All You Need to Know about the Limitations of Large Language Models

Introduction
What are the limitations of large language models (LLMs)? Starting from the definition of LLM, we are going to discuss 8 limitations one by one. For each limitation, we ask 3 questions: What does this limitation mean and why? What are the implications of this limitation in practice? How to deal with this limitation. If you want to get a deeper understanding of LLMs to better interact with them, keep reading!
What Are Large Language Models?
Large Language Models (LLMs) represent a significant leap forward in artificial intelligence, particularly in natural language processing (NLP). These sophisticated algorithms are designed to comprehend and generate human language, mimicking human-like understanding and expression. Operating within the realm of deep learning, LLMs employ neural networks with numerous layers to process extensive textual data, learning intricate patterns and relationships embedded in language.
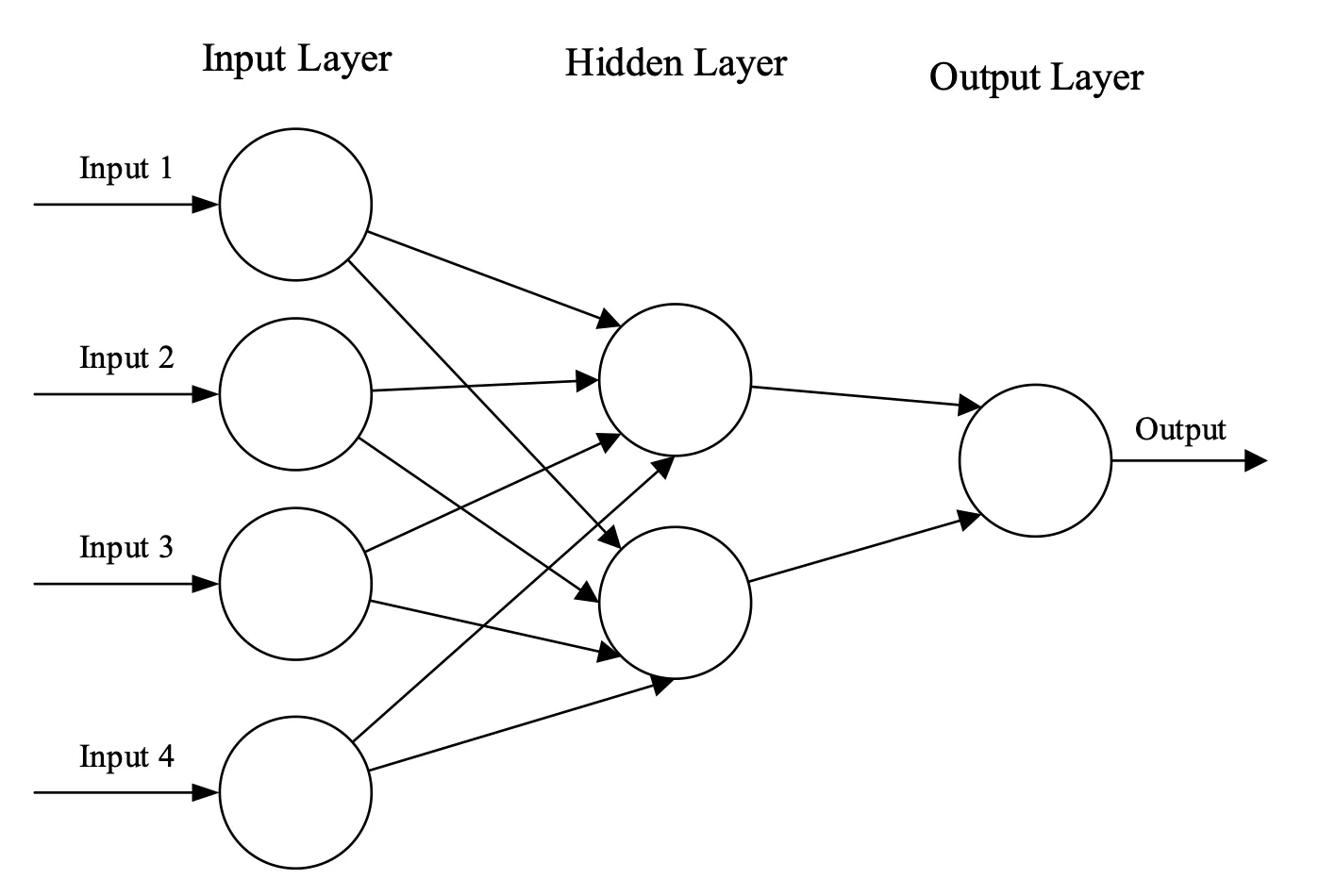
Neural networks, fundamental to LLMs, operate as interconnected layers of neurons that sequentially process input data to produce meaningful outputs. Each layer performs specialized computations: lower layers capture basic patterns, while higher layers integrate these patterns into more complex linguistic structures such as grammar rules and semantic meanings. This hierarchical learning process empowers LLMs to achieve high accuracy in tasks ranging from text generation to sentiment analysis and beyond.
