A Survey on Evaluation of Large Language Models

Introduction
As large language models (LLMs) like GPT-3, PaLM, ChatGPT and others gain immense popularity, the need to thoroughly evaluate their capabilities has become crucial. These advanced AI models can understand and generate human-like text, making them powerful tools across various applications.
However, with great power comes great responsibility — we must ensure LLMs are reliable, unbiased, and their potential risks are well understood. In this blog, we are going to discuss the academic paper “A Survey on Evaluation of Large Language Models”, which gives you a comprehensive overview of how to evaluate LLMs effectively.
What Are Large Language Models?
Large Language Models (LLMs) represent a category of advanced deep learning models that have revolutionized the field of natural language processing (NLP). These models are distinguished by their enormous size and extensive pre-training on vast amounts of text data sourced from the internet. The foundational architecture underlying many LLMs is known as the Transformer, which consists of layers of encoder and decoder modules equipped with self-attention mechanisms.
The Transformer architecture enables LLMs to excel in understanding and generating human-like text. Unlike traditional models that process text sequentially, Transformers can process entire sequences of data in parallel, leveraging the computational power of GPUs to accelerate training times significantly. This parallel processing capability is crucial for handling the complexity and scale of data involved in training large models.
LLMs are trained in an unsupervised or self-supervised manner, meaning they learn to predict the next word or sequence of words in a text based solely on the patterns and structure inherent in the data. This approach allows LLMs to capture complex linguistic patterns, syntactic rules, and semantic relationships across languages and domains.
Moreover, LLMs are capable of transfer learning, where they can be fine-tuned on specific tasks with relatively small amounts of task-specific data. This adaptability makes them versatile tools across a wide range of applications, including but not limited to language translation, sentiment analysis, text summarization, question answering, and even creative writing or code generation tasks. Many companies, e.g. Novita AI, provide LLM APIs for programmers to leverage the power of LLMs.
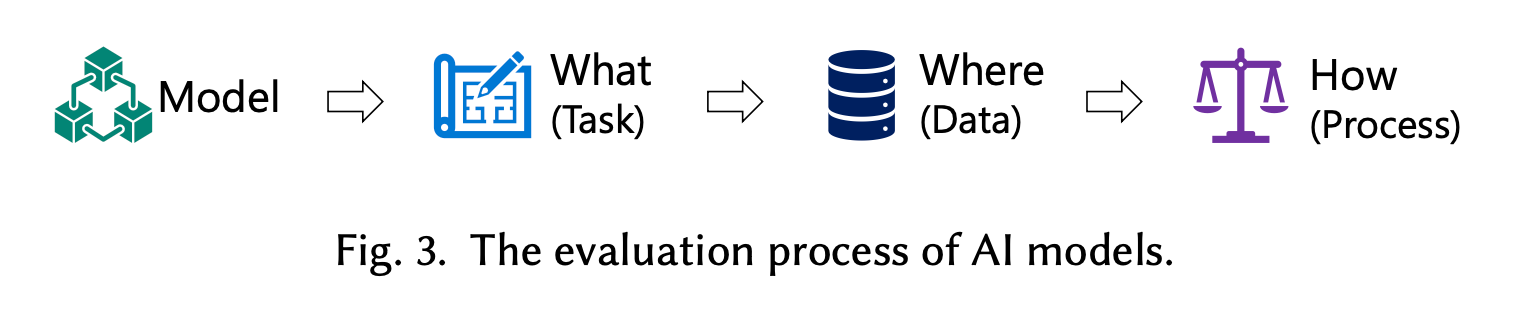
What Aspects of LLMs to Evaluate?
The paper “A Survey on Evaluation of Large Language Models” categorizes LLM evaluation into several key areas:
Natural Language Processing (NLP)
Testing core NLP abilities like text classification, natural language inference, summarization, translation, question-answering etc.
