Building the Ultimate Transformer Train

If you are in the Natural Language Processing (NLP) field, you must have heard about Transformers. Since its introduction in 2017, it has become a game-changer in the NLP industry. Transformers are a type of neural network that can process sequential data, such as language, with remarkable accuracy and speed. They have revolutionized NLP by providing better results than previous models while requiring less computational power. In this blog, we will take a deep dive into Transformers, starting from the basics of what they are and their importance in NLP. We will then explore different types of Transformer networks and delve into the tokenization process. We’ll also discuss how to train a masked language model using Transformers and introduce PyTorch’s role in enhancing Transformer networks. Finally, we’ll touch on various applications where Transformers can be applied and the future of NLP with these incredible models.
Understanding Transformers in Natural Language Processing (NLP)
Understanding Transformers in Natural Language Processing (NLP) involves comprehending their working principles, differences from traditional NLP models like RNNs and LSTMs, and the advantages they offer in NLP tasks. Businesses and developers can leverage pre-trained Transformer models such as ‘optimus prime’ and ‘autobots’ for NLP applications. Exploring Python-based NLP with ‘dc’ and ‘ho’ libraries and harnessing ‘amazon’ and ‘ac’ for NLP tasks are essential for effective implementation.
The Evolution of Transformers in NLP
Transformers, like BERT and GPT-3, have revolutionized NLP, enhancing accuracy and efficiency in language tasks. Real-world applications such as chatbots and language translation showcase their significant impact. The future holds potential advancements in various industries, further integrating transformers. Their importance in NLP cannot be overstated, positioning them as crucial tools for language processing.
Why are Transformers Important in NLP?
Transformers play a crucial role in NLP due to their ability to enhance language understanding and generation. By using attention mechanisms, they focus on relevant parts of the input sequence, making them more efficient than traditional RNNs. Additionally, Transformers can handle longer input sequences without losing information. Some popular Transformer-based models in NLP include BERT, GPT-2, and XLNet.
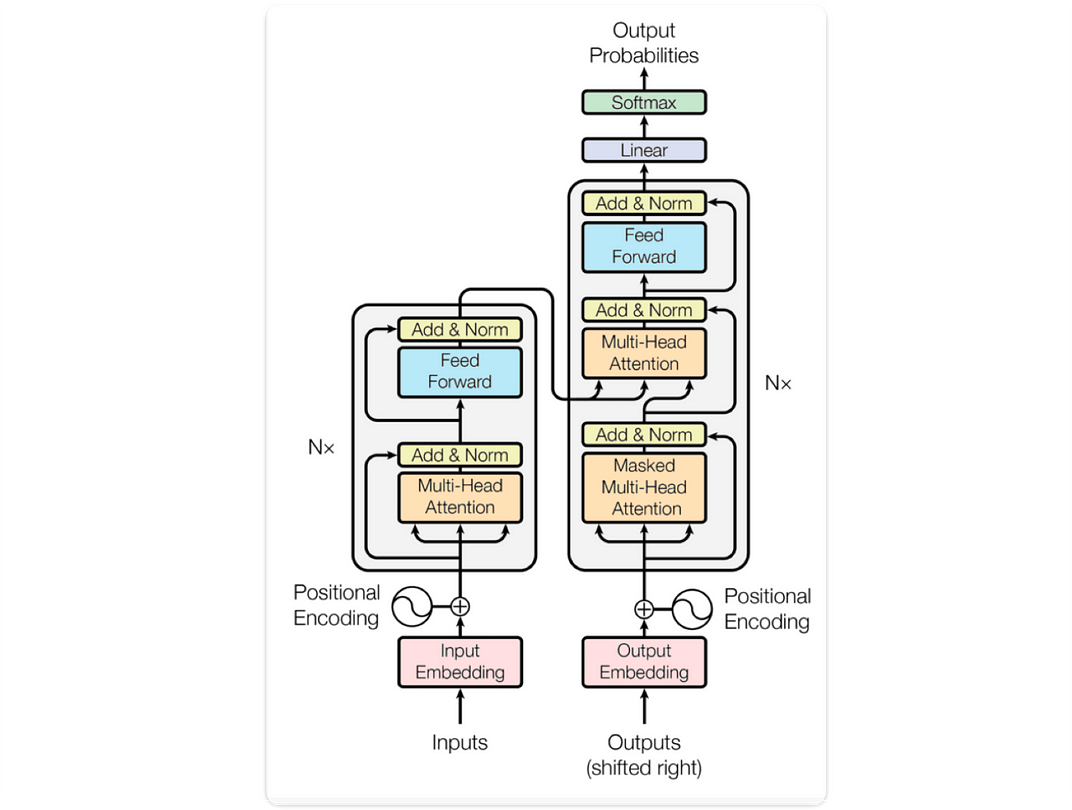
Delving into the Transformer Network
Understanding transformer networks requires a deep dive into their architecture and mechanisms. The impact of transformer networks on NLP has been revolutionary, particularly in improving the efficiency of language processing tasks. Evaluating the learning rate scheduler of transformer networks is crucial for optimizing their performance. Additionally, transformer networks have found wide-ranging applications in machine translation, effectively bridging language barriers in various domains.