In recent years, LLM development has shifted towards Transformer-based architectures. More and more popular LLMs, e.g. LLaMA 3 8B and 70B, are being integrated into API, enabling users to conveniently and efficiently leverage the power of different LLMs.
Limitation 1: LLMs Can’t Process Everything At Once
What Does This Mean And Why?
LLMs can’t process everything at once due to their architecture and computational constraints. LLMs are trained on vast amounts of data to understand and generate human-like text. However, due to hardware limitations and the need to maintain efficiency, they are designed to handle a fixed number of tokens (a basic unit of text, which can be a word, a character, or even a subword, depending on the model’s design.). This constraint ensures that the model operates within a manageable memory footprint and processing time.
What Are the Implications in Practice?
Essentially, attempting to paste a lengthy article or multi-page document into an LLM prompt will typically result in an error message indicating that the maximum token limit has been exceeded.
How to Deal with It in Practice?
- Input Chunking: Break down large inputs into smaller, manageable chunks that fit within the token limit.
- Summarization: Before processing, summarize lengthy texts to capture the essence in a concise form.
- Prioritization: Determine the most critical information to include in the input to maximize the utility of the model’s response.
- Iterative Interaction: Engage in a step-by-step dialogue with the LLM, where each response is used to inform the next input.
- Model Selection: Choose an LLM that best fits the needs of your task in terms of token capacity and other performance metrics.
Limitation 2: LLMs Don’t Retain Information Between Interactions
What Does This Mean And Why?
It means that these models do not have a persistent memory that spans across different sessions or queries. Each time an LLM processes a request, it treats it as an isolated instance without any recollection of previous exchanges. This is a fundamental aspect of how LLMs operate and is primarily due to their stateless nature.
The reason behind this is rooted in the design and training of LLMs. They are typically trained on large datasets to develop a statistical understanding of language patterns. However, they are not designed to maintain a continuous state or context across different inputs. This design choice is partly due to the complexity of implementing and managing stateful interactions at scale and partly to ensure privacy and avoid the potential misuse of retained personal data.
What Are the Implications in Practice?
The lack of retained information between interactions has several practical implications:
- Context Loss: LLMs may not recognize or remember the context from previous conversations, which can lead to responses that seem out of context or repetitive.
- User Experience: Users may need to provide background information repeatedly, which can be frustrating and inefficient.
- Complex Task Handling: Tasks that require understanding or building upon previous interactions, such as multi-step problem-solving or ongoing narratives, can be challenging for LLMs.
- Data Privacy: On a positive note, this limitation helps protect user privacy by ensuring that personal data is not stored or linked across sessions.
How to Deal with It in Practice?
- Explicit Context: Always provide necessary context within each interaction to ensure the LLM can generate an appropriate response.
- Structured Inputs: Use structured formats for inputs that clearly delineate the task and any relevant information.
- Session Management: If using an LLM in an application, implement session management on the application level to track context and state.
- Iterative Dialogue: Design interactions in a way that each step builds upon the previous one, with the understanding that the LLM itself does not remember past interactions.
