What Are the Challenges and Applications of Large Language Models?

Introduction
What are the challenges and applications of large language models? Referencing the work “Challenges and Applications of Large Language Models” by Kaddour, J., Harris, J., Mozes, M., Bradley, H., Raileanu, R., & McHardy, R., this blog is going to discuss this question in a plain and simple way. Let’s begin our exploration journey with a detailed explanation of what large language models are.
What Are Large Language Models?
Large Language Models (LLMs) represent a significant advancement in natural language processing (NLP) within the realm of artificial intelligence. At their core, LLMs are sophisticated algorithms designed to understand, generate, and manipulate human language in a manner that simulates human-like comprehension and expression. These models are closely tied to the broader fields of deep learning, where they utilize neural networks with many layers (hence the term “deep learning”) to process vast amounts of textual data and learn intricate patterns and relationships.
Processing Text Data
LLMs and image or sound processing AI models share similarities in their overarching goal of processing specific types of data — textual, visual, and auditory — to perform tasks like understanding, generation, and classification. Both types of models leverage deep learning techniques, utilizing neural networks to learn patterns and features from their respective data domains. However, the key differences lie in their input data and the nature of the tasks they perform. LLMs, such as those based on Transformer architectures, excel in understanding and generating natural language text, utilizing mechanisms like attention to process sequences of words effectively. In contrast, image processing AI models typically involve convolutional neural networks (CNNs), which specialize in extracting spatial hierarchies and features from images, enabling tasks like object detection and image classification.
