

引言
RoBERTa(“Robustly Optimized BERT Approach” 的缩写)是 BERT(Bidirectional Encoder Representations from Transformers)模型的进阶版本,由 Facebook AI 的研究人员创建。与 BERT 类似,RoBERTa 是一种基于 Transformer 的语言模型,它利用自注意力机制分析输入序列,并在句子中生成上下文相关的词表示。
本文将更详细地探讨 RoBERTa。
RoBERTa 与 BERT 的对比
RoBERTa 与 BERT 的一个关键区别在于,RoBERTa 使用了显著更大的数据集和更有效的训练流程进行训练。具体来说,RoBERTa 在 160GB 的文本上训练,数据量超过 BERT 所用数据集的 10 倍。此外,RoBERTa 在训练过程中采用动态掩码技术,增强了模型学习更鲁棒且更具泛化能力的词表示。
RoBERTa 在各种自然语言处理任务(如语言翻译、文本分类和问答)上,相较于 BERT 和其他领先模型表现出更优的性能。它还成为众多成功的 NLP 模型的基础模型,并在研究和工业应用中广受欢迎。
总之,RoBERTa 是一个强大且有效的语言模型,对 NLP 领域做出了重大贡献,推动了广泛应用的进展。
RoBERTa 模型架构
RoBERTa 模型与 BERT 模型共享相同的架构。它是对 BERT 的重新实现,并修改了关键超参数以及对嵌入进行了细微调整。
BERT 的通用预训练和微调流程如下图 1 所示。在 BERT 中,预训练和微调使用相同的架构,除了输出层。预训练模型参数用于初始化各种下游任务的模型。在微调过程中,所有参数都会进行调整。
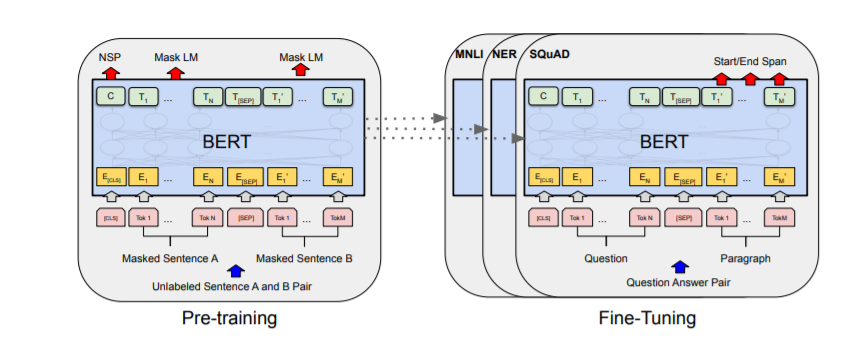
BERT 模型架构
相比之下,RoBERTa 不使用下一句预测预训练目标。相反,它使用更大的 mini-batch 和更高的学习率进行训练。RoBERTa 采用不同的预训练方案,并将字符级 BPE 词汇替换为字节级 BPE 分词器(类似于 GPT-2)。此外,RoBERTa 不需要定义哪个 token 属于哪个片段,因为它没有 token_type_ids。片段可以很容易地使用分隔 token tokenizer.sep_token (或 <sep>)进行分割。
此外,与最初用于训练 BERT 的 16GB 数据集不同,RoBERTa 在超过 160GB 的未压缩文本大数据集上进行训练。该数据集包括 BERT 中使用的 16GB 英语维基百科和图书语料库,以及来自 WebText 语料库(38 GB)、CommonCrawl News 数据集(6300 万篇文章,76 GB)和 Common Crawl 故事(31 GB)的额外数据。RoBERTa 使用这个庞大的数据集和 1024 块 V100 Tesla GPU 运行了一天进行预训练。
RoBERTa 模型的优势
RoBERTa 具有与 BERT 相似的架构,但为了提升性能,作者对架构和训练流程进行了一些简单的设计变更。这些变更包括:
- 移除下一句预测(NSP)目标:在 BERT 中,模型通过辅助 NSP 损失来训练预测文档的两个片段是否来自同一份文档。作者对有无 NSP 损失的模型版本进行了实验,发现移除 NSP 损失在下游任务上匹配或略有提升性能。
- 使用更大的批次大小和更长的序列进行训练:BERT 最初使用 256 个序列的批次大小训练 100 万步。RoBERTa 使用 2000 个序列的批次大小训练 125 步,并使用每批次 8000 个序列训练 31000 步。更大的批次大小改善了掩码语言建模目标上的困惑度以及最终任务准确率。它们也更容易通过分布式并行训练进行并行化。
- 动态改变掩码模式:在 BERT 中,掩码在数据预处理期间一次性完成,导致单个静态掩码。为了避免这个问题,训练数据被复制并以不同策略在 40 个 epoch 内掩码 10 次,导致每 4 个 epoch 使用相同的掩码。这种策略与动态掩码进行了比较,动态掩码在每次数据输入模型时生成不同的掩码。
RoBERTa 的性能
RoBERTa 模型在当时在 MNLI、QNLI、RTE、STS-B 和 RACE 任务上取得了最先进的性能,并在 GLUE 基准上展示了显著的性能提升。RoBERTa 以 88.5 的分数登顶 GLUE 排行榜。

BERT 及其后续改进的对比
如何使用 RoBERTa
Huggingface 的 Transformers 库提供了各种不同大小和针对不同任务预训练的 RoBERTa 模型。本文将重点介绍如何加载 RoBERTa 模型并执行情感分类。
我们将使用一个在特定任务数据集上微调的 RoBERTa 模型,具体是来自 Huggingface hub 的预训练模型 cardiffnlp/twitter-roberta-base-emotion。
首先,我们需要安装并导入所有必需的包,并使用 RobertaForSequenceClassification(包含分类头)加载模型,使用 RobertaTokenizer 加载分词器。
!pip install -q transformers
# 导入必要的包
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification
# 加载模型和分词器
model_name = "cardiffnlp/twitter-roberta-base-emotion"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaForSequenceClassification.from_pretrained(model_name)
# 对输入进行分词
inputs = tokenizer("I love my cat", return_tensors="pt")
# 获取 logits 并用于预测底层情感
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
# >> Output: Optimism
输出是 “Optimism”,这基于我们使用的分类模型的预定义标签是正确的。我们可以使用另一个预训练模型或微调一个模型,以获取具有更合适标签的结果。
RoBERTa 的评估结果
使用动态掩码训练
在原始 BERT 实现中,掩码发生在数据预处理期间,导致单个静态掩码。这种方法与动态掩码进行了比较,动态掩码在每次序列输入模型时生成新的掩码模式。动态掩码与静态掩码相比表现出相当或略优的性能。

BERT 静态与动态掩码的比较
基于上述发现,RoBERTa 的预训练采用了动态掩码方法。
全句子(无 NSP 损失)
在不使用 NSP 损失的情况下训练,与使用来自单个文档的文本块(文档句子)训练进行比较,发现这种配置优于最初发布的 BERTBASE 结果。此外,移除 NSP 损失在下游任务上匹配或略微提升性能。

展示 RoBERTa 有无 NSP 损失性能的表格
虽然观察到限制序列来自单个文档(DOC-SENTENCES)比合并来自多个文档的序列(FULL-SENTENCES)产生略好的性能,但 RoBERTa 选择使用 FULL-SENTENCES,以便更容易进行比较,因为 DOC-SENTENCES 格式会导致批次大小可变。
使用大批次训练
使用大批次大小训练可以加速优化并提高任务准确率。此外,分布式数据并行训练有助于大批次的并行化,进一步提高效率。在适当调整的情况下,大批次大小可以提升模型在给定任务上的性能。

RoBERTa 在不同任务上随批次大小变化的性能比较
更大的字节级 BPE
字节对编码(BPE)结合了字符级和词级表示的优点,能够有效处理自然语言语料库中典型的大词汇量。RoBERTa 与 BERT 不同,它使用一个由 50K 子词单元组成的更大字节级 BPE 词汇,无需额外的预处理或输入分词。
认识 RoBERTa 的局限性
虽然 RoBERTa 是一个强大的模型,但它并非没有局限性。以下是一些局限性:
- 计算资源:训练和微调 RoBERTa 需要大量的计算资源,包括强大的 GPU 和大内存。这使得资源有限的个人或组织难以有效利用 RoBERTa。
- 领域特异性:预训练语言模型如 RoBERTa,在没有进一步微调的情况下,可能在特定领域的任务或数据集上表现不佳。它们可能需要额外的领域特定数据训练才能达到期望的性能水平。
- 数据效率:RoBERTa 及类似模型需要大量数据进行预训练,这可能不是所有语言或领域都能提供的。这种对大量数据的依赖限制了它们在数据稀缺或获取成本高昂的场景中的适用性。
- 可解释性:RoBERTa 的黑盒特性使得解释模型如何得出预测变得困难。理解模型的内部工作原理并诊断错误或偏差可能具有挑战性,尤其是在复杂应用或敏感领域。
- 微调挑战:虽然针对特定任务微调 RoBERTa 可以提升性能,但这需要专业知识和实验来选择正确的超参数、数据增强技术和训练策略。这个过程可能耗时且资源密集。
- 偏差与公平性:预训练语言模型如 RoBERTa 可能继承训练数据中存在的偏差,导致有偏差或不公平的预测。解决偏差并确保 AI 模型的公平性仍然是一个重大挑战,需要谨慎的数据整理和模型设计考虑。
- 分布外泛化:RoBERTa 可能难以泛化到分布外数据,或处理与其训练数据显著不同的场景。这一局限性可能影响 RoBERTa 在现实世界应用中的鲁棒性和可靠性,因为数据分布变化很常见。
要克服这些局限性,您可以选择更先进的模型,例如最近发布的 Llama 3。或者,您可以应用 novita.ai LLM API 密钥 以低成本无缝集成到现有系统:

novita.ai LLM API 提供的模型

结论
RoBERTa 在自然语言处理方面取得了显著进展,它在 BERT 的基础上,利用更大的训练数据集和更先进的技术(如动态掩码和移除下一句预测目标)进行改进。这些增强,加上字节级 BPE 分词器和更大的批次大小,使 RoBERTa 能够在各种 NLP 任务上实现优越的性能。虽然它需要大量的计算资源和微调专业知识,但 RoBERTa 在该领域的影响是深远的,树立了新的基准,并成为研究和工业应用的多功能模型。
novita.ai,一站式平台,为您提供无限创造力,接入 100+ API。从图像生成、语言处理到音频增强和视频编辑,按需付费,价格低廉,让您在构建自己产品的同时免去 GPU 维护的烦恼。免费试用。
推荐阅读