Defining Transformer Network
The concept of transformer networks lies in their unique architecture and computation steps, crucial for NLP tasks. These networks use attention mechanisms to efficiently handle text sequences. Their role in NLP cannot be overstated as they enable better language understanding and generation. Transformers like BERT and GPT-2 illustrate the impact and significance of these models in the realm of natural language processing.
Exploring Types of Transformer Networks
Diving into the various variations of transformer models and comparing them with previous tutorial models. Understanding the role of transformer networks in machine translation, along with different model layouts and batch sizes. Exploring the significance of the transformer module in machine translation tasks.
We have three major types of transformer networks which are Encoder, Decoder and Sequence2Sequence transformer networks.
Encoder Transformer Network:It is a bidirectional transformer network, it takes in text, produces a feature vector representation for each word in the sentence.Encoder uses self attention mechanism to understand the context of words used in a sentence, and extracts useful information from the words.
A diagram representation of how encoder is able to understand this simple sentence “Coding is amazing” .

The Role of Tokenization in Transformers
The tokenization process significantly impacts transformer models. It plays a crucial role in machine translation and affects vocabulary size. Additionally, tokenization module influences transformer model training and training steps. Optimus Prime and AC are some popular transformer models used in NLP. Understanding tokenization is essential for working with transformer models.
What is Tokenization?
Tokenization is a crucial step in natural language processing (NLP). It involves breaking down text into individual tokens, such as words or subwords. The default tokenization process, along with the dataset and sample code, optimize tokenization vectors and handle padding. This plays a vital role in machine translation technology.
For example a sentence like “Hello everyone” will be split into individual characters like this:
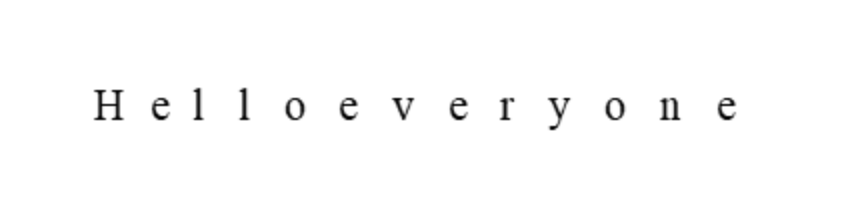
The Process of Tokenization in Transformers
The tokenization process involves batch processing steps, CPU and GPU computation, and the roles of the decoder and encoder modules. Additionally, it includes batch processing details and transformer model inference steps. Optimus Prime enhances the tokenization tech, making it crucial for NLP. Python is used for coding and implementing the tokenization module. This ensures efficient processing for transformer models.
text = "Python is my favourite programming language"print(text.split())##Output
['Python', 'is', 'my', 'favourite', 'programming', 'language']
Training a Masked Language Model with Transformers
Training a Masked Language Model with Transformers involves understanding the process and creating a dataset. The transformer model has its own training loop for masked language models, along with specific optimizer and epoch steps. Additionally, the model utilizes a learning rate optimizer tailored for masked language models, ensuring efficient training.
A Comprehensive Guide to Masked Language Model Training
Mastering the pretrained model training steps of transformer models is crucial. Understanding the hobby controller layout, optimizer default steps, and vector batch processing is essential for effective training. Additionally, integrating tokenization bot accessories will enhance model performance. Optimus Prime enthusiasts can leverage Python to optimize Amazon AC using transformer models.