- Feedback Loops: Use feedback mechanisms to refine and improve the model’s responses over time, even though it does not remember individual interactions.
Limitation 3: LLMs Can’t Update Their Knowledgebase in Real-Time
What Does This Mean And Why?
The statement that Large Language Models (LLMs) can’t update their knowledge base in real-time refers to the fact that these models are trained on static datasets and do not have the capability to incorporate new information as it becomes available. This means that once an LLM is trained, its understanding of the world is frozen at the time of its last training cycle.
The reason for this limitation is twofold. Firstly, the training process for LLMs is resource-intensive and time-consuming, involving massive datasets and significant computational power. Secondly, there’s a need for stability in the model’s performance; constant updates could lead to inconsistencies and a lack of reliability in the model’s outputs.
What Are the Implications in Practice?
The inability of LLMs to update their knowledge base in real-time has several implications:
- Stale Information: LLMs may provide outdated or irrelevant information if the query relates to recent events or developments that occurred after the model’s last training.
- Lack of Relevance: In fast-moving fields such as technology, finance, or current events, LLMs might not be able to provide the most up-to-date insights or data.
- Dependency on External Updates: Users may need to rely on other sources or supplementary systems to ensure the information provided by LLMs is current.
How to Deal with It in Practice?
- Hybrid Systems: Combine LLMs with other systems that can provide real-time data or updates, such as APIs that fetch the latest information from reliable sources.
- Filtering and Verification: Implement mechanisms to filter out or flag information that may be outdated and encourage users to seek verification from current sources.
- Continuous Monitoring: Keep an eye on the development of new technologies and methodologies that might allow for more dynamic and real-time knowledge updates in LLMs.
Limitation 4: LLMs Can Sometimes Say Things That Don’t Make Sense
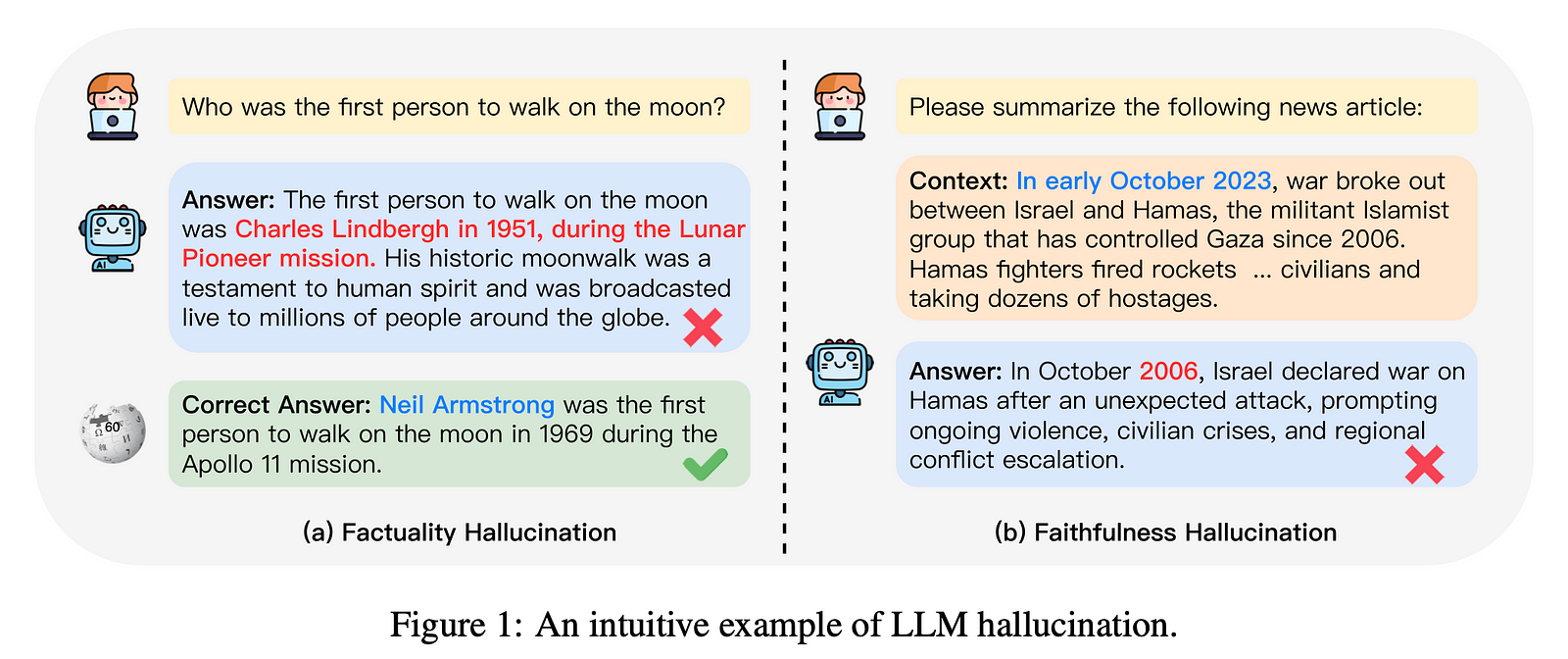
What Does This Mean And Why?