Definition of Neural Network
Neural network layers play a crucial role in LLMs by enabling them to process and understand complex patterns in language data. A neural network is a type of computer program that learns and makes decisions, inspired by how our brains work. Imagine it as a series of connected boxes, where each box does a specific job. These boxes are called neurons.
Here’s how it works:
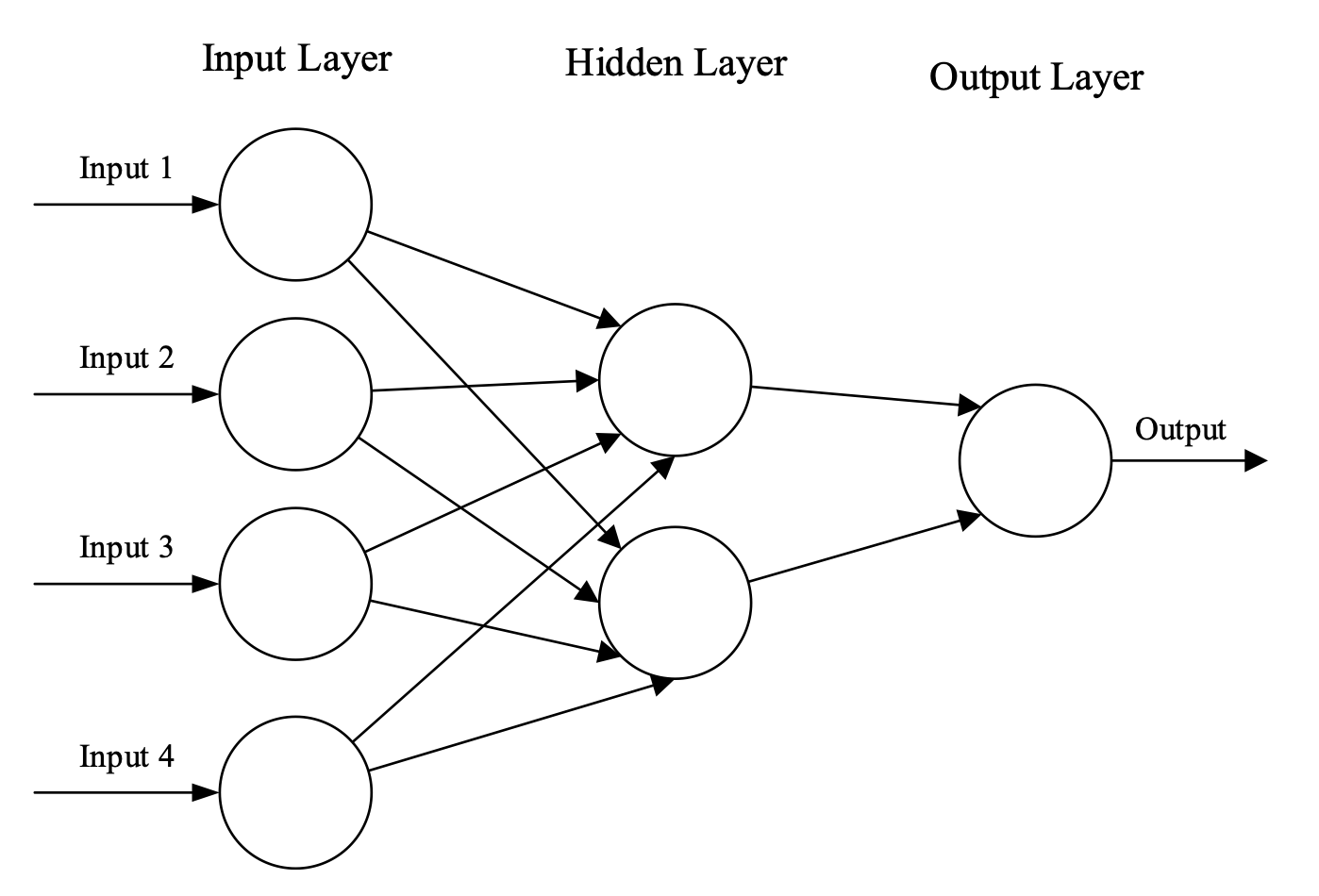
- Input: You start with some information, like numbers representing pixels in a picture or words in a sentence. These go into the first layer of neurons.
- Processing: Each neuron in the first layer does some math with the input it gets. It passes its result to neurons in the next layer.
- Layers: The network has multiple layers — each one taking the output from the previous layer and doing more math on it. These layers help the network to understand more complex things about the input.
- Output: Finally, after passing through all the layers, the network gives you an answer. For example, it might tell you what object is in a picture or translate a sentence into another language.
- Learning: Neural networks learn by adjusting how they do their math. They get better at their tasks by practicing with lots of examples. This adjustment happens automatically as the network gets more data and feedback.
Neural Network and LLM Algorithms
Different neural network architectures vary significantly in their structure based on factors such as types of layers, connections between layers and depth and width of layers.