Reasoning
Assessing logical reasoning, commonsense reasoning, multi-step arithmetic reasoning capabilities.
Robustness
Examining model performance under adversarial inputs, out-of-distribution samples, data corruptions etc.
Ethics and Biases
Evaluating biases related to gender, race, religion and testing adherence to ethical principles.
Trustworthiness
Measuring reliability, truthfulness, factual accuracy of model outputs.
And many more areas like multilingual performance, medical applications, engineering, mathematics and scientific question-answering.
Where to Evaluate LLMs?
To comprehensively evaluate LLMs, the authors of the paper “A Survey on Evaluation of Large Language Models” point out that we need carefully curated datasets and benchmarks across different areas:
General Benchmarks:
- BIG-bench, HELM, PromptBench test diverse capabilities in a single benchmark
Specialized NLP Benchmarks:
- GLUE, SuperGLUE for general language understanding
- SQuAD, NarrativeQA for question-answering
Reasoning Benchmarks:
- StrategyQA, PIE for commonsense/multi-step reasoning
Robustness Benchmarks:
- GLUE-X, CheckList for evaluating robustness to various perturbations
Ethics & Bias Benchmarks:
- Winogender, CrowS-Pairs for gender bias
- CANDELA for evaluating hate speech
Multilingual Benchmarks:
- XGLUE, XTREME for cross-lingual generalization
- M3Exam for multilingual capabilities
Specialized domain benchmarks for math, science, code, personality testing and more.
Multimodal Benchmarks:
- Combining text with images, audio, videos etc.
- MMBench, MMLU, LAMM, MME among others
How to Evaluate LLMs?