- Install Pytorch
2. Install other packages
pip3 install transformerspip3 install datasetspip3 install accelerate
3. Load and Tokenize Dataset
from datasets import load_dataset
#load imdb dataset
imdb_data = load_dataset("imdb")
print(imdb_data)
sample = imdb_data["train"].shuffle(seed=60).select(range(2))
for row in sample:
print(f"\n'>> Review: {row['text']}'")
4. Tokenize Dataset
from transformers import AutoTokenizer
# use bert model checkpoint tokenizer
model_checkpoint = "distilbert-base-uncased"
# word piece tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
#define tokenize function to tokenize the dataset
def tokenize_function(data):
result = tokenizer(data["text"])
return result
# batched is set to True to activate fast multithreading!
tokenize_dataset = imdb_data.map(tokenize_function, batched = True, remove_columns = ["text", "label"])
print(tokenize_dataset)
5.Concat and Chunk Dataset
def concat_chunk_dataset(data):
chunk_size = 128
# concatenate texts
concatenated_sequences = {k: sum(data[k], []) for k in data.keys()}
#compute length of concatenated texts
total_concat_length = len(concatenated_sequences[list(data.keys())[0]])
# drop the last chunk if is smaller than the chunk size
total_length = (total_concat_length // chunk_size) * chunk_size
# split the concatenated sentences into chunks using the total length
result = {k: [t[i: i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_sequences.items()}
'''we create a new labels column which is a copy of the input_ids of the processed text data,the labels column serve as
ground truth for our masked language model to learn from. '''
result["labels"] = result["input_ids"].copy()
return result
processed_dataset = tokenize_dataset.map(concat_chunk_dataset, batched = True)
Crucial Steps in Training a Masked Language Model
Maximizing the transformer model’s tokenization layout is crucial for effective training. Implementing the adam optimizer tech and ampac steps enhances the model’s performance. Gathering information through the layout info steps contributes to the model’s accuracy. Additionally, the christmas epoch steps play a significant role in determining the model’s efficacy. Optimus prime, python, and autobots are essential components in this process.
An Introduction to PyTorch in Transformers
The PyTorch tutorial layout for the transformer model involves model inference, learning rate scheduler, and training loop steps. The default tech ampac steps are also integral in the PyTorch module. These components play a crucial role in optimizing the model’s performance and achieving efficient results in natural language processing tasks.
What is PyTorch?
PyTorch, an open-source machine learning library developed by Facebook’s AI Research lab, is widely used in NLP and other AI applications. It provides a flexible computational graph for training ML models and offers support for multiple languages. With its ease of use, PyTorch is ideal for beginners starting their AI projects.
How PyTorch Enhances Transformer Networks
PyTorch enhances transformer model training with efficient computation on both CPU and GPU. It incorporates learning rate scheduler, adam optimizer, and transformer module for improved training loop. The transformer module allows users to fine-tune pretrained models for specific NLP tasks, enhancing text sequences processing with tokenization, padding, and batch computation. PyTorch’s transformer module is compatible with various transformer architectures, expanding its applications.
Steps to Load and Tokenize Dataset
To load and tokenize the dataset, begin by installing essential libraries like TensorFlow and Keras. Then, import and preprocess the dataset with NumPy and Pandas. Utilize tokenizer tools such as TensorFlow Tokenizer for tokenization, followed by splitting the dataset into training, validation, and testing sets. Finally, convert tokenized data into numerical data using techniques like one-hot encoding or word embeddings.
How to Load Dataset for Transformers
Loading datasets for Transformers involves understanding the data format, using Pandas or NumPy for data loading, preprocessing for consistency, and conversion to a compatible format such as PyTorch Dataset. The final step includes batch tokenization using Transformers’ DataCollator class for efficient model training. This process ensures seamless integration of diverse datasets into NLP tasks.
The Process of Tokenizing Dataset for Transformers
Tokenization involves converting data into tokens for machine learning. This process breaks text into words or subwords and is utilized by Transformers to enable NLP tasks. It enhances model performance by reducing data noise. Various libraries, such as Hugging Face Transformers, are available for dataset tokenization. Optimus Prime, python, and Amazon are integral parts of this blog’s content.
Masking Test Dataset for Evaluation
Masking your test dataset is crucial for accurate evaluation. By hiding certain tokens, you assess the model’s ability to predict missing information. This process mimics real-world scenarios and ensures robust performance. Masking impacts the way a model understands and processes language, making it an essential step in the evaluation process.
Importance of Masking in Test Dataset
In NLP, masking the test dataset is crucial for evaluating model performance. By masking certain tokens, the model’s ability to predict missing words can be tested. This process helps in identifying the model’s understanding of context and improves its overall accuracy. Masking also allows for simulating real-world scenarios, leading to more reliable and robust NLP models.
Step-by-Step Guide to Mask Test Dataset
Creating a systematic and accurate process for masking the language model test dataset is crucial. This step-by-step guide ensures detailed assistance in effectively preparing the test dataset for language model training. Understanding and implementing this guide is essential for creating an effective masked language model test dataset. It plays a significant role in ensuring the accuracy and effectiveness of the test dataset for language model training.