LLM algorithms, like those based on Transformer architectures, consist of multiple layers of interconnected nodes (neurons). Each layer in the network performs a specific task: lower layers capture basic patterns such as word sequences, while higher layers integrate these patterns into more abstract concepts like grammar rules or semantic meaning. This layered approach allows LLMs to learn hierarchical representations of language, where each layer refines and builds upon the representations learned by the previous layers. Ultimately, these layers work together to enhance the model’s ability to generate coherent text, understand nuances in language, and perform various natural language processing tasks with high accuracy.
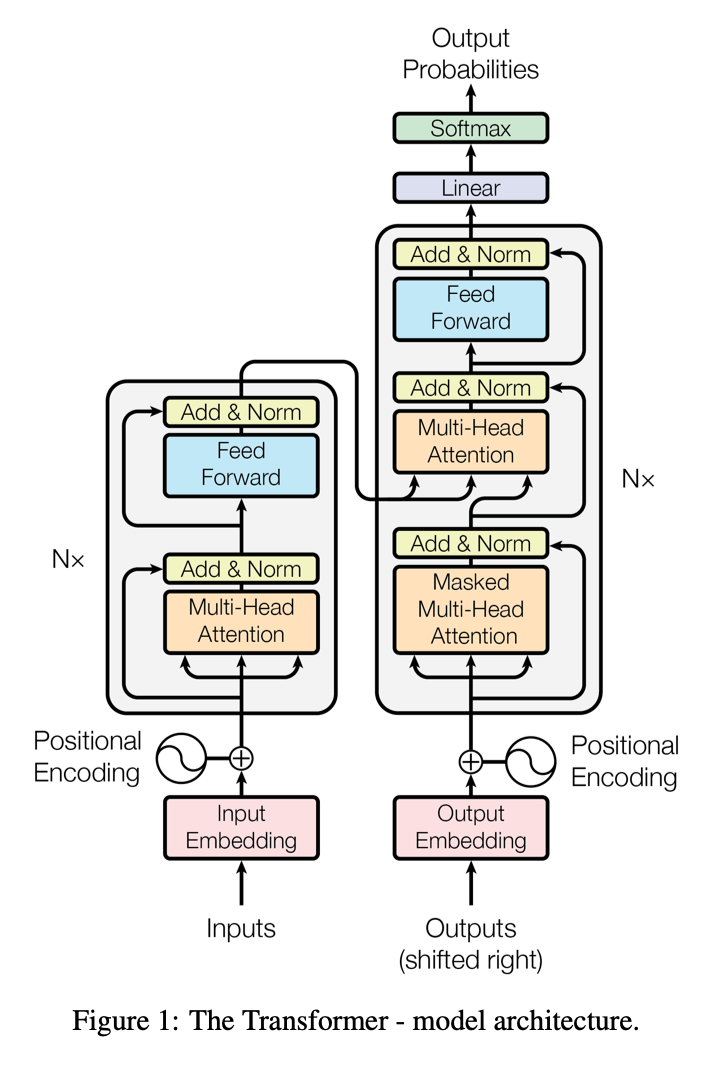
Evolving LLM Algorithms
Traditionally, LLMs were built using algorithms like Recurrent Neural Networks (RNNs) or Long Short-Term Memory networks (LSTMs), which can handle sequential data and capture dependencies over time. However, modern LLMs have largely transitioned to Transformer architectures. Transformers, introduced by Vaswani et al. in 2017, revolutionized NLP with their ability to parallelize computation across sequences, making them highly efficient for processing large datasets. Popular examples of LLMs include OpenAI’s GPT (Generative Pre-trained Transformer) series, Google’s BERT (Bidirectional Encoder Representations from Transformers) and Meta AI’s LLaMA series, which have set benchmarks in language understanding and generation tasks.
What Are the Challenges in LLMs?
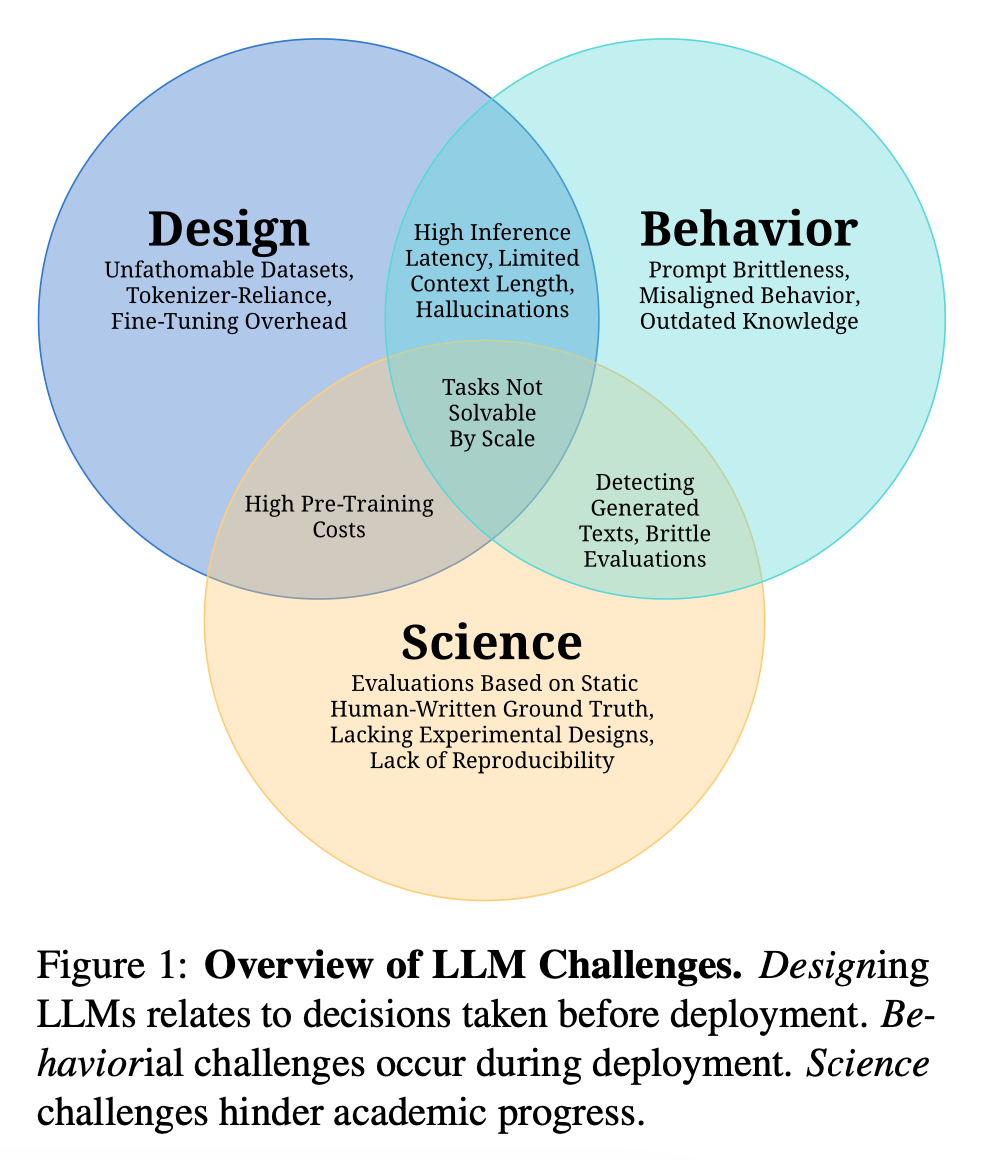
Design Challenges
