Vllm llama3: Assistant for Efficiency and Cost Reduction

Discover vLLM llama3, the ultimate assistant for efficiency, cost reduction, and more. Find out how it can revolutionize your workflow.
Key Highlights
- vLLM Llama3 provides great accuracy and saves costs when using large language models.
- Its architecture focuses on getting the best performance. It includes key parts like docker containers, API servers, and GPU servers.
- Testing shows big gains in inference speed and throughput compared to older versions.
- LLama3 includes updates for improved efficiency, improvements in software, and new tech integration.
Introduction
The world of virtual large language models (LLMs) is always changing. Llama 3 is a good model showing scalability and efficiency. There is a need for better speed and easier ways to set them up. vLLM Llama3 is a strong answer to these needs. It gives great accuracy and saves money too. This blog post looks into vLLM Llama3. We will explore its design, how it improves performance, and what new features are included.
Understanding vLLM Llama3
At the centre of vLLM Llama3 is a carefully built design aimed at great performance and growth. It uses a distributed system design, which makes the most of many computing resources, especially GPUs.
Also, vLLM Llama3’s setup focuses on being flexible and easy to extend. This helps to connect smoothly with other tools and systems. This way, developers can adjust the deployment to meet their specific needs.
What is VLLM?
vLLM is a high-performance library specifically designed to facilitate the inference and serving of LLMs. It is distinguished by its focus on delivering speed, efficiency, and cost-effectiveness, making it an accessible solution for a wide use of developers.
Why Use VLLM?
- High Throughput: vLLM achieves state-of-the-art serving throughput, making it capable of handling a large volume of requests.
- Memory Management: Introducing PagedAttention, an advanced mechanism for efficiently managing attention key and value memory.
- Continuous Batching: vLLM supports continuous batching of incoming requests, enhancing the overall throughput and efficiency of the model.
- Seamless Integration: vLLM offers a process for deploying LLMs like Llama 3, allowing easy integration