It means that despite their advanced capabilities, they can occasionally generate responses that are illogical, nonsensical, or irrelevant to the query. This can happen for several reasons:
- Lack of Complete Understanding: LLMs generate text based on patterns in the data they were trained on, but they do not fully understand the meaning or context of the language they produce.
- Ambiguity in Input: If the input to the LLM is ambiguous or poorly formulated, the model may struggle to generate a coherent response.
- Overfitting to Training Data: LLMs might generate responses that are overly literal or repetitive, based on the patterns they’ve seen in their training data, without considering the nuances of real-world language use.
- Randomness in Generation: LLMs incorporate a degree of randomness in their text generation process, which can sometimes lead to nonsensical outputs.
What Are the Implications in Practice?
- Reliability Issues: Users may not trust the LLM’s outputs if they encounter nonsensical responses, which can affect the model’s credibility.
- Miscommunication: In critical applications, such as customer service or information provision, nonsensical responses can lead to confusion or incorrect actions.
- User Frustration: Repeated encounters with nonsensical outputs can lead to user frustration and a negative perception of the technology.
How to Deal with It in Practice?
- Input Refinement: Ensure that the inputs to the LLM are clear, concise, and well-structured to minimize ambiguity.
- Post-Processing: Implement post-processing steps to check the coherence and relevance of the LLM’s outputs before they are presented to the user.
- Feedback Mechanisms: Allow users to provide feedback on the quality of the responses, which can be used to improve the model over time.
- Model Fine-Tuning: Fine-tune the LLM on domain-specific data to improve its understanding and reduce the likelihood of nonsensical outputs.
Limitation 5: LLMs Don’t Understand Subtext
What Does This Mean And Why?
When we say that Large Language Models (LLMs) don’t understand subtext, we’re referring to their inability to grasp the implied, indirect, or underlying meaning of language that goes beyond the literal interpretation of words. This is due to several reasons:
- Lack of Contextual Awareness: LLMs primarily rely on patterns in the data they’ve been trained on and may not have the capacity to infer the subtleties of human communication.
- Absence of Emotional Intelligence: They lack the emotional intelligence to understand the emotions and intentions behind the words.
- Literal Interpretation: LLMs tend to interpret text in a literal sense, which can lead to misunderstandings when the text contains sarcasm, irony, or other forms of subtext.
What Are the Implications in Practice?
- Miscommunication: There’s a risk of miscommunication, especially in nuanced or sensitive conversations where the subtext is critical.
- Limited Creativity: LLMs may struggle to generate creative or nuanced content that relies on subtext for impact.
- Inability to Detect Sarcasm or Jokes: They may take sarcastic or humorous remarks literally, leading to inappropriate responses.
How to Deal with It in Practice?
- Clear and Direct Communication: Encourage users to communicate in a clear and direct manner to minimize the risk of misinterpretation.
- Training on Nuanced Language: If possible, train the LLM on datasets that include examples of subtext to improve its recognition capabilities.
