Beyond the Hype: NVIDIA A100 - A Deep Dive into the Future of Computing

Preface
In the rapidly evolving domains of data centers and AI computing, the NVIDIA A100 Tensor Core GPU has emerged as a technological innovation engine, powered by the NVIDIA Ampere architecture. The A100 GPU not only showcases exceptional performance in applications such as AI, data analytics, and high-performance computing (HPC), but also effectively contributes to the construction of more powerful, elastic data centers through its flexible architecture design. With up to a 20-fold performance increase over its predecessor, the A100 can dynamically adjust to meet demands, dividing into up to seven GPU instances to adapt to varying workloads. In terms of memory, the A100 offers 40GB and 80GB versions, with the 80GB model boasting an ultra-fast memory bandwidth exceeding 2 trillion bytes per second (TB/s), capable of handling massive models and datasets.
NVIDIA A100 Specifications

Core Architecture
The A100 GPU employs the Ampere architecture, the world's first data center GPU architecture based on a 7nm process, integrating up to 54.2 billion transistors across a chip size of 826 square millimeters, providing the GPU with robust computing power and energy efficiency.
CUDA Cores and Tensor Cores
Equipped with up to 6,912 CUDA cores, the A100 GPU offers substantial computational prowess for compute-intensive tasks such as deep learning. Additionally, with 432 third-generation Tensor Cores supporting Tensor Float 32 (TF32) and mixed-precision (FP16) computations, it significantly accelerates deep learning training and inference.
Memory and Memory Bandwidth
The A100 GPU provides options of 40GB, 80GB, and 160GB of high-speed HBM2e memory, with a memory bandwidth of up to 2.5TB/s, meeting the demands of large datasets and high-performance computing. This high capacity and bandwidth enable the A100 GPU to easily handle vast datasets, accelerating the completion of compute tasks.
Interconnect Technologies
The A100 GPU supports the second-generation NVIDIA NVLink and PCIe 4.0, high-speed GPU-to-GPU and GPU-to-CPU data transfer technologies that provide efficient data flow capabilities for data centers. Through these advanced interconnect technologies, the A100 GPU achieves faster data transfer speeds and reduces latency during data transmission.
Key Features
Multi-GPU Cluster Configuration and Dynamic AdjustmentThe A100 GPU supports multi-GPU cluster configurations, capable of dynamically dividing into multiple GPU instances based on actual needs, optimizing resource utilization and flexibility. This design not only enhances the resource utilization of data centers but also enables the processing of large-scale and complex compute tasks.
Efficient Data Processing Capabilities
Optimized for AI inference, the A100 GPU offers higher computational density and lower latency. This means that when handling massive models and complex datasets, the A100 GPU can significantly improve computational speed and efficiency, accelerating the inference process of AI applications.
Compatibility and Usability
The A100 GPU is compatible with multiple operating systems and deep learning frameworks, providing users with a convenient development and deployment environment. The optimization of its Ampere architecture further simplifies the programming model, reducing software complexity, allowing developers to focus more on algorithm and application development.
New Tensor Core Performance
The A100 GPU introduces third-generation Tensor Cores that support a comprehensive range of DL and HPC data types, including new TensorFloat-32 (TF32) operations. These operations accelerate FP32 input/output data in DL frameworks and HPC, running up to 10 times faster than the FP32 FMA operations of the V100, or 20 times faster with sparsity support.
Structured Sparsity Support
The A100 GPU incorporates fine-grained structured sparsity, a novel approach that can double the computational throughput for deep neural networks. By applying structured sparsity during training, the A100 GPU can accelerate the inference process without compromising accuracy.
Multi-Instance GPU (MIG) Functionality
The MIG feature of the A100 GPU allows the safe division of a single A100 GPU into up to seven independent GPU instances, providing resources for CUDA applications. Each instance has separate and isolated paths through the entire memory system, ensuring predictable throughput and latency for individual user workloads even when other tasks saturate their caches or DRAM interfaces.
