Can Large Language Models Do Causal Reasoning?

Introduction
How do we humans discern the causes behind the effects we observe around us? When we see storm clouds gathering, why do we predict rain, or how do we conclude that a medication was effective when our health improves?
This ability, known as causal reasoning, is a key component of human cognition that helps us navigate and make sense of the world. But can modern artificial intelligence, particularly large language models (LLMs) like GPT-3 and GPT-4, emulate this critical skill? How well do these models understand the connection between cause and effect, and where do they fall short? In this blog, we will discuss these questions concerning causal reasoning and large language modelsone by one.
What Is Causal Reasoning?
We humans are really good at understanding causes and effects. When we see one thing happen, we can often figure out what caused it and what effects it might have. This ability to reason about causes is called causal reasoning.
It’s a crucial skill that helps us make sense of the world and make good decisions. For example, if you get better after taking medicine, you can infer the medicine caused your recovery. Or if you see storm clouds, you can anticipate that rain is the likely effect.
Causal reasoning is vital for fields like science, medicine, policy-making and more. Getting the causes right allows us to effectively intervene on problems and avoid wrongly attributing effects to the wrong causes.
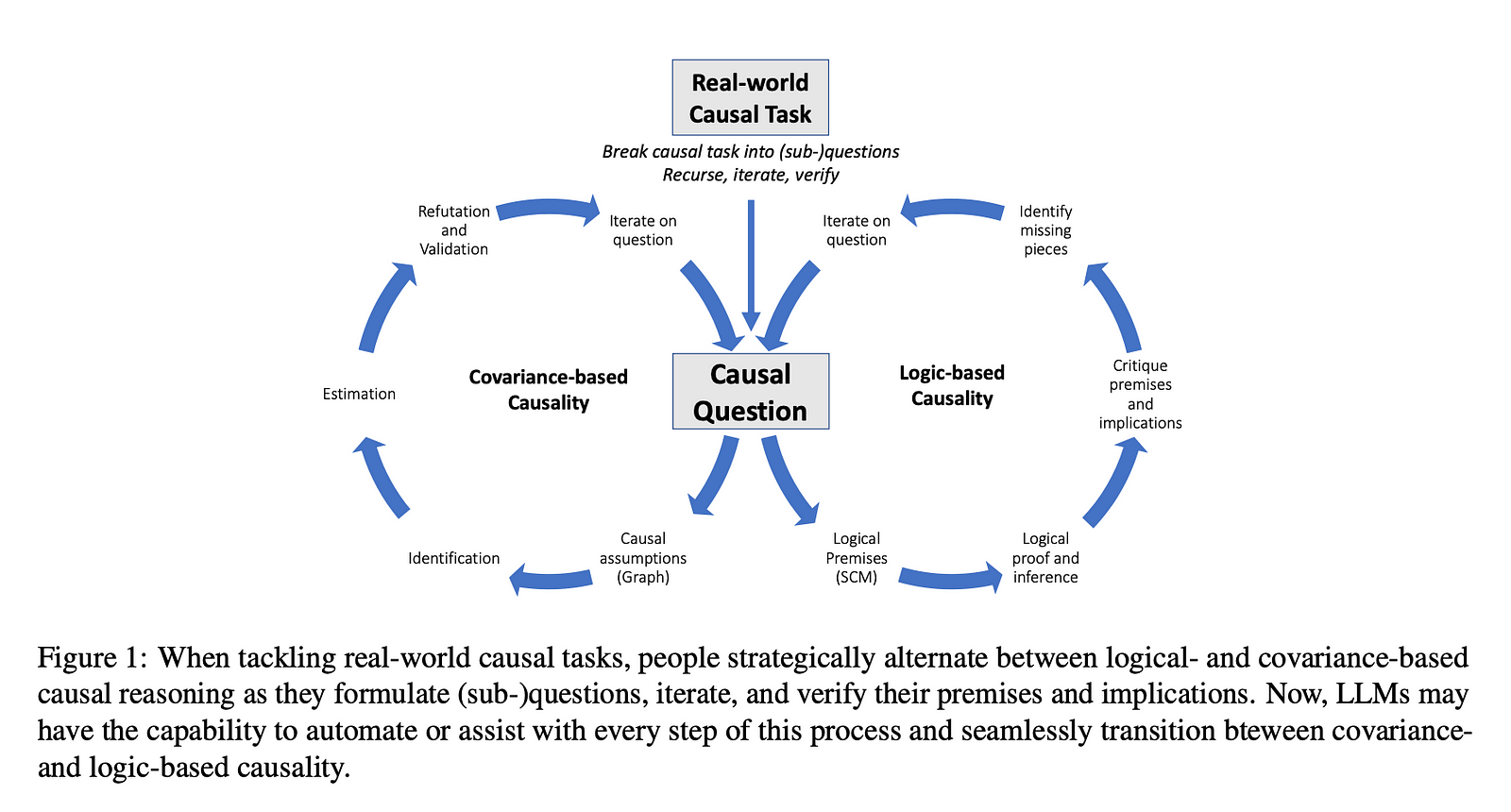
Types of Causal Reasoning Tasks
There are different types of causal reasoning tasks that require this cause-effect understanding:
Causal Discovery
Figuring out the causal relationships between different variables just from observational data. For example, analyzing health data to determine if smoking causes cancer.