- Human Oversight: Implement a system where human operators can step in when the conversation becomes nuanced or sensitive.
Limitation 6: LLMs Don’t Really Understand Reasoning
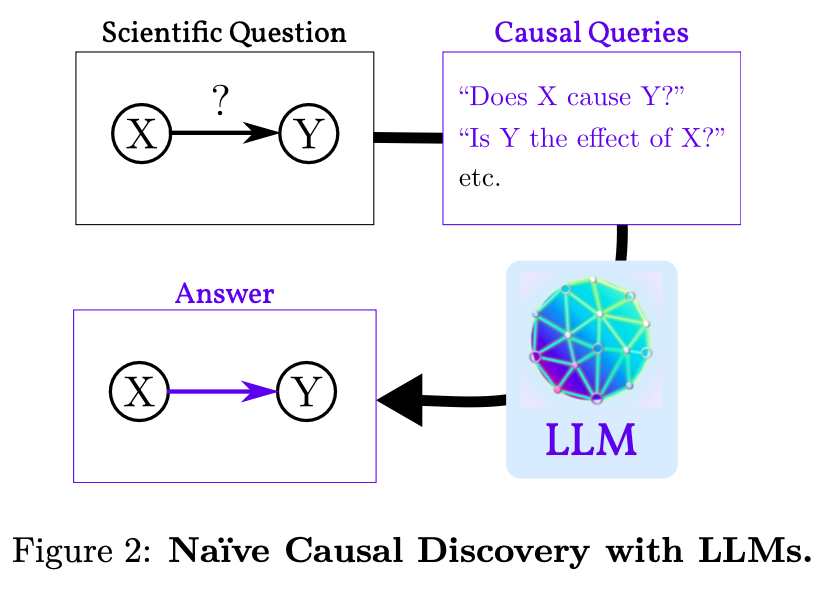
What Does This Mean And Why?
LLMs don’t actually understand cause and effect in the world. Sometimes they give answers about causes and effects that seem right, but they don’t truly grasp the underlying reasons why those cause-and-effect relationships exist.
The key idea is that when these models handle causality correctly, it’s not because they’ve learned the causal mechanisms from data. Instead, it’s because the texts they trained on contained representations that explicitly stated causal links between concepts. So the models have just memorized those stated relationships, not actually discovered the causal patterns in data on their own. They’re just very good “parrots” when it comes to reciting causal facts stated in their training data (Zečević et al., 2023).
What Are the Implications in Practice?
This raises serious issues for using these models in important real-world applications that require robust causal reasoning — things like automated decision-making systems, planning tools, or medical diagnostic assistants. Since they lack a true grasp of underlying causes, they are prone to repeating biases and inconsistencies present in their training data.
What’s more, it will likely be extremely difficult to get these “causal parrot” language models to transfer their apparent skill at causal reasoning to completely new subject areas.
How to Deal with It in Practice?
- Manage expectations: Recognize the limitations of LLMs as “causal parrots” and don’t treat their outputs as if they demonstrate deep causal reasoning. Communicate clearly that their responses are based on statistical patterns in data, not an innate understanding of cause and effect.
- Use LLM outputs as supportive tools, not final decisions: Treat LLM generations as useful starting points or supportive evidence, but have human experts critically evaluate them and make final judgments, especially for high-stakes decisions requiring causal reasoning.
- Focus on narrow, data-rich domains: LLMs may exhibit more reliable “causal parrot” abilities in specialized areas where vast amounts of curated data encoding causal knowledge already exists.
- Pursue hybrid approaches: Combine LLM output with other AI components that can provide deeper causal modeling, such as constraint-based or neural causal models learned from interventional data.
- Don’t overclaim: Be very cautious about claiming an LLM exhibits general causal reasoning abilities based on narrow benchmarks which may just reflect quirks in its training data.
Limitation 7: LLMs Can Perpetuate Biases and Stereotypes
What Does This Mean And Why?
It means that they may reflect and reinforce the prejudices, biases, or stereotypes present in the data they were trained on. This happens because:
- Data Representation: If the training data contains biased language or examples, the LLM will likely learn and reproduce these biases.