The Training Procedure for Transformers
The transformer model’s performance is optimized through the training procedure, crucial for its training. Detailed steps ensure proper execution, emphasizing the importance of an efficient training loop. The procedure significantly impacts the model’s learning rate, making it essential to understand and implement thoroughly.
An Overview of the Training Procedure
The overview of the training procedure offers valuable insights into transformer model training, crucial for understanding the learning process and optimizing performance. A comprehensive grasp of this overview is essential to ensure successful transformer model training and efficient learning rate scheduling. It forms the foundation for grasping the intricate details of the transformer model’s optimization.
Detailed Steps in the Training Procedure
Implementing the detailed steps is vital for accurate transformer model training, influencing the training loop and vocabulary size. Understanding these steps guarantees proficient training and optimization. The execution of each step impacts the model’s overall performance and learning rate scheduler. Proficiency in executing these steps is crucial for the transformer model’s successful optimization and performance enhancement.
Understanding the Rest API Code for Testing the Masked Language Model
Understanding the Rest API code is crucial for efficient model testing. The Rest API code plays a pivotal role in accurately testing the masked language model. Detailed comprehension of the Rest API code enhances model testing accuracy and optimizes the testing process. Efficient utilization of the Rest API code is essential for achieving optimal results in masked language model testing.
What is Rest API Code?
Rest API code is crucial for testing the model, ensuring smooth execution and high efficiency. Understanding this code enables seamless integration into testing procedures, leading to accurate and reliable results. It plays a fundamental role in model testing processes.
Using Rest API Code for Testing the Model
The Rest API code is essential for accurate and efficient model testing, impacting the testing process’s reliability and efficiency. Proper utilization of the Rest API code ensures seamless testing, optimizing the accuracy of model testing procedures. It significantly enhances the reliability and accuracy of the entire model testing process.
Using Google Colaboratory for Training
Enhancing transformer model training efficiency is crucial, and Google Colaboratory serves as a valuable platform for this purpose. Proper utilization of Google Colaboratory significantly impacts the optimization of transformer model training processes. Understanding how to use Google Colaboratory is imperative, as it significantly enhances the efficiency of transformer model training.
Introduction to Google Colaboratory
Google Colaboratory, or Google Colab, plays a pivotal role in transformer model training. Understanding its resources and features is crucial for optimizing transformer model training efficiency. With valuable tools and support for Python, Google Colab enhances the process of model training, making it an essential platform for NLP practitioners. Utilizing Google Colab ensures effective and seamless transformer model training.
How to Use Google Colaboratory for Transformer Training
Utilizing Google Colaboratory is crucial for transformer model training, optimizing processes and efficiency. The platform significantly impacts the model training, playing a pivotal role in its optimization and enhancing accuracy. Understanding the proper usage of Google Colaboratory is key to unlocking its valuable resources for transformer model training.
Transformers and Their Applications
Transformers have redefined NLP with tasks like machine translation and text generation. Their versatility in processing sequences makes them highly sought after for various NLP applications. Due to their architecture allowing parallelization, training efficiency is greatly enhanced. With the rapid evolution of transformers, their applications in NLP continue to expand, shaping the future of language processing.
Is the Future of NLP Dependent on the Evolution of Transformers?
The future of NLP is intricately tied to the evolution of transformers. These advancements are redefining the capabilities of natural language processing and reshaping its landscape. With their profound and far-reaching impact, it’s clear that transformers will continue to play a crucial role in shaping NLP’s future.
Conclusion
In conclusion, transformers have revolutionized natural language processing (NLP) and are vital for various NLP tasks. With their ability to capture long-range dependencies and handle sequential data effectively, transformers have become the go-to model in NLP. Whether it is machine translation, sentiment analysis, or text generation, transformers have shown remarkable performance and versatility. Understanding the architecture and components of transformers, such as attention mechanisms and positional encodings, is crucial for harnessing their power. Additionally, utilizing frameworks like PyTorch and implementing the training procedure step-by-step can help train and fine-tune transformer models. As the field of NLP continues to evolve, transformers are expected to play a pivotal role, shaping the future of language understanding and generation.
novita.ai provides Stable Diffusion API and hundreds of fast and cheapest AI image generation APIs for 10,000 models.🎯 Fastest generation in just 2s, Pay-As-You-Go, a minimum of $0.0015 for each standard image, you can add your own models and avoid GPU maintenance. Free to share open-source extensions.