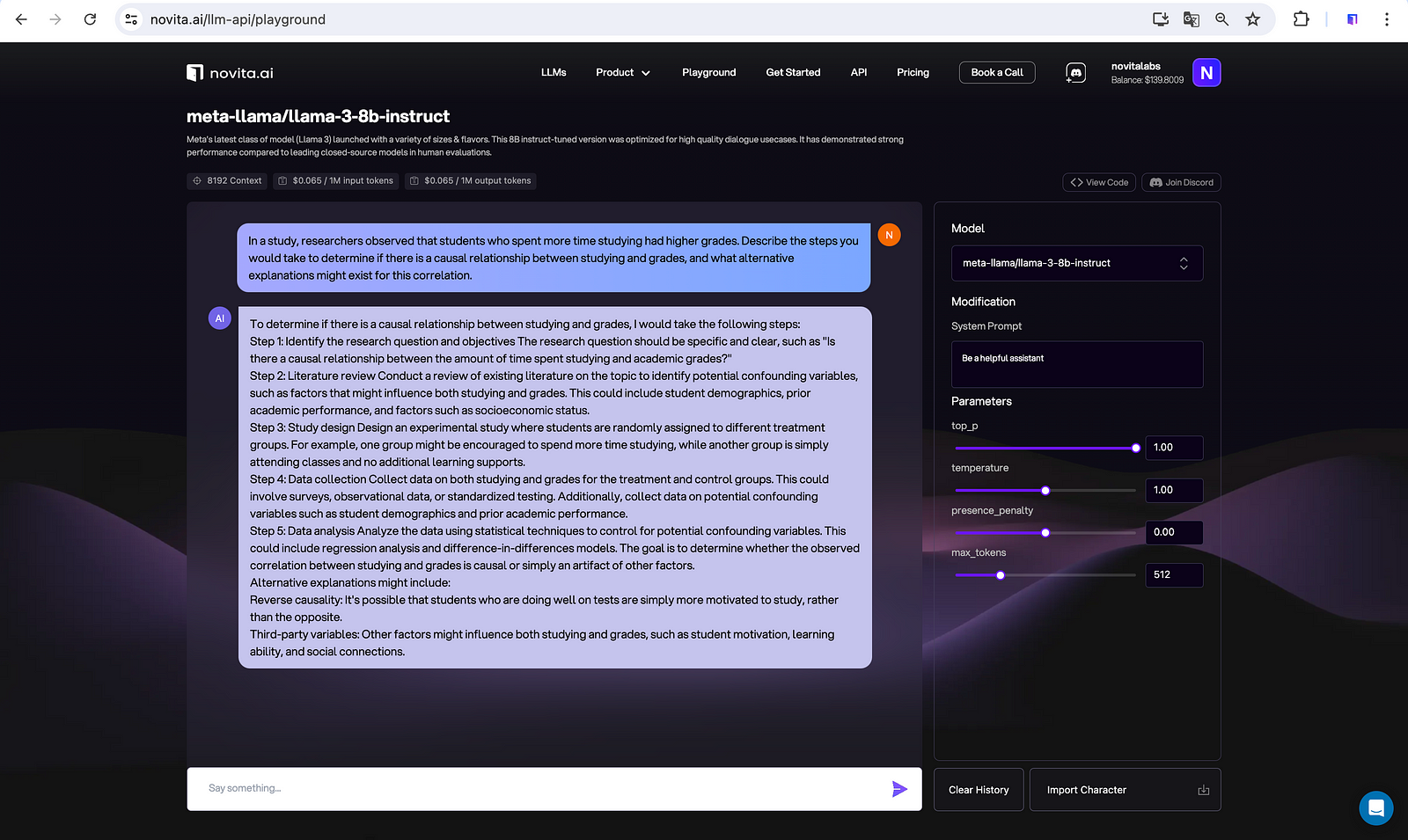
Effect Estimation
Quantifying the magnitude of a cause’s effect on an outcome variable. Like calculating how much smoking increases cancer risk.
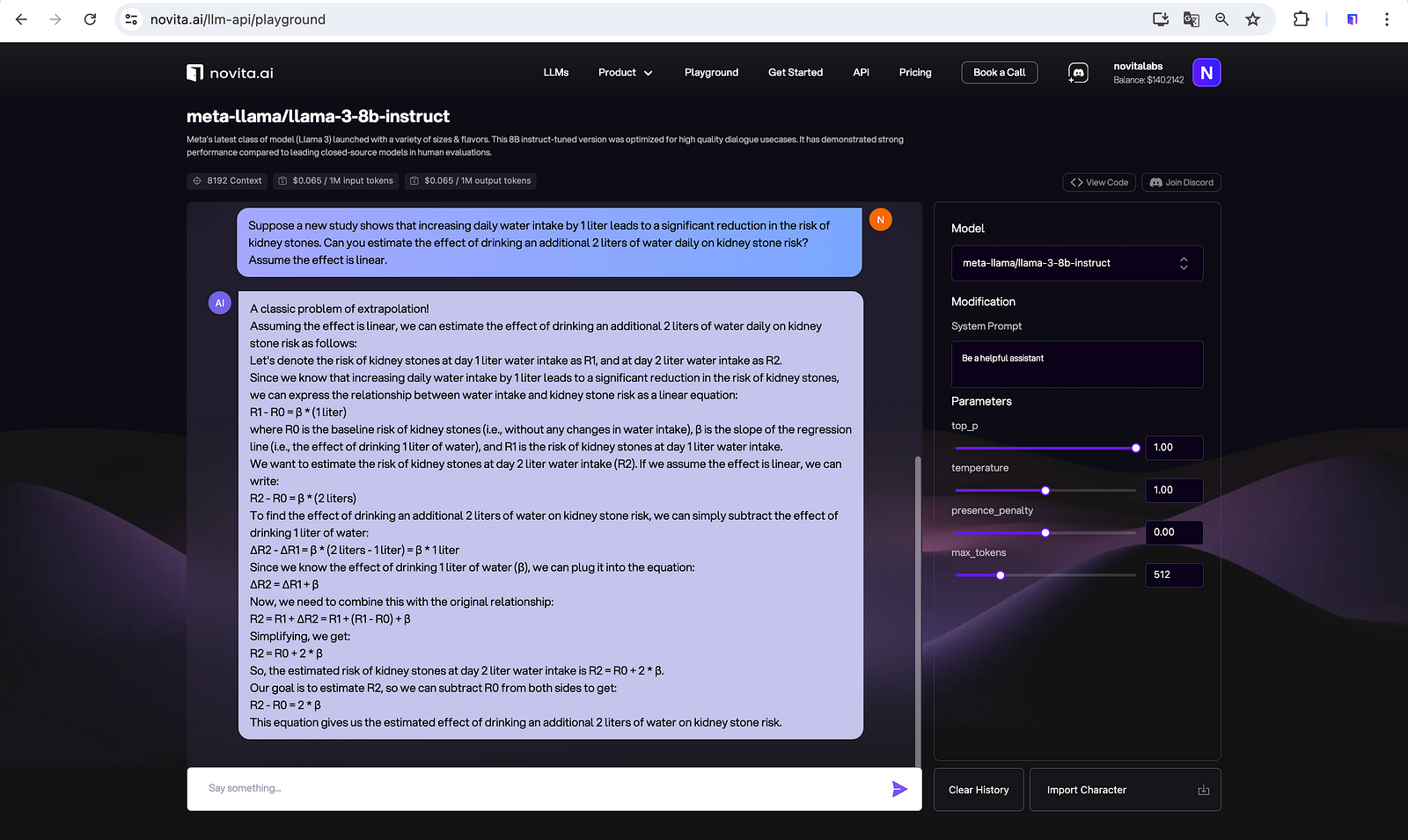
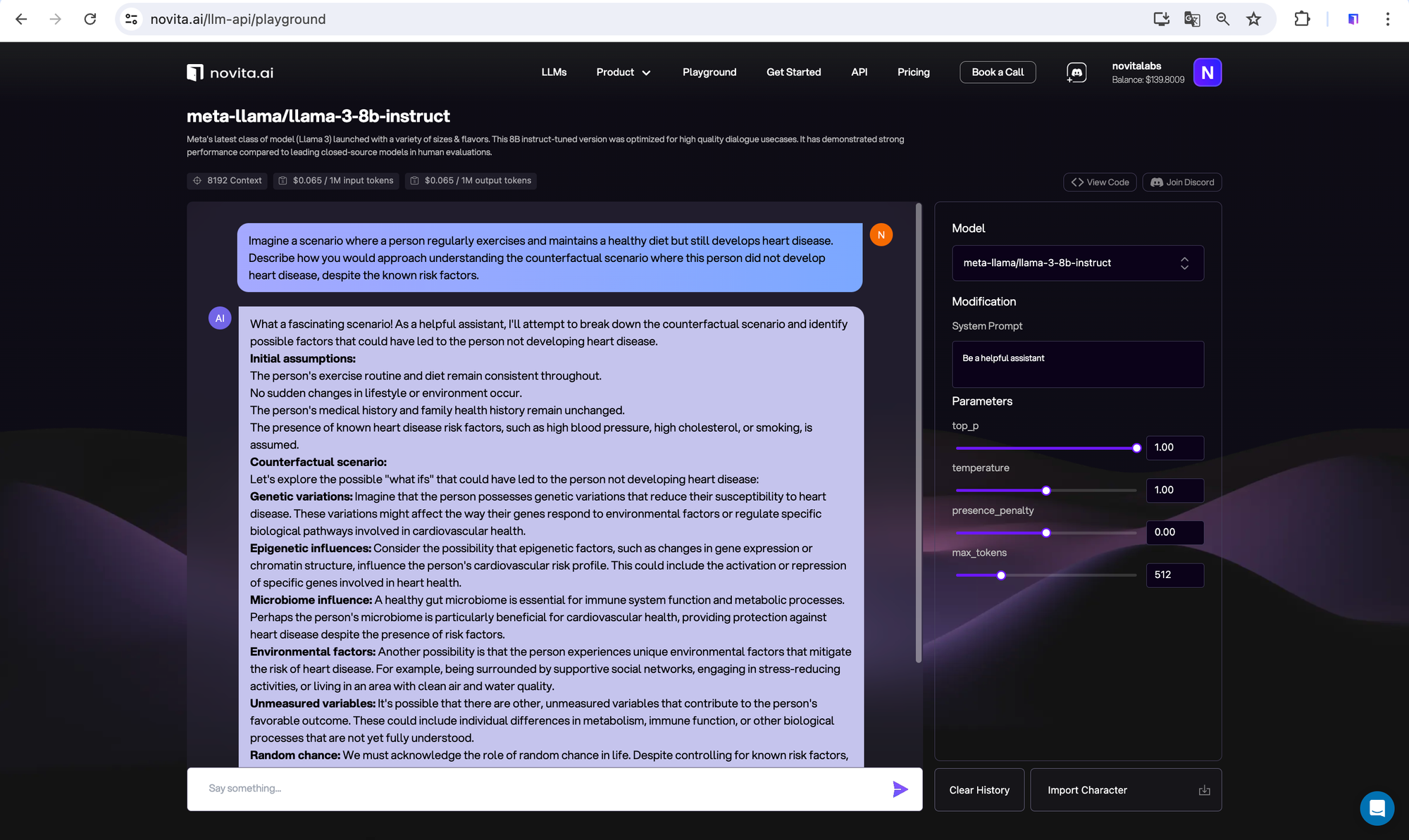
Counterfactual Reasoning
Considering alternative scenarios like “If I hadn’t smoked, would I still have gotten cancer?”
Actual Causation
For a specific event that occurred, determining the actual causes that made it happen. Like whether a factory’s polluting was an actual cause of respiratory issues in a community.
How Good Are LLMs at Causal Reasoning?
Researchers (Kıcıman et al., 2023) have started evaluating large language models (LLMs) like GPT-3 and GPT-4 on a variety of these causal reasoning tasks using established benchmarks. The results are pretty fascinating:
Pairwise Causal Discovery: Easy
This refers to the task of determining the causal relationship between a pair of variables X and Y. Is X causing Y, Y causing X, are they just correlated, or is there no relationship?
LLMs achieved a remarkable 97% accuracy at determining the causal relationship between variable pairs across over 100 examples from diverse domains like physics, biology, epidemiology and more. This substantially outperformed the previous best traditional causal discovery algorithms that topped out at 83% on the Tübingen benchmark (a dataset used for evaluating causal discovery algorithms on the task of pairwise causal orientation).
Full Causal Graph Discovery: Easy
Going beyond pairs of variables, this involves discovering the entire causal graphical model over a set of variables — determining which variables cause which others and representing it as a graph. This allows mapping out the full causal structure among multiple variables.
At this more complex task of recovering the entire causal graphical model over multiple variables, LLM methods were competitive with recent deep learning approaches like GCAI. On benchmarks like CADTR and CBN-Discrete, GPT-4’s predicted graphs achieved similar structural accuracy scores.
Counterfactual Reasoning: Easy
This evaluates if an LLM can reason about how the outcomes would change under different hypothetical scenarios or interventions on the causal system. For example, “If this cause hadn’t happened, would that effect still occur?” Counterfactuals are central to human causal cognition.
When evaluated on this benchmark, GPT-4 answered 92% of the questions correctly. This was a substantial 20 percentage point gain over the previous state-of-the-art on this counterfactuals benchmark.