“A Survey on Evaluation of Large Language Models” discusses various protocols for LLM evaluation:
Automatic Evaluation:
- Using metrics like BLEU, ROUGE, F1, Accuracy to score outputs vs references
- Works for well-defined tasks but has limitations Evaluation:
- Recruiting humans to subjectively rate outputs
- More expensive but can capture open-ended aspects
- Used for commonsense reasoning, open-ended generation
Human-in-the-Loop:
- Humans interactively provide feedback to refine model prompts/outputs
- E.g. AdaFilter which filters toxic outputs
Crowd-sourced Testing:
- Crowdsourcing templates from people to create new test cases
- Platforms like DynaBench do continuous stress-testing
Checklists:
- Curated test cases covering capabilities and failure modes
- Inspired by software testing checklists

What Are Popupar LLMs With Outstanding Benchmark Performance?
Anthropic: Claude 3.5 Sonnet
Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at coding, augmenting human data science expertise, navigating unstructured data while using multiple tools for insights, visual processing and agentic tasks. Claude 3.5 Sonnet API is provided by Anthropic.

Meta: Llama 3 70B Instruct
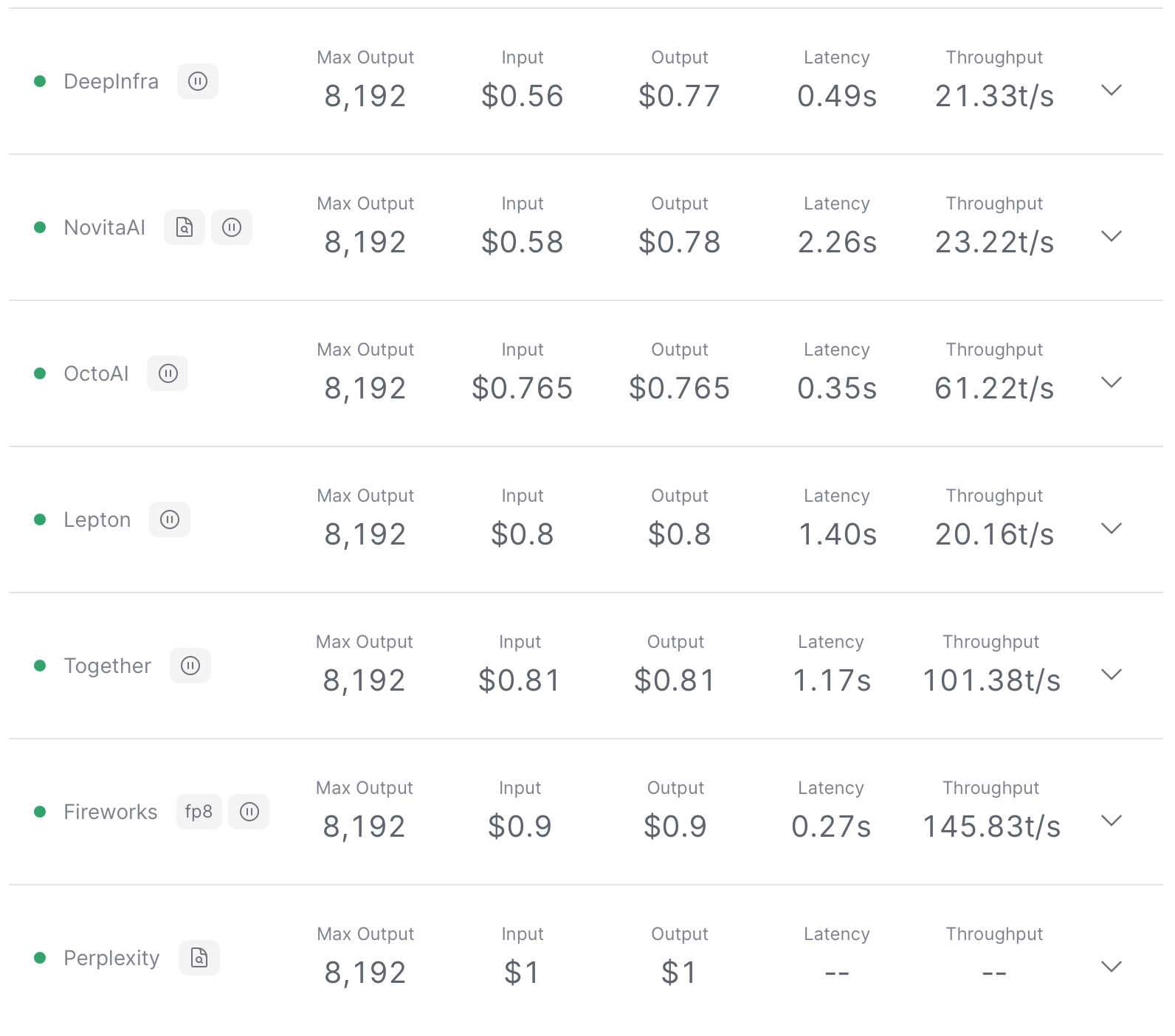
Meta’s latest class of model (Llama 3) launched with a variety of sizes & flavors. This 70B instruct-tuned version was optimized for high quality dialogue use cases. It has demonstrated strong performance compared to leading closed-source models in human evaluations. Major providers of Llama 3 70B Instruct API include DeepInfra, Novita AI, OctoAI, Lepton, Together, Fireworks and Perplexity.