- Unfathomable Datasets: The scale of data used for pre-training LLMs is often too vast for manual quality checks, leading to reliance on heuristics that can introduce biases or inaccuracies.
- Tokenizer-Reliance: Tokenization processes can introduce computational overhead, language dependence, and information loss, affecting model performance.
- High Pre-Training Costs: Training LLMs requires significant computational resources, which can be costly and energy-intensive.
- Fine-Tuning Overhead: Adapting pre-trained models to specific tasks can be resource-intensive due to the large memory requirements of LLMs.
Behavioral Challenges
- Prompt Brittleness: Small changes in the input prompt can lead to significant variations in model output, affecting reliability.
- Hallucinations: LLMs can generate factually incorrect information that is difficult to detect due to its fluent presentation.
- Misaligned Behavior: Outputs may not align with human values or intentions, potentially leading to negative consequences.
Science Challenges
- Outdated Knowledge: LLMs may contain factual inaccuracies or outdated information that is costly to update.
- Brittle Evaluations: The performance of LLMs can be uneven and sensitive to changes in evaluation protocols or prompts.
- Lack of Reproducibility: The non-deterministic nature of training and inference in LLMs can make it difficult to reproduce results.
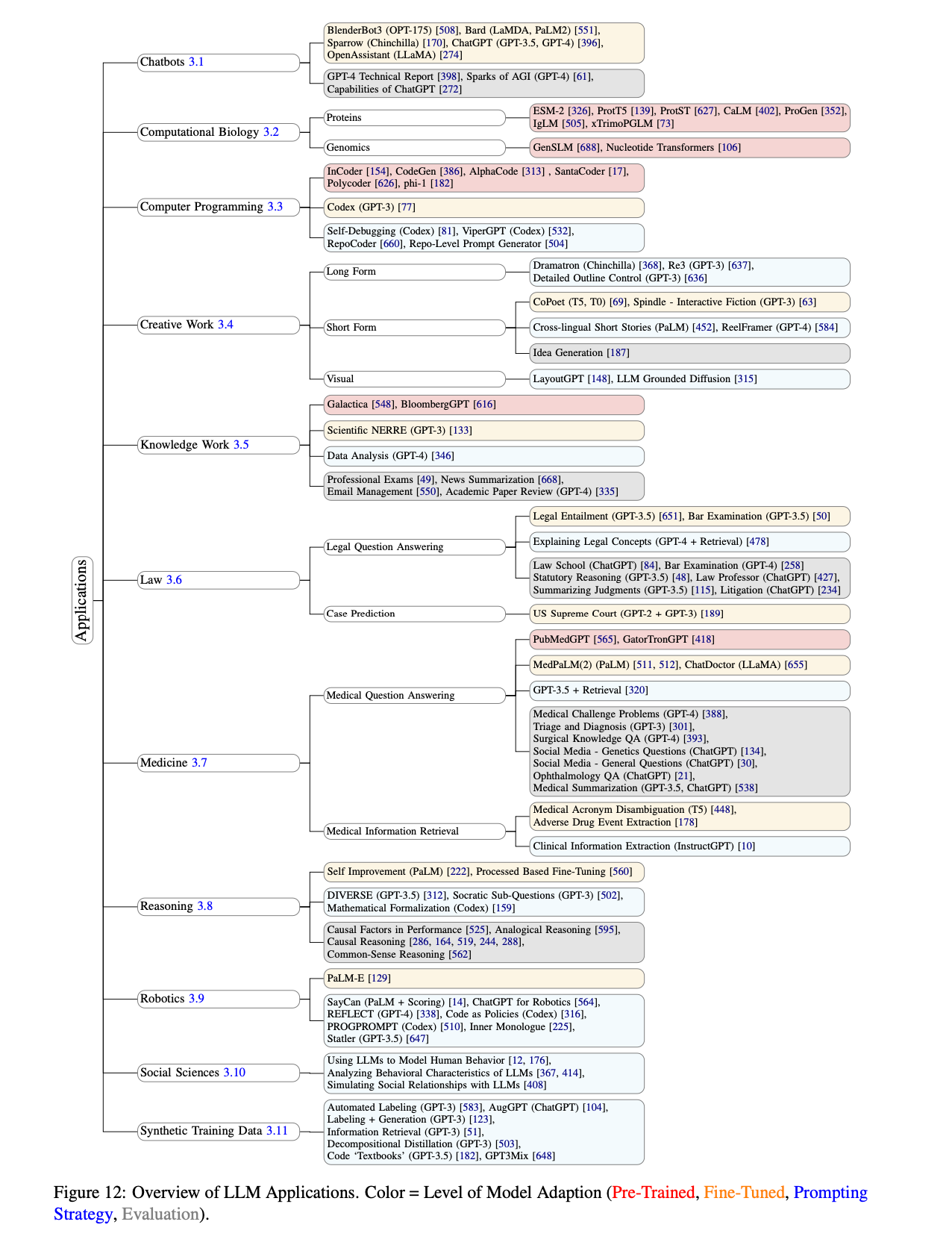
The paper explores a wide range of applications across various fields, including chatbots, computational biology, computer programming, creative work, knowledge work, law, medicine, reasoning, robotics, social sciences, and synthetic data generation.
What Are the Applications of LLMs?
Chatbots
- LaMDA and Bard: Google’s LaMDA models, with up to 137B parameters, are used in chatbot services like Bard, focusing on safety and factual grounding.