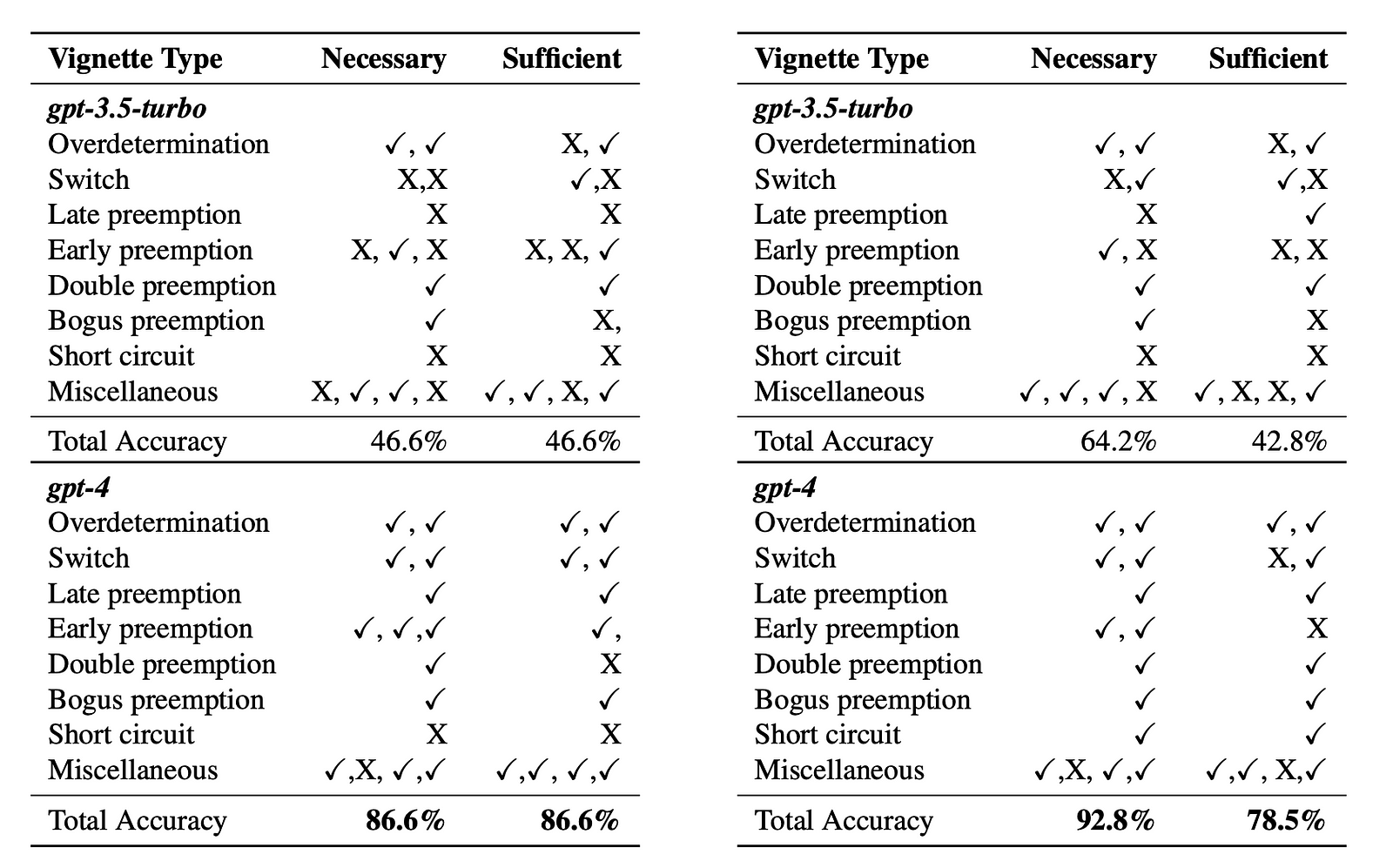
Identifying Necessary/Sufficient Causes: Easy
For a specific event that occurred, this requires identifying which causes were necessary for the event to happen, and which subset of causes was enough (sufficient) to make the event occur. This gets at the core of determining actual causation.