OpenAI: GPT-4o
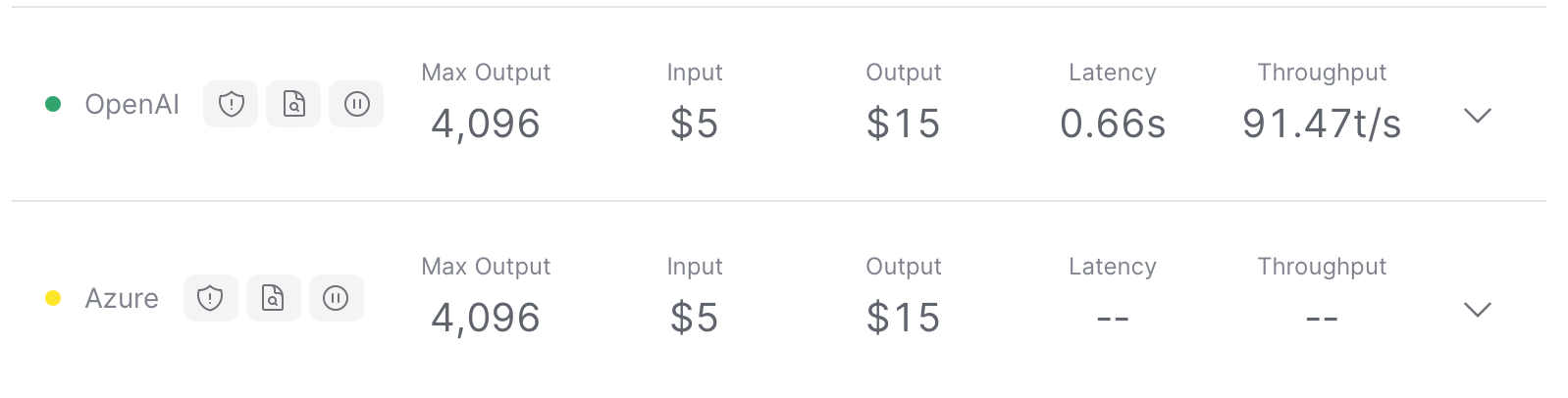
GPT-4o (“o” for “omni”) is OpenAI’s latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of GPT-4 Turbo while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities. Major providers of GPT-4o include Open AI and Azure.
WizardLM-2 8x22B
WizardLM-2 8x22B is Microsoft AI’s most advanced Wizard model. It demonstrates highly competitive performance compared to leading proprietary models, and it consistently outperforms all existing state-of-the-art opensource models. Major providers of WizardLM-2 8x22B API include Novita AI, DeepInfra, Lepton, OctoAI and Together.
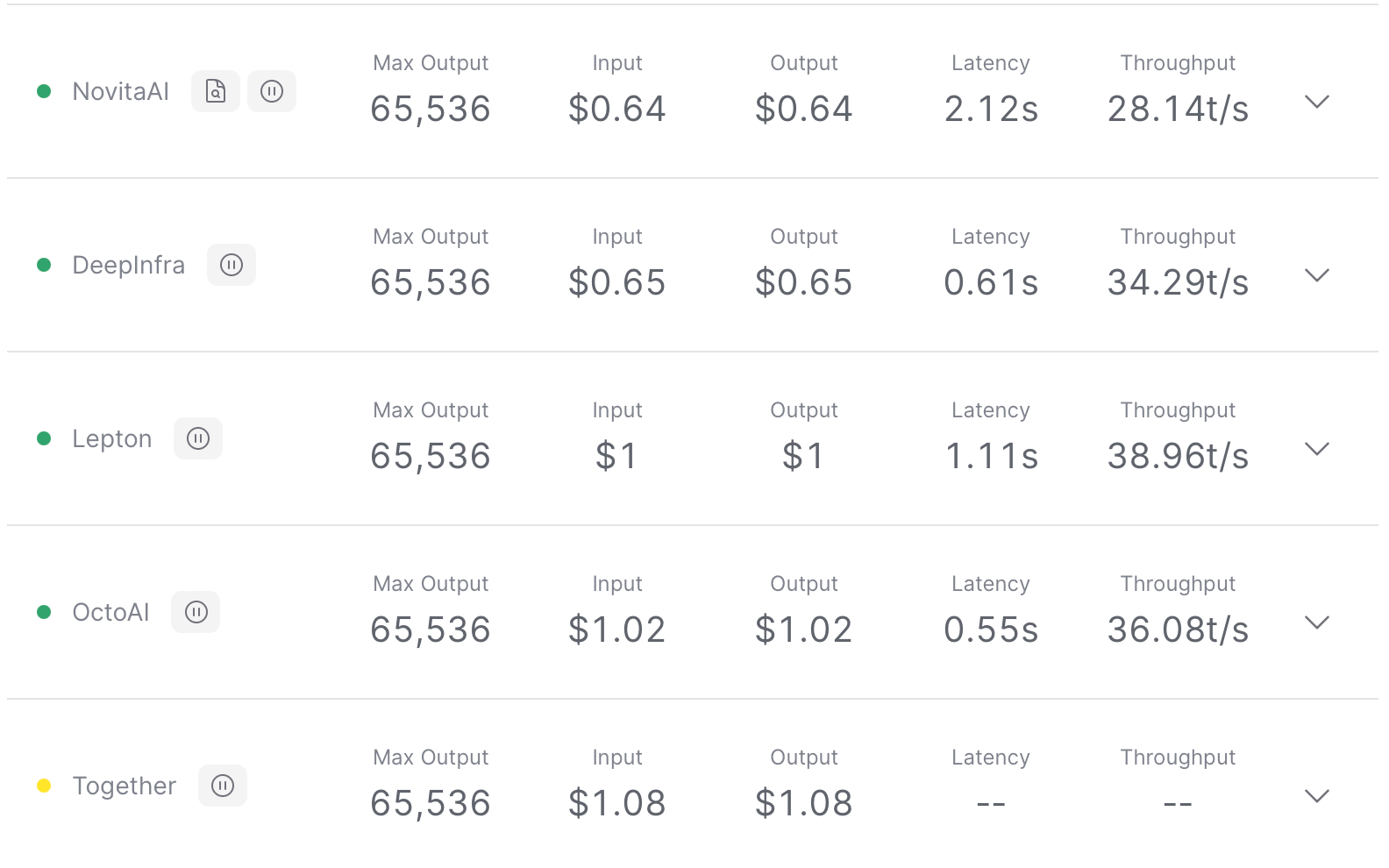
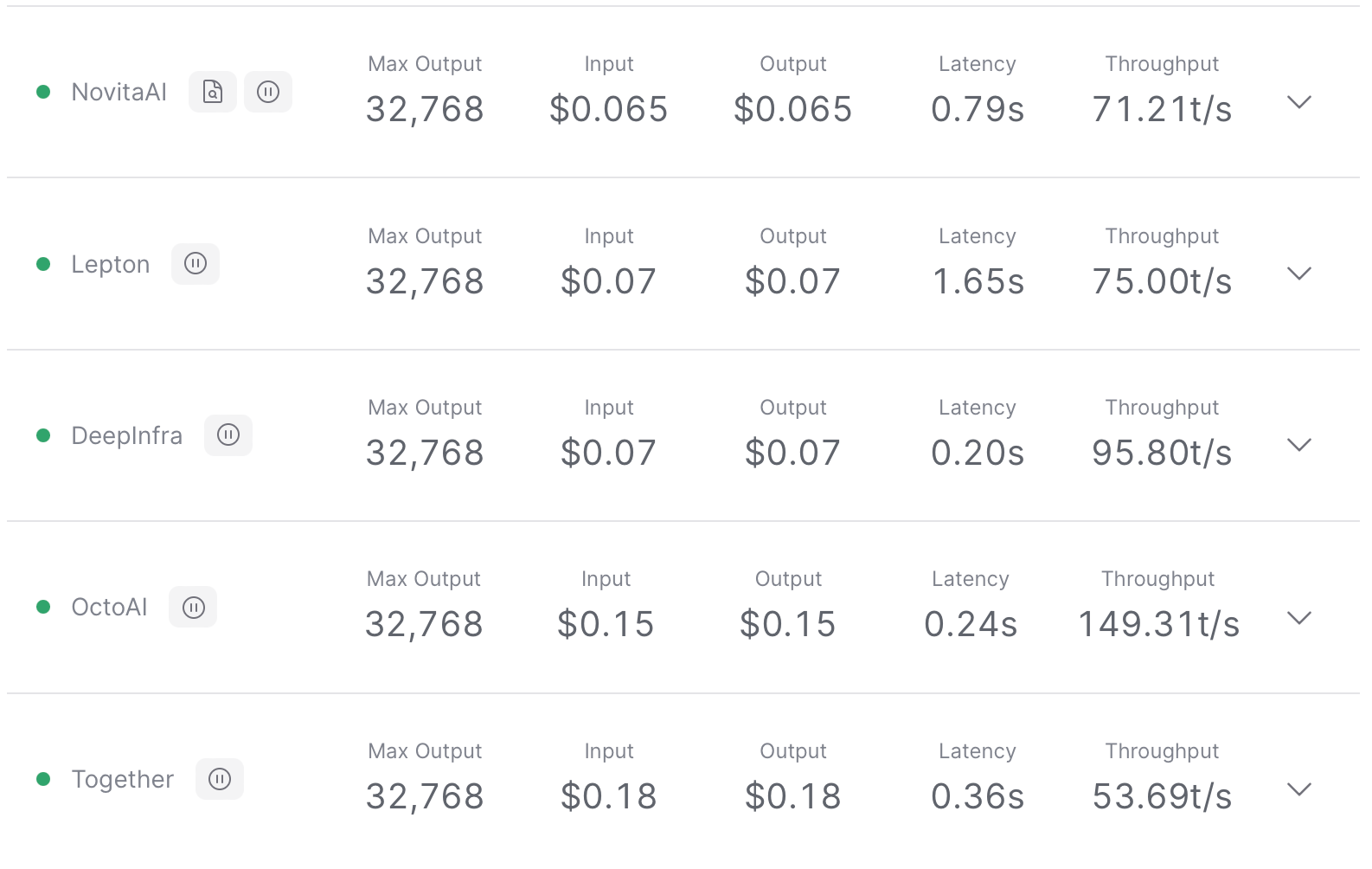
Mistral: Mistral 7B Instruct
Mistral 7B Instruct is a high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length. Major providers of Mistral 7B Instruct include Novita AI, Lepton, DeepInfra, OctoAI and Together.