Test Metrics
For a long time, the A100 has been considered the top choice in large model production systems. Based on this, we conducted detailed tests on the performance of Llama2 on the A100. We varied the input/output length to test the latency and total throughput of Llama2 running on the A100 platform, as well as QPS and time consumption.
Test Results
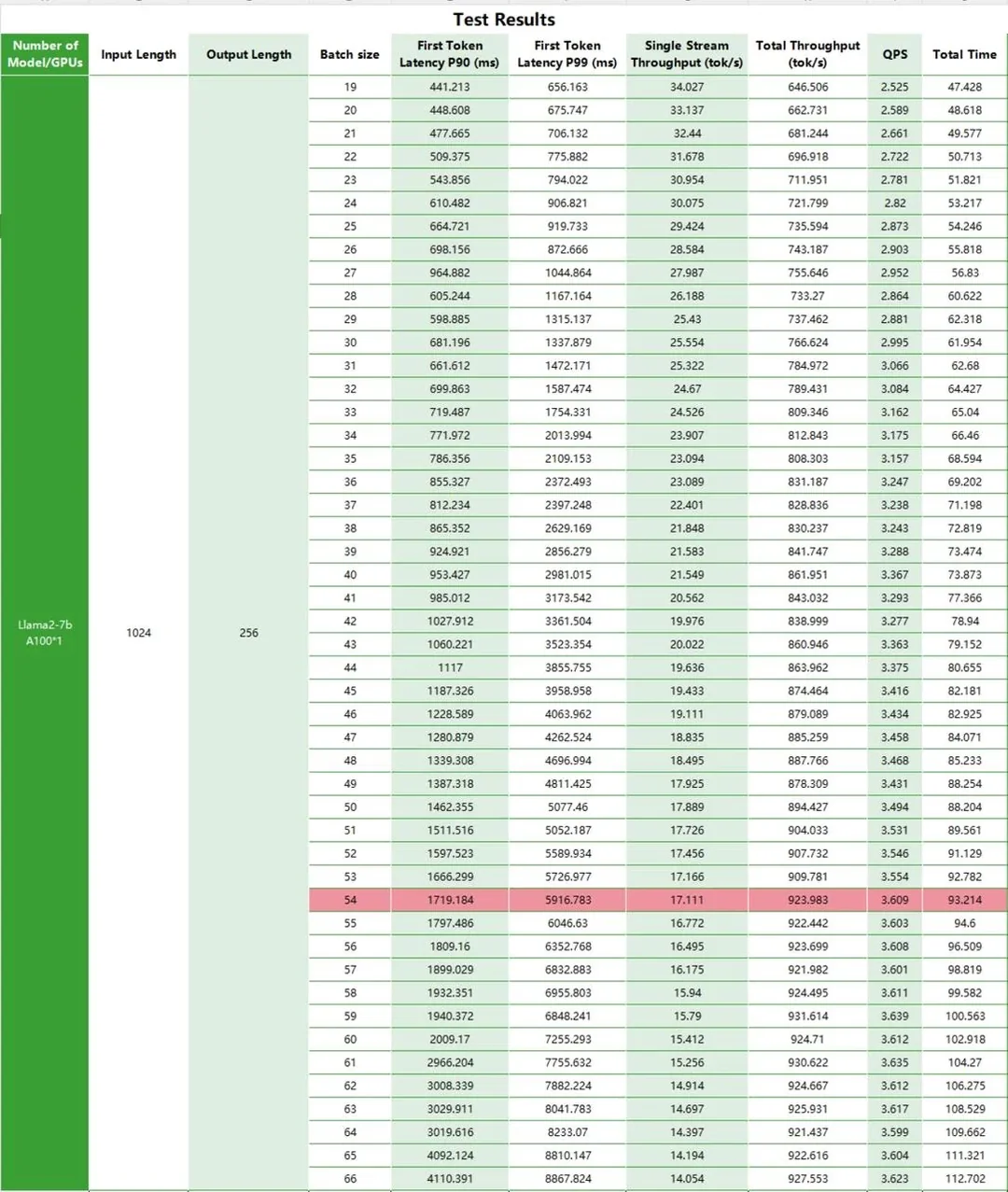
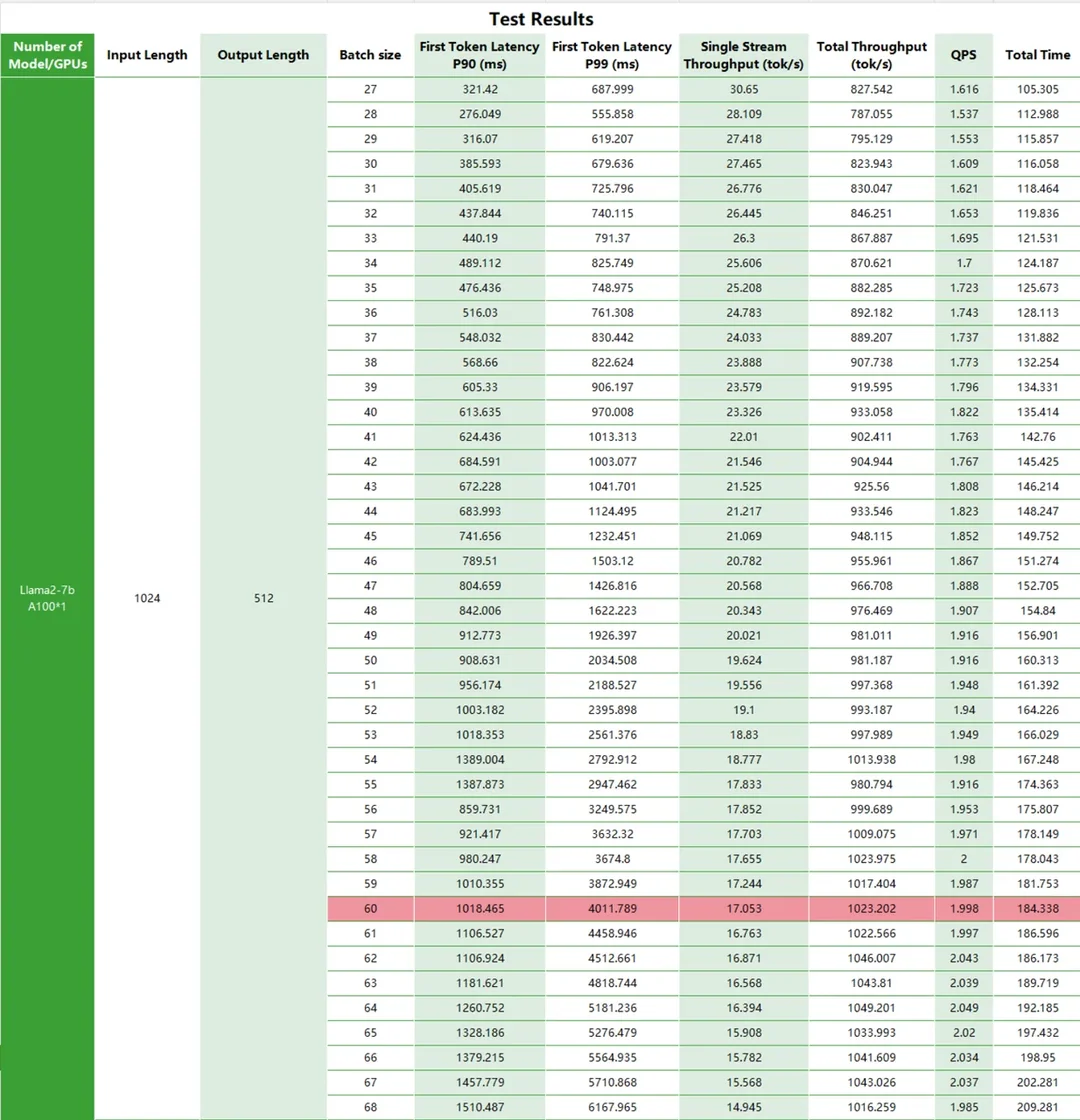
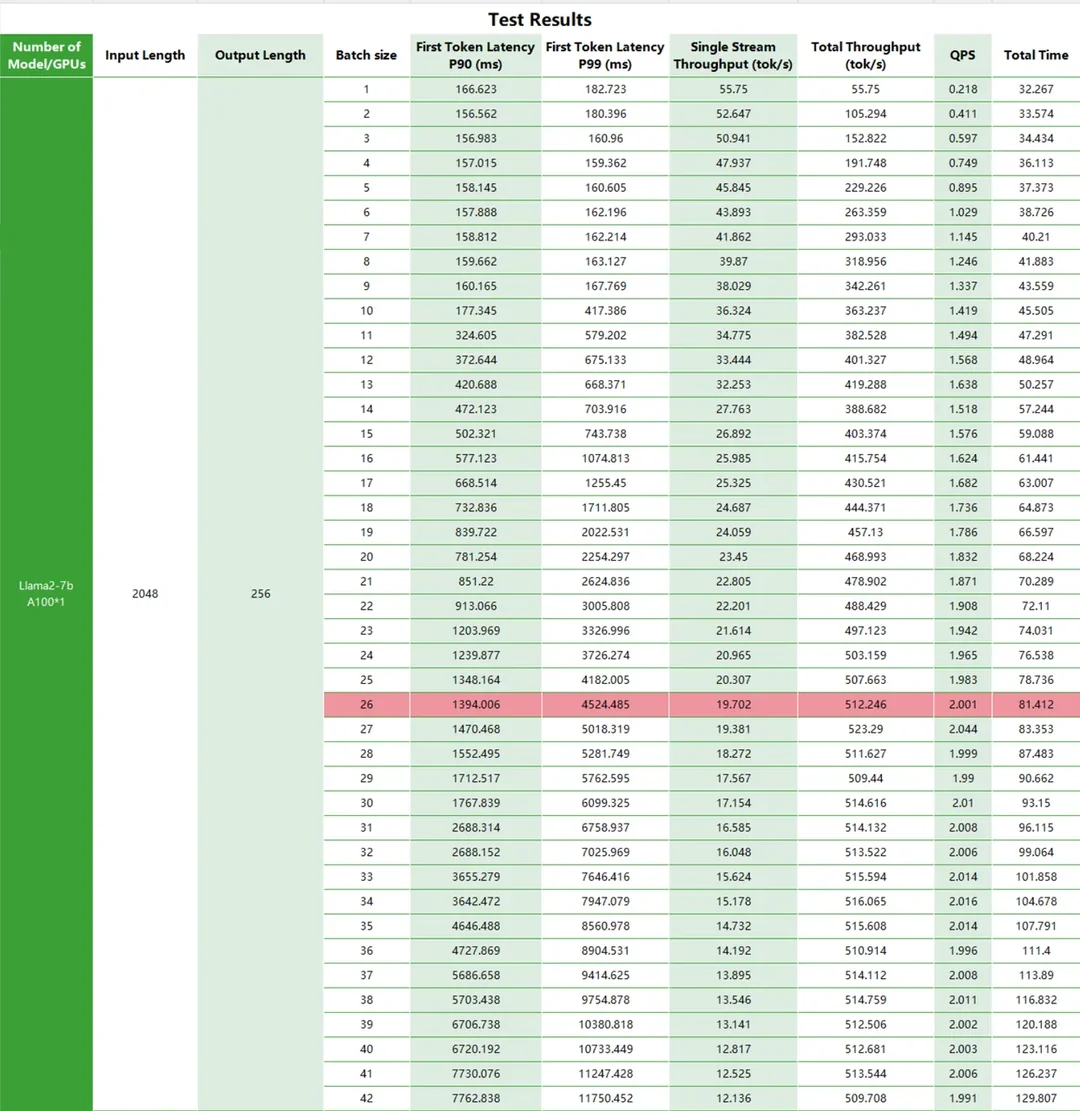
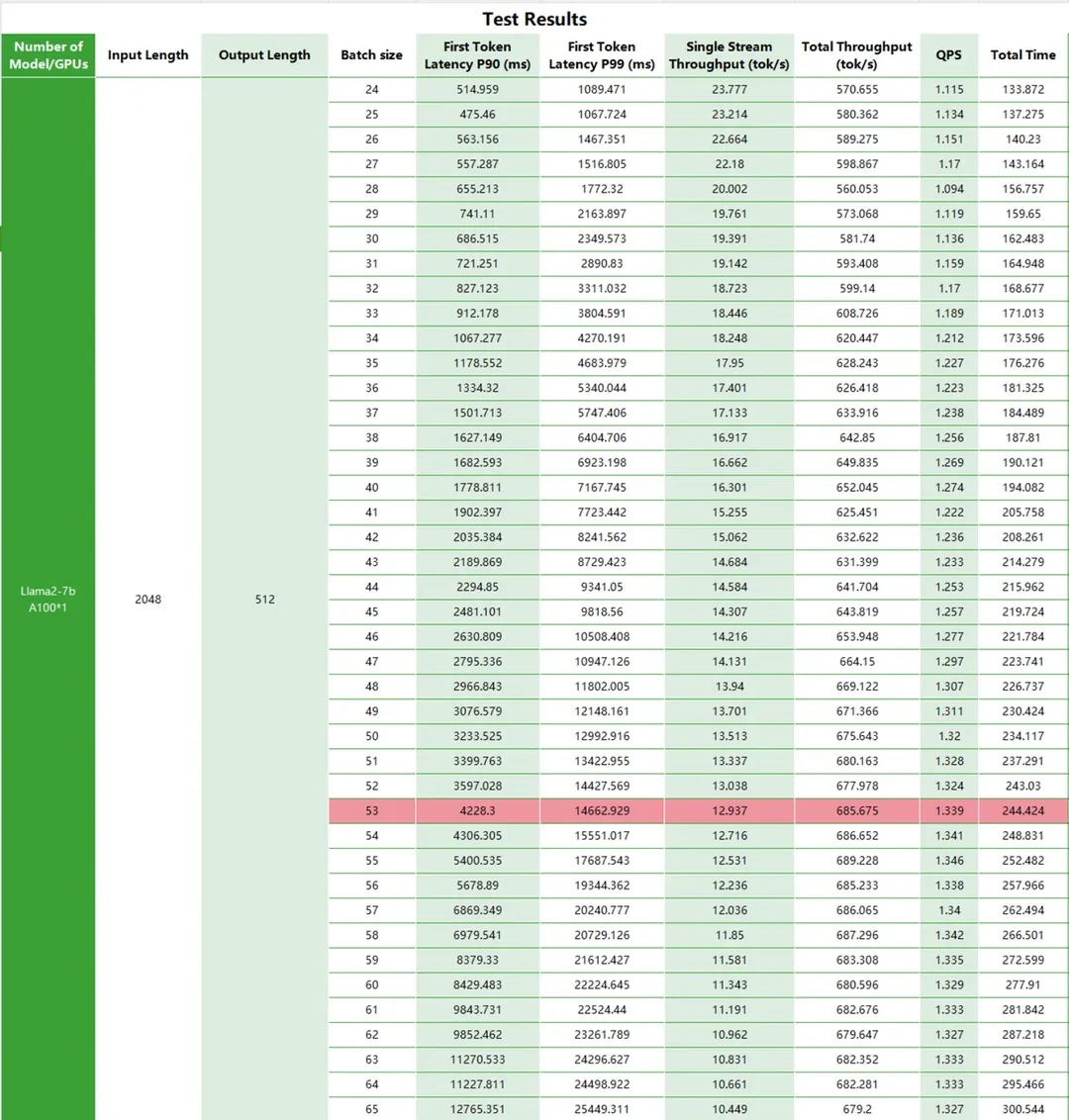
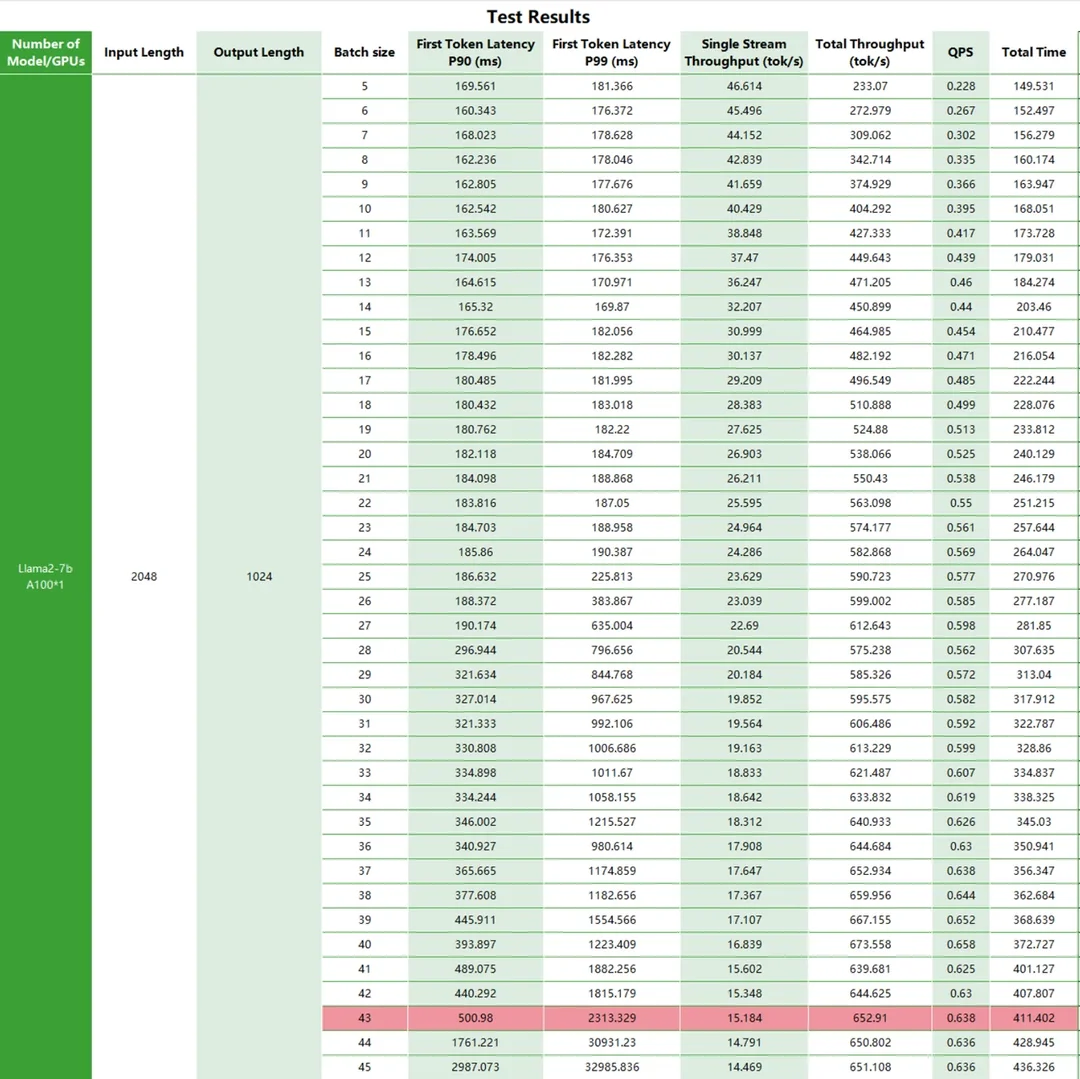
Conclusion
The NVIDIA A100 Tensor Core GPU has become a critical force in driving solutions to scientific, industrial, and big data challenges, thanks to its outstanding performance in AI training, inference, data analysis, and HPC applications. The A100's robust capabilities not only accelerate the development of essential applications like personalized medicine, conversational AI, and deep recommendation systems but also bring unprecedented scalability and flexibility to data center platforms. Through integrated technologies such as Mellanox HDR InfiniBand, NVSwitch, NVIDIA HGX A100, and the Magnum IO SDK, the A100 GPU can efficiently scale to tens of thousands of GPUs, training the most complex AI networks at unprecedented speeds.
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.