Given short vignette descriptions of specific events that occurred, GPT-4 could successfully identify the necessary causes that had to be present, as well as the minimally sufficient causes that were enough for the event to occur, with 86% accuracy.
Assessing Normality: Still Easy
A key component of higher-level reasoning about the actual causation of events is assessing whether some cause or event violated typical norms and defaults. LLMs performed moderately well at around 70% accuracy on this type of normality judgment task from the Cause18 benchmark.
The researchers highlighted that LLMs achieved these results while only being provided the variable/event descriptions as prompts — without directly analyzing any data. This suggests LLMs may possess an interesting capability to leverage their broad knowledge to perform remarkably well on many causal reasoning tasks.
What Are the Limitations of LLMs’ Causal Reasoning Abilities?
No Hexagon Warrior
In Kıcıman et al.’s (2023) experiments GPT 3 and GPT 4, no single LLM outperformed the other across every benchmark.
GPT-3
Strengths:
- Achieved 97% accuracy on pairwise causal discovery (Tübingen benchmark), substantially better than previous methods
- Showed ability to perform well on some causal reasoning tasks despite not directly accessing data
Weaknesses:
- Not explicitly evaluated on more complex tasks like full causal graph discovery or counterfactuals
- Exhibited unpredictable failures and brittleness to prompt variations (limitation noted for LLMs in general)
GPT-4
Strengths:
- Strong performance across multiple tasks:
- 92% accuracy on counterfactual reasoning
- 86% on identifying necessary/sufficient causes
- Competitive with deep learning methods on full causal graph discovery
- Represented a significant capability gain over GPT-3
Weaknesses:
- Still had some performance gaps on tasks like assessing event normality (70% accuracy)
- Lacked robustness to prompt variations impacting performance (general LLM limitation)
Unpredicted Failures
- Contextual Misinterpretation: LLMs often fail to correctly interpret causal contexts, particularly in situations that deviate from common patterns seen in their training data. This can result in causal explanations that are not only incorrect but also misleading, especially in complex scenarios involving multiple interacting factors.
- Logical Errors: Even with sophisticated models like GPT-4, LLMs are susceptible to making basic errors in logic. They might display a strong understanding in one instance and then fail in another under slightly different conditions. These failures often stem from the model’s limitations in applying deeper logical reasoning consistently across varied contexts.
Lack of Robustness
- Prompt Dependency: The performance of LLMs in causal reasoning is greatly influenced by how questions are phrased. Small changes in wording can lead to significantly different outcomes, reflecting the model’s dependency on specific linguistic cues rather than a genuine understanding of causal mechanisms.
- Inconsistency in Responses: LLMs can produce different answers to the same question when asked multiple times or under slightly altered conditions. This inconsistency highlights a lack of stability in the model’s reasoning process, making it unreliable for tasks where consistent and accurate causal analysis is critical.
Why Do LLMs Perform Well in Causal Reasoning but Still Make Basic Mistakes?
The simple answer is: LLMs are just “Causal Parrots: Large Language Models May Talk Causality But Are Not Causal” .
Lack of Genuine Causal Understanding
Correlation vs. Causation: LLMs fundamentally operate on statistical correlations derived from vast amounts of data they are trained on. They lack the capability to inherently distinguish between correlation and causation, which is a critical aspect of genuine causal reasoning. The models do not have access to underlying causal mechanisms but only to patterns that may mimic causality.
Meta Structural Causal Models (meta SCMs)
Zečević, Willig, Dhami, and Kersting (2023) introduce the concept of meta SCMs to explain instances where LLMs appear to perform causal reasoning. These models encode causal facts about other SCMs within their variables, suggesting that LLMs can only mimic the appearance of causality when they recite or reflect the correlations learned during training that are structured like causal facts.
Training on Correlated Data
The term “causal parrots” used in the article by Zečević, Willig, Dhami, and Kersting (2023) illustrates that LLMs, like parrots, merely repeat the information (including causal relations) they have been exposed to in their training data without actual understanding. This repetition is based on the patterns and correlations in the data rather than any real comprehension of causality.
What Are the Future Directions for Causal Reasoning Research About LLMs?
Understanding LLM Causal Reasoning Capabilities
Further research is needed to understand the mechanisms by which LLMs perform causal reasoning tasks. This includes investigating how LLMs capture and apply common sense and domain knowledge in causal scenarios.
Improving Robustness and Reliability
LLMs exhibit high average accuracies but also make simple, unpredictable mistakes. Future research should focus on increasing the robustness of LLMs, possibly through external tools or additional instances of LLMs themselves.
Integration with Existing Causal Methods
There is potential for LLMs to be integrated with existing causal methods, serving as a proxy for human domain knowledge and reducing the effort required to set up causal analyses.
Knowledge-Based Causal Discovery
Exploring how LLMs can leverage metadata and natural language descriptions to infer causal structures, potentially reformulating the causal discovery problem to include variable metadata and existing knowledge encoded through LLMs.
Counterfactual Reasoning
Developing methods that guide LLMs in using causal primitives like necessity and sufficiency to answer higher-level actual causal judgment questions, possibly using formal actual causality theory as a guide.
Human-LLM Collaboration
Researching the best ways to facilitate collaboration between humans and LLMs for tasks such as graph creation, where LLMs may suggest graph edges and provide feedback on manually generated graphs.
Causal Effect Inference
Investigating how LLMs can assist in identifying valid adjustment sets for causal effect inference and suggesting potential instrumental variables for causal tasks.
Systematizing Actual Causality and Attribution
Utilizing LLMs to support actual causal inference in domains like law and intelligence analysis, where analysts need to synthesize explanations about the degree to which events contribute to other events.
Benchmark Creation for Causal Discovery
Leveraging LLMs to help identify potentially missing or mislabeled edges in causal discovery benchmarks, given their ability to process large amounts of text.
Exploring LLM Capabilities in Various Causal Tasks
Further research is needed to explore LLMs’ capabilities across a wide range of causal tasks, including causal discovery, effect inference, and actual causality.
Merging Covariance- and Logic-Based Reasoning
Investigating how LLMs can facilitate a merging of covariance-based and logic-based causal analysis through natural language interfaces.
Conclusion
In conclusion, the exploration of causal reasoning within the realm of large language models (LLMs) reveals a dual-edged sword. On one hand, LLMs like GPT-3 and GPT-4 have demonstrated remarkable proficiency in causal reasoning tasks. On the other hand, the limitations of LLMs in causal reasoning are non-trivial. Despite their high accuracy in certain tasks, they still make basic mistakes and exhibit unpredictable failure modes. This is largely attributed to their lack of genuine causal understanding, as they operate based on statistical correlations rather than true causal mechanisms.
As we continue to unravel the complexities of LLMs’ causal reasoning abilities, it is crucial to approach their integration into real-world applications with caution. While they hold promise for augmenting human expertise in causal analyses, they should not replace the rigor of formal causal reasoning frameworks. Instead, LLMs should be viewed as complementary tools that can democratize access to causal tools and knowledge, facilitating more fluid and natural language-based interactions for conducting causal analysis. The path forward lies in harnessing the strengths of LLMs while acknowledging and addressing their limitations, steering towards a future where causal reasoning in AI is both sophisticated and dependable.
References
Kıcıman, E., Ness, R., Sharma, A., & Tan, C. (2023). Causal reasoning and large language models: Opening a new frontier for causality (Working Paper №23–05002). arXiv. https://arxiv.org/abs/2305.05002
Zečević, M., Willig, M., Dhami, D. S., & Kersting, K. (2023). Causal Parrots: Large Language Models May Talk Causality But Are Not Causal. Transactions on Machine Learning Research, 08(2023). Retrieved from https://arxiv.org/abs/2308.13067
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.