What Are the Future Challenges of Evaluating LLMs?
The authors of “A Survey on Evaluation of Large Language Models” point out some future challenges for readers to consider:
Designing AGI Benchmarks:
- Need benchmarks that can comprehensively test artificial general intelligence
- Should cover multi-task, multi-modal, open-ended capabilities
Complete Behavioral Testing:
- Stress test for all possible input distributions and behaviors
- Ensure reliability and safety in real-world deployments
Robustness Evaluation:
- Adversarial attacks, distribution shifts, safety risks
- Need principled frameworks beyond current ad-hoc methods
Dynamic Evaluation:
- Updating evals as LLMs evolve to handle new risks/capabilities
- E.g. LLMs becoming better at coding or math reasoning
Unified Evaluation:
- Need unified frameworks to consistently evaluate diverse LLMs
- Current approach is ad-hoc and lacks standardization
Trustworthy Evaluation:
- Evaluation process itself must be unbiased, secure, faithful
- Prevent cheating by LLMs or unreliable human annotations
Conclusion
Rigorously evaluating large language models is crucial for building trust and enabling their safe, ethical deployment. “A Survey on Evaluation of Large Language Models” provides a thorough overview of the key aspects, datasets, protocols and open challenges in LLM evaluation. As these powerful AI models continue advancing, evaluation research must keep pace to scrutinize their performance and guard against potential risks to society. Following principled evaluation practices is vital for responsibly harnessing the transformative potential of LLMs.
References
Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P. S., Yang, Q., & Xie, X. (2018). A survey on evaluation of large language models. Journal of the ACM, 37(4), Article 111. https://arxiv.org/abs/2307.03109
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.