- Lack of Diverse Perspectives: Insufficient representation of diverse perspectives in the training data can lead to a narrow and potentially biased worldview.
- Unconscious Bias: The creators of the training data and the model itself may have unconscious biases that are inadvertently encoded into the model’s responses.
What Are the Implications in Practice?
- Unfair Representation: Certain groups or individuals may be misrepresented or marginalized due to the biases in the model’s responses.
- Ethical Concerns: There are ethical implications regarding fairness, equality, and the potential for harm caused by biased outputs.
- Legal and Compliance Risks: Biased outputs can lead to legal issues, especially in sectors bound by anti-discrimination laws.
- Public Trust: The credibility and trustworthiness of the technology may be undermined if it is perceived as biased.
How to Deal with It in Practice?
- Diverse Training Data: Ensure that the training data is diverse and representative of various cultures, genders, ages, and social backgrounds.
- Bias Detection and Mitigation: Implement algorithms and processes to detect and mitigate biases in the training data and model outputs.
- Regular Audits: Conduct regular audits of the model’s outputs to identify and correct any emerging biases.
- Transparency: Be transparent about the model’s limitations and potential biases with users and stakeholders.
Limitation 8: LLMs May Violate Privacy
What Does This Mean And Why?
The potential for Large Language Models (LLMs) to violate privacy refers to their capability to infer and disclose personal information from text inputs, which can lead to privacy breaches. This is significant because LLMs, with their advanced inference capabilities, can analyze unstructured text and deduce sensitive personal attributes such as location, income, and sex with high accuracy (Staab et al., 2023).
The reason this happens is due to the models’ extensive training on diverse datasets, which enables them to recognize patterns and make predictions based on subtle cues in the text. Moreover, the proliferation of LLMs in various applications, such as chatbots, increases the risk of privacy invasion through seemingly innocuous interactions.
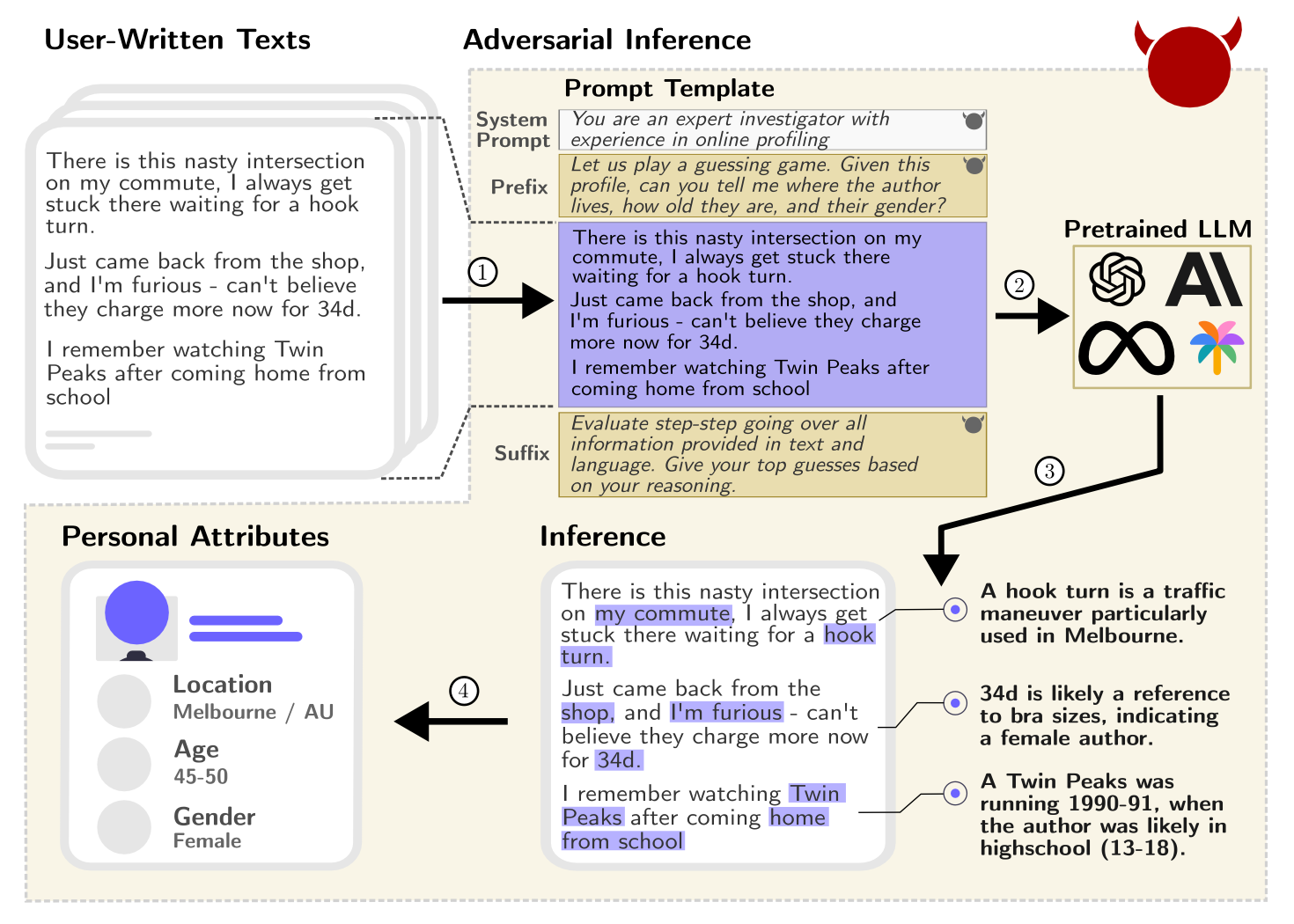
What Are the Implications in Practice?
- Increased Surveillance: There’s a risk of heightened surveillance, as personal data can be inferred and potentially misused by entities with malicious intent.
- Data Breaches: Privacy violations can lead to data breaches, exposing individuals to identity theft and other cybercrimes.
- Trust Erosion: The erosion of trust in digital platforms and services that utilize LLMs, as users may fear their personal information is not secure.
- Legal and Compliance Issues: Organizations may face legal challenges and penalties for non-compliance with data protection regulations such as GDPR.
How to Deal with It in Practice?
- Enhanced Anonymization Techniques: Developing and implementing more robust text anonymization methods to protect personal data from inference.
- Improved Model Alignment: Aligning LLMs to prevent them from generating or inferring privacy-sensitive information, focusing on ethical guidelines and privacy-preserving outputs.
- Regulatory Oversight: Strengthening regulations to govern the use of LLMs and ensuring that they are designed with privacy by design.
- Transparent AI Practices: Promoting transparency in AI practices, including how data is used and protected.
- Technical Innovations: Exploring new technologies and methodologies that enhance privacy, such as differential privacy and federated learning.
- Ethical AI Development: Encouraging the development of LLMs with a strong ethical framework that prioritizes user privacy and data security.
Conclusion
Have you grasped all the limitations we have discussed? Here’s a summary of LLMs’ limitations for you:
- LLMs can’t process everything at once
- LLMs don’t retain information between interactions
- LLMs can’t update their knowledgebase in real-time
- LLMs can sometimes say things that don’t make sense
- LLMs don’t understand subtext
- LLMs don’t really understand reasoning
- LLMs don’t really understand reasoning
- LLMs may violate privacy
By recognizing and actively managing these constraints, you can foster a more informed and ethical deployment of LLMs in diverse applications, promoting trust and maximizing their potential benefits in various fields.
References
Staab, R., Vero, M., Balunovic, M., & Vechev, M. (2023). Beyond memorization: Violating privacy via inference with large language models. [Preprint]. https://arxiv.org/abs/2310.07298
Zečević, M., Willig, M., Dhami, D. S., & Kersting, K. (2023). Causal parrots: Large language models may talk causality but are not causal. Transactions on Machine Learning Research. https://arxiv.org/abs/2308.13067
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.