- Sparrow: A chatbot based on the Chinchilla LLM, fine-tuned using RLHF for helpfulness, correctness, and harmlessness, incorporating external knowledge through retrieval models.
Computational Biology
- Protein Embeddings: Models like ESM-2 and ProtT5 generate embeddings from protein sequences for structure prediction and classification.
- Genomic Analysis: Models such as GenSLM and Nucleotide Transformers predict genomic features and understand the effects of mutations directly from DNA sequences.
Computer Programming
- Code Generation: Specialized models like Codex generate Python functions from doc strings, with capabilities for standalone code generation.
- Code Infilling: Models such as InCoder and SantaCoder modify or complete existing code snippets based on the context.
Creative Work
- Story and Script Generation: Tools like Dramatron and GPT-3 are used for long-form story generation, while CoPoet and Spindle are applied for poetry and interactive fiction.
- Visual Layout: LayoutGPT uses LLMs to generate CSS layouts for image generation models, guiding the creative process in visual design.
Knowledge Work
- Professional Services: LLMs are evaluated on tasks from the Uniform CPA Examination, showing potential for assisting in financial, legal, and ethical tasks.
- Data Analysis: GPT-4, combined with a modular prompting framework, performs data analysis, though it currently underperforms experienced human analysts.
Law
- Legal Question Answering: GPT-3.5 and GPT-4 are used for answering legal questions and demonstrating reasoning about legal facts and statutes.
- Case Prediction: Models predict case outcomes and generate legal text, though the literature on LLMs in this area is sparse.
