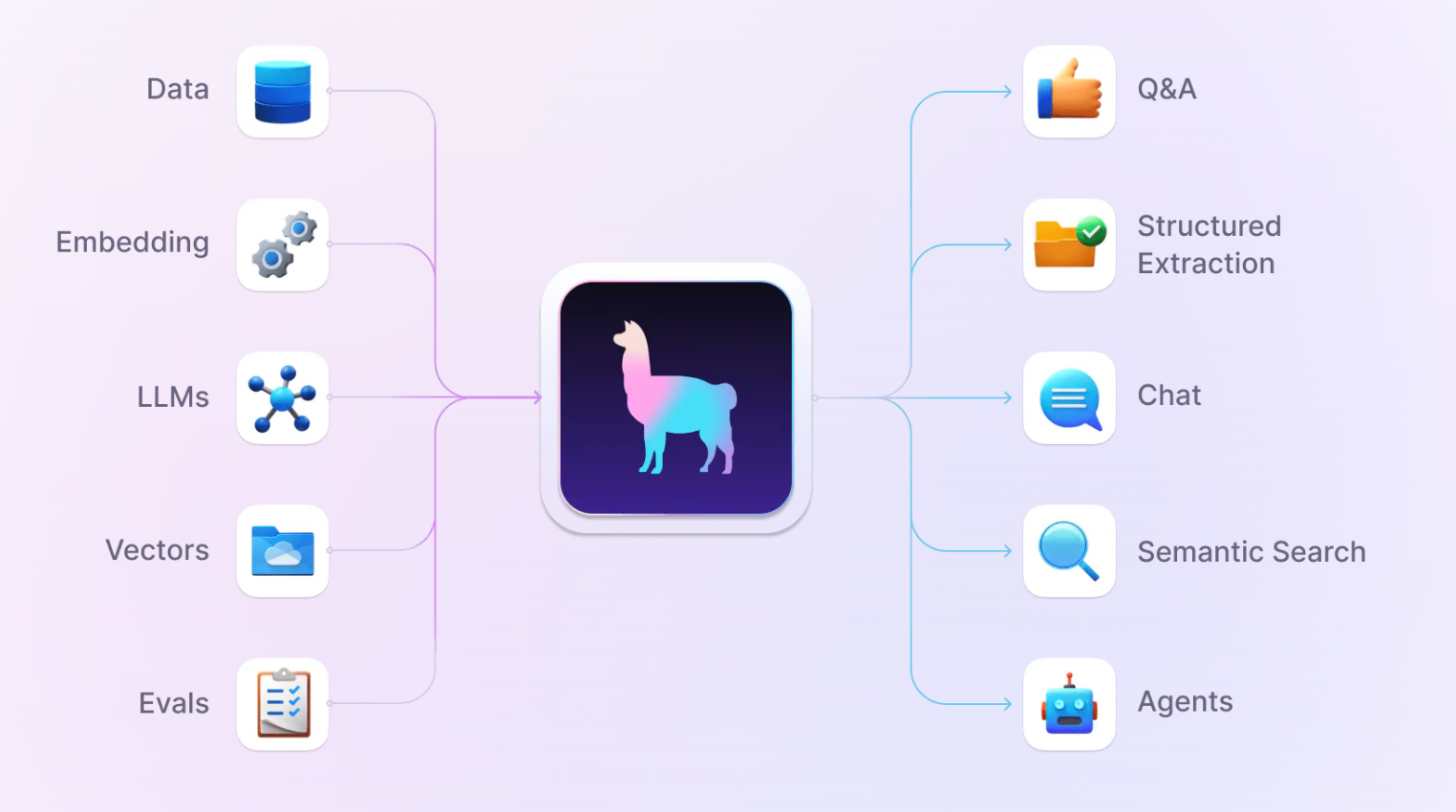
Key Features and Capabilities
- Data Ingestion: LlamaIndex offers data connectors that seamlessly ingest data from a variety of sources, including but not limited to APIs, PDFs, and SQL databases, in their native formats.
- Data Structuring: It structures ingested data into intermediate representations that are optimized for efficient consumption by LLMs, ensuring high performance.
- Natural Language Access: LlamaIndex provides engines that grant natural language access to data, facilitating question-answering through query engines and enabling conversational interactions via chat engines.
- Knowledge Workers: The framework includes agents that function as LLM-powered knowledge workers, augmented by an array of tools ranging from simple helpers to complex API integrations.
- Observability and Evaluation: It incorporates integrations for rigorous experimentation, evaluation, and monitoring, ensuring a cycle of continuous improvement for applications.
Use Cases
LlamaIndex supports a diverse range of use cases, such as:
- Retrieval-Augmented Generation (RAG) for advanced question-answering systems.
- Chatbots that can engage in meaningful, context-aware conversations.
- Document Understanding and data extraction from unstructured documents.
- Autonomous Agents capable of conducting research and executing actions.
- Multi-modal Applications that integrate text with images and other data types.
- Fine-tuning of models on specific data to enhance performance.
What Is LangChain?
LangChain is a cutting-edge framework specifically designed to streamline the development, productionization, and deployment of applications powered by Large Language Models (LLMs). It offers a comprehensive suite of tools and libraries that cater to every stage of the LLM application lifecycle, ensuring a seamless and efficient development process.

Key Features and Capabilities
- Development: LangChain provides open-source building blocks, components, and third-party integrations that simplify the creation of LLM applications. LangGraph, a key component, enables the construction of stateful agents with robust support for streaming data and human-in-the-loop workflows.
- Productionization: LangSmith is a powerful tool for inspecting, monitoring, and evaluating the performance of your LLM chains. It ensures continuous optimization and confident deployment by offering deep insights into application performance.
- Deployment: LangGraph Cloud facilitates the transformation of LangGraph applications into production-ready APIs and Assistants, making it easy to scale and integrate LLM applications into various systems.
- Hierarchical Organization: The framework is organized hierarchically, with interconnected parts across multiple layers, ensuring modularity and flexibility in application development.
Open-Source Libraries
- langchain-core: Offers base abstractions and the LangChain Expression Language, serving as the foundation for the framework.
- langchain-community: Integrates third-party services and expands the capabilities of LangChain.
- Partner Packages: Lightweight packages such as langchain-openai and langchain-anthropic that provide specific integrations, enhancing the framework’s versatility.
- langchain: Comprises chains, agents, and retrieval strategies that form the cognitive architecture of an application.
- LangGraph: A powerful tool for building stateful multi-actor applications with LLMs, using a graph-based model for steps, and can be integrated with or used independently of LangChain.
- LangServe: Deploys LangChain chains as REST APIs, facilitating easy integration with web services.
- LangSmith: A developer platform that provides a comprehensive suite of tools for debugging, testing, evaluating, and monitoring LLM applications.
Audience and Use Cases
LangChain is designed for developers at all levels, from novices to experts, who are looking to harness the power of LLMs in their applications. Its modular and extensible architecture makes it suitable for a wide range of use cases, including but not limited to:
- Building conversational agents and chatbots.
- Developing language translation and summarization tools.
- Creating content generation and classification systems.
- Implementing complex workflows with LLMs.
LlamaIndex vs LangChain: Key Differences
Core Functionality:
- LangChain is a comprehensive framework designed to simplify the creation of data-aware and agentic applications with Large Language Models (LLMs). It offers a wide range of tools for various LLM-powered applications, focusing on flexibility and advanced AI capabilities.
- LlamaIndex (formerly known as GPT Index) is a data framework specifically focused on ingesting, structuring, and accessing private or domain-specific data for LLMs. It simplifies indexing and retrieval of information, making it perfect for text-based search and generating accurate responses.
Use Cases:
- LangChain is versatile and can be used for a variety of applications such as text generation, language translation, text summarization, and text classification. It is particularly well-suited for maintaining long and contextually relevant conversations due to its excellent memory management and chain capabilities.
- LlamaIndex excels in scenarios where text search and high-quality responses are the top priorities. Common use cases include content generation, document search and retrieval, LLM augmentation for chatbots and virtual assistants.
Pricing and Availability:
- LangChain is an open-source and free tool, with its source code available for download on platforms like GitHub, making it accessible for anyone to use.
- LlamaIndex is a commercial product, and its pricing is determined by usage, which means it may involve costs based on the extent to which it is used within applications.
Customization and Flexibility:
- LangChain offers advanced customization options, making it suitable for developers who need to fine-tune their applications with specific requirements.
- LlamaIndex provides user-friendly features and tools that facilitate the seamless integration of private or domain-specific data into LLMs, focusing on ease of use and straightforward data management.
Data Handling:
- LangChain is designed to work with a variety of data types and sources, offering components like Schema for data organization and Indexes for efficient information retrieval.
- LlamaIndex emphasizes the ability to compose an index from other indexes, making it highly effective for complex queries and workflows that involve multiple data sources.
Integration:
- LangChain provides integrations with third-party services and can be extended with partner packages for specific LLM providers.
- LlamaIndex offers data connectors for seamless integration of various data sources, enhancing data quality and performance.
LlamaIndex vs LangChain: Practical Examples Comparison
Referencing from Ming on Medium, here are some practical examples comparing LlamaIndex with LangChain.
Creating a chatbot with a local LLM
The code examples show how to initialize the LLM with both frameworks and how to print the output of a chat interaction.
LlamaIndex Code:
from llama_index.llms import ChatMessage, OpenAILike
llm = OpenAILike(
api_base="http://localhost:1234/v1",
timeout=600,
api_key="loremIpsum",
is_chat_model=True,
context_window=32768,
)
chat_history = [
ChatMessage(role="system", content="You are a bartender."),
ChatMessage(role="user", content="What do I enjoy drinking?"),
]
output = llm.chat(chat_history)
print(output)LangChain Code:
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="http://localhost:1234/v1",
request_timeout=600,
openai_api_key="loremIpsum",
max_tokens=32768,
)
chat_history = [
SystemMessage(content="You are a bartender."),
HumanMessage(content="What do I enjoy drinking?"),
]
print(llm(chat_history))Building a RAG system for local files
The code snippets illustrate how to load data, create an index, and perform a query.
LlamaIndex Code:
from llama_index import ServiceContext, SimpleDirectoryReader, VectorStoreIndex
service_context = ServiceContext.from_defaults(
embed_model="local",
llm=llm, # This should be the LLM initialized in the task above.
)
documents = SimpleDirectoryReader(
input_dir="mock_notebook/",
).load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
service_context=service_context,
)
engine = index.as_query_engine(
service_context=service_context,
)
output = engine.query("What do I like to drink?")
print(output)LangChain Code:
from langchain_community.document_loaders import DirectoryLoader
# pip install "unstructured[md]"
loader = DirectoryLoader("mock_notebook/", glob="*.md")
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits, embedding=FastEmbedEmbeddings())
retriever = vectorstore.as_retriever()
from langchain import hub
# pip install langchainhub
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm # This should be the LLM initialized in the task above.
)
print(rag_chain.invoke("What do I like to drink?"))From the comparison, it seems that LlamaIndex, with a focus on RAG systems, provides a simpler approach while LangChain offers a more abstract, high-level method.
LlamaIndex vs LangChain: How to Use Custom LLM with LlamaIndex?
To integrate Novita AI’s LLM API with LlamaIndex, you will need to create a custom adapter that wraps the Novita AI API calls within the LlamaIndex framework. Below is a conceptual example of how you might achieve this. Please note that this example assumes you have a basic understanding of how to work with APIs and the LlamaIndex framework.
Step 1: Define a custom adapter for the Novita AI LLM
First, let’s define a custom adapter for the Novita AI LLM:
class NovitaAILLM:
def __init__(self, api_key):
from openai import OpenAI
self.client = OpenAI(api_key=api_key, base_url="https://api.novita.ai/v3/openai")
def complete_chat(self, messages, stream=False, max_tokens=512):
response = self.client.chat.completions.create(
model="Nous-Hermes-2-Mixtral-8x7B-DPO",
messages=messages,
stream=stream,
max_tokens=max_tokens
)
return responseStep 2: Integration to LlamaIndex service context
Next, you would need to integrate this adapter into the LlamaIndex service context. Here’s a conceptual example of how you might do that:
from llama_index import (
KeywordTableIndex,
SimpleDirectoryReader,
ServiceContext,
)
from llama_index.llms import LLM
class NovitaAILLMAdapter(LLM):
def __init__(self, api_key):
self.novitailm = NovitaAILLM(api_key)
def generate_text(self, prompt, stop_sequences=None, **kwargs):
# Prepare the messages for the chat completion
messages = [
{"role": "system", "content": prompt}
]
# Call the Novita AI LLM to complete the chat
response = self.novitailm.complete_chat(messages)
if isinstance(response, list): # If streaming, collect all chunks
return "".join([chunk.choices[0].delta.content for chunk in response])
else:
return response.choices[0].message.content
# Initialize the Novita AI LLM adapter with your API key
novitailm_adapter = NovitaAILLMAdapter(api_key="<YOUR Novita AI API Key>")
# Create the service context with the custom LLM adapter
service_context = ServiceContext.from_defaults(llm=novitailm_adapter)
# Load documents and build the index as before
documents = SimpleDirectoryReader("data").load_data()
index = KeywordTableIndex.from_documents(documents, service_context=service_context)
# Now you can use the index with the custom LLM for queries
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do after his time at Y Combinator?")
print(response)This example shows how to create a custom adapter for Novita AI’s LLM and integrate it into the LlamaIndex framework. You will need to replace <YOUR Novita AI API Key> with your actual API key from Novita AI.
Please note that this is a conceptual example and may require adjustments to fit the specific versions of the libraries you are using and the exact API details of Novita AI’s LLM. Always refer to the official documentation for the most accurate and up-to-date information.
LlamaIndex vs LangChain: How to Use Custom LLM with LangChain?
To integrate Novita AI LLM API with LangChain using custom LLM, you’ll need to create a custom class that extends LangChain’s LLM class and uses Novita AI's API for its logic.
Here’s a step-by-step guide on how to do this:
Step 1: Install the OpenAI Python Library
First, ensure you have the OpenAI library installed, which will be used to interact with Novita AI’s API.
pip install 'openai>=1.0.0'Step 2: Import Required Libraries
Import necessary modules from LangChain and the OpenAI library.
from typing import Any, Dict, Iterator, List, Optional
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from langchain_core.outputs import GenerationChunk
from openai import OpenAIStep 3: Define the Custom LLM Class
Extend the LLM class to create a custom LLM that uses Novita AI's API.
class NovitaAILLM(LLM):
def __init__(self, api_key: str, model_name: str = "Nous-Hermes-2-Mixtral-8x7B-DPO"):
self.api_key = api_key
self.model_name = model_name
self.client = OpenAI(api_key=api_key, base_url="https://api.novita.ai/v3/openai")
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
"""Run the LLM on the given input."""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=False,
max_tokens=512,
)
return response.choices[0].message.content
def _stream(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[GenerationChunk]:
"""Stream the LLM on the given prompt."""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=512,
)
for chunk in response:
chunk_text = chunk.choices[0].delta.content or ""
yield GenerationChunk(text=chunk_text)
@property
def _identifying_params(self) -> Dict[str, Any]:
"""Return a dictionary of identifying parameters."""
return {
"model_name": self.model_name,
}
@property
def _llm_type(self) -> str:
"""Get the type of language model used by this chat model. Used for logging purposes only."""
return "NovitaAILLM"Step 4: Initialize and Use the Custom LLM
Create an instance of your custom LLM with your Novita AI API key and use it to generate text.
# Replace with your actual Novita AI API key
novita_api_key = "<YOUR Novita AI API Key>"
# Initialize the custom LLM
novita_llm = NovitaAILLM(api_key=novita_api_key)
# Generate text
prompt = "Hi there!"
response = novita_llm._call(prompt=prompt)
print(response)
# Or stream the response
for chunk in novita_llm._stream(prompt=prompt):
print(chunk.text, end="")This code sets up a custom LLM that uses Novita AI’s API to generate text based on a given prompt. The _call method is used for non-streaming responses, and the _stream method is used for streaming responses. Adjust the model_name and other parameters as needed based on Novita AI's API documentation and your specific requirements.
Conclusion
In conclusion, LlamaIndex and LangChain are both valuable tools for working with Large Language Models, each with distinct strengths. LlamaIndex excels in data ingestion and retrieval, making it ideal for projects requiring efficient handling of specific data and advanced question-answering systems. LangChain offers a more comprehensive framework for developing and deploying LLM applications, with its modular architecture and extensive integrations. The choice between the two depends on your project’s specific needs.
FAQs
Can LangChain and LlamaIndex be used together?
Yes. It depends on specific needs of your LLM project.
Is LangChain good for production?
Yes, LangChain 0.1 and later are production-ready.
Which is better for rag LlamaIndex or LangChain?
LlamaIndex is recommended if your primary focus is on data retrieval and search capabilities. LangChain is better suited for scenarios where you need a flexible framework that can handle complex workflows.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
How to Create Your LLM With LangChain: a Step-by-Step Guide
Master Streaming Langchain: Tips for Interacting with LLMs