Medicine
- Medical Question Answering: Models like Med-PaLM and PubMedGPT are specialized for medical question answering, with capabilities for handling clinical information.
- Clinical Information Extraction: LLMs are applied to extract medication dosage, medical acronyms, and other clinical information from medical notes.
Reasoning
- Mathematical Reasoning: Models are evaluated on their ability to generate accurate reasoning steps on word-based math problems, with techniques like process-based fine-tuning improving performance.
- Algorithmic Reasoning: LLMs are applied to tasks requiring complex multi-step reasoning and planning.
Robotics
- High-Level Planning: LLMs like PaLM-E incorporate visual inputs for long-horizon planning in robotics, providing contextual knowledge for task execution.
- Code Generation for Robotics: ChatGPT is combined with predefined function libraries to generate code for robotic tasks, enhancing human-on-the-loop applications.
Social Sciences & Psychology
- Modeling Human Behavior: LLMs simulate human behavior in various psychological experiments, offering insights into behavioral changes and social interactions.
- Analyzing Behavioral Characteristics: LLMs are assessed for personality traits, showing alignment with human personality scores and the influence of training data on biases.
- Simulating Social Relationships: LLMs model interactions between artificial agents, observing emergent social behaviors in digital environments.
Synthetic Data Generation
- Automated Labeling: LLMs like GPT-3 are used to label datasets more cost-effectively, with potential benefits and risks depending on the generation approach.
- Data Augmentation: Techniques like GPT3Mix generate synthetic data to augment existing datasets, combining data augmentation with knowledge distillation.
How to Leverage the Power of LLMs for My Project?
The most efficient way to leverage the power of LLMs for your project is to integrate LLM API.
Experiencing Multiple LLMs at A Time
Novita AI provides developers with LLM API equipped with many LLM choices, including the trendy LLaMA series.
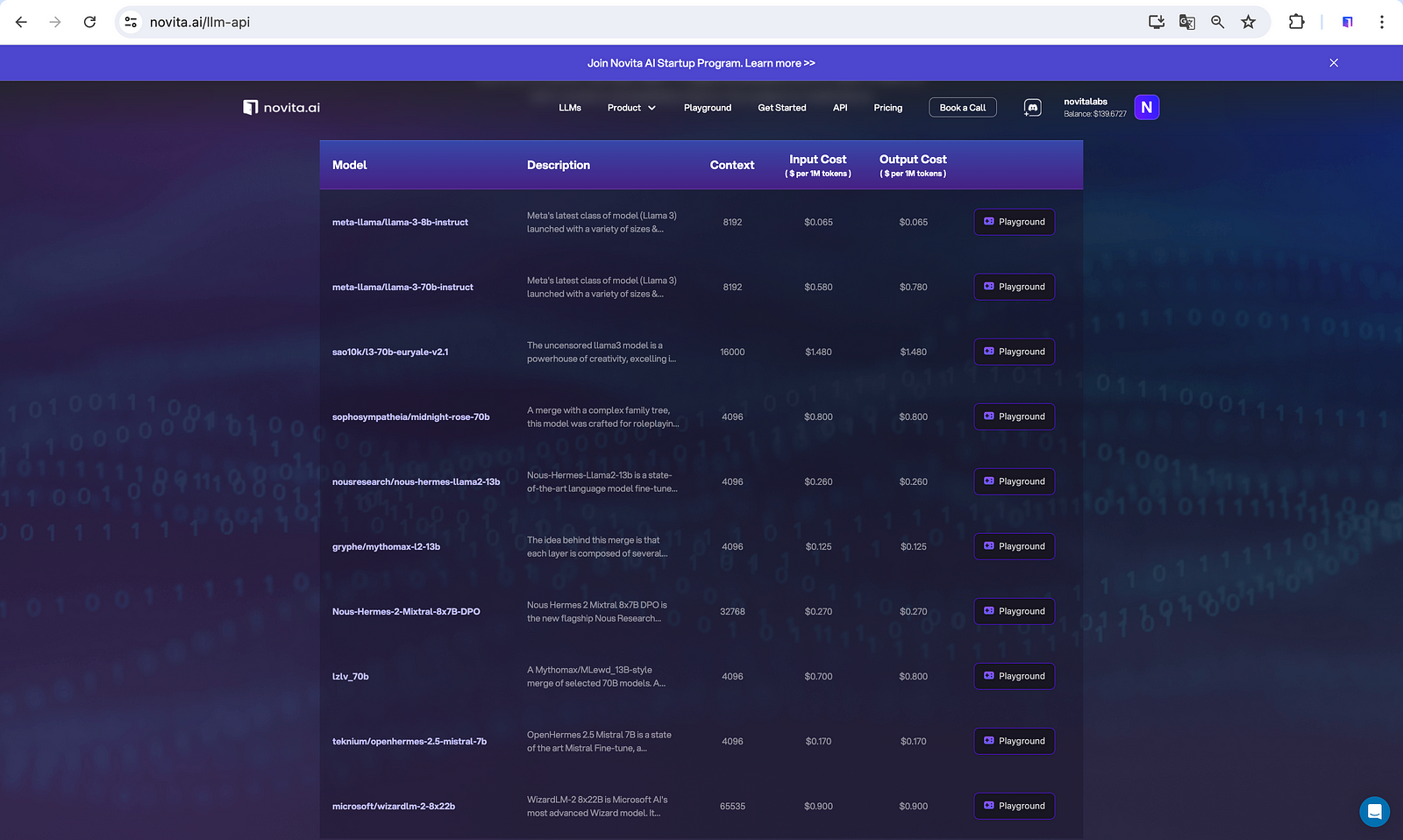
Adjusting Parameters for Perfecting LLMs’ Performances
Moreover, to cater to different needs, Novita AI offers personalized functions, e.g. parameter adjustment, system prompts input, and character import.
Parameter adjustment feature allows users to fine-tune various aspects of the AI’s performance. For instance, you can adjust top P, temperature, max tokens and presence penalty.
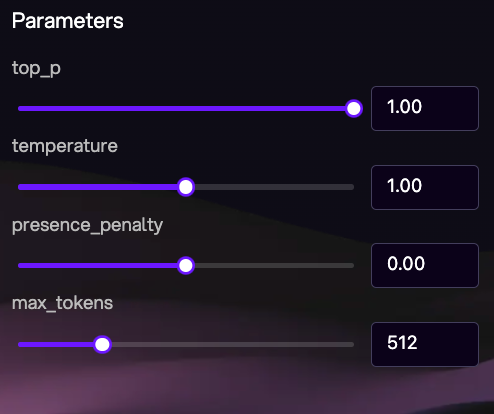
Top P: Instead of selecting the most probable word (greedy selection), top P sampling restricts the model’s choice to the top P percentage of the probability mass.
Temperature: A lower temperature (less than 1) makes the model’s choices sharper, favoring more probable words and resulting in more conservative, predictable text. A higher temperature (greater than 1) increases the randomness, allowing the model to explore less likely word choices and potentially generate more creative or diverse text.
Max Tokens: This parameter sets a hard limit on the length of the output generated by the model, measured in the number of tokens (words or subwords, depending on the model’s tokenizer).
Presence Penalty: The presence penalty is designed to reduce repetitiveness in the model’s generated text by penalizing the repeated selection of words. It works by increasing the effective probability of other words in the vocabulary, thus encouraging the model to use a wider variety of vocabulary and avoid repeating the same words or phrases.
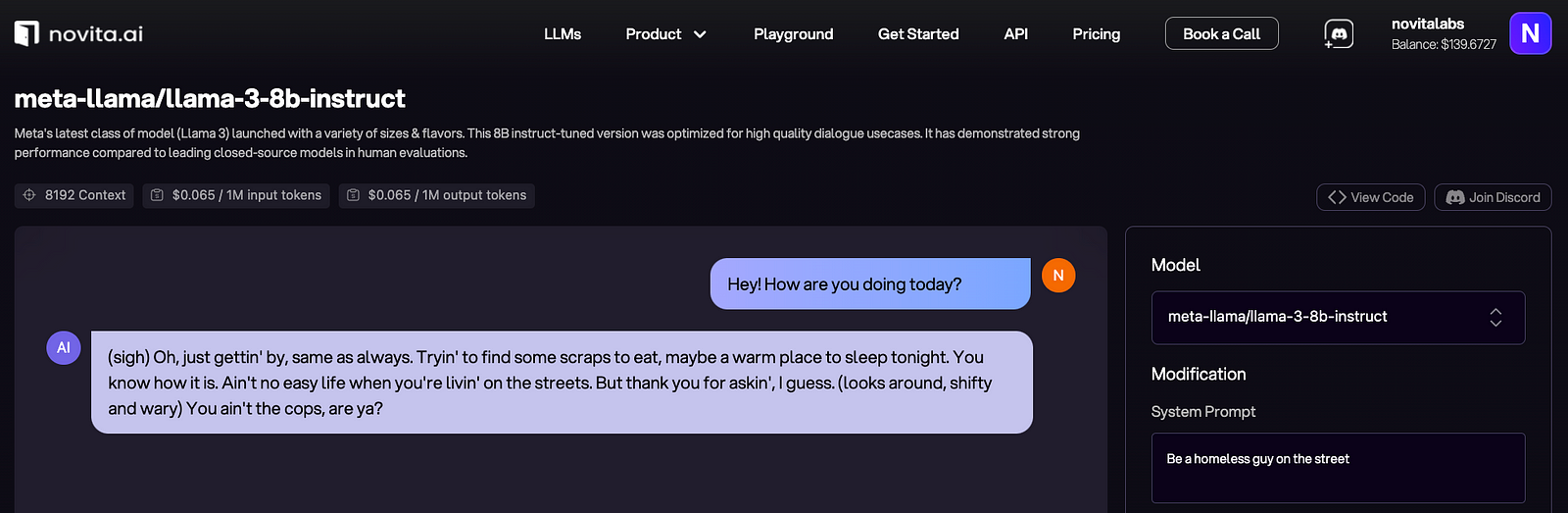
Inputting System Prompts for Specific Scenarios
With Novita AI LLM API, users have the ability to input custom prompts or cues that the AI can recognize and respond to. This is particularly useful for users who want the AI to integrate seamlessly with their workflow or to create a more immersive role-playing experience. For example, a researcher might set up specific prompts related to their field of study, while a writer could use prompts to generate ideas for their next novel.
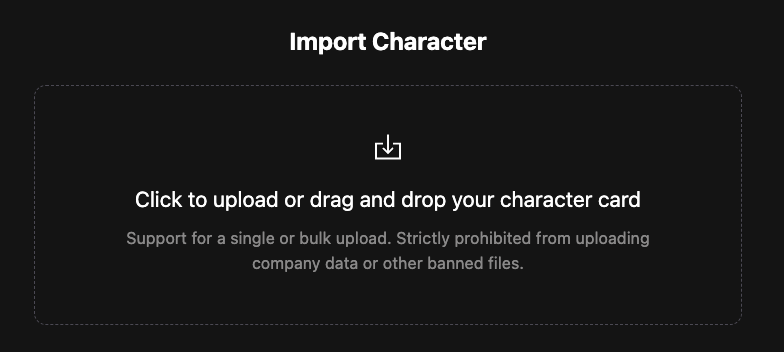
Importing Character for More Fun
For users who enjoy role-playing or who want a more personalized interaction, the character import function of Novita AI’s LLM API enables them to upload a profile or set of characteristics for the AI to adopt. The AI then uses this information to engage in a more character-specific dialogue, providing a unique and immersive experience.
You are welcome to chat with our available LLMs for free on our LLM Playground!
Conclusion
In conclusion, LLMs represent a groundbreaking advancement in artificial intelligence, leveraging deep learning to understand and generate human language with exceptional accuracy. Built on Transformer architectures, these models excel in processing vast textual data and have found diverse applications in fields such as chatbots, medicine, and robotics.
However, challenges such as data quality, computational costs, and managing model behavior underscore ongoing research needs. Addressing these challenges will be crucial for maximizing the reliability and ethical use of LLMs across different domains. As research progresses, optimizing LLMs’ capabilities holds significant promise for revolutionizing language processing and its integration into various technologies.
References
Kaddour, J., Harris, J., Mozes, M., Bradley, H., Raileanu, R., & McHardy, R. (2023). Challenges and Applications of Large Language Models. [Preprint]. arXiv:2307.10169 [cs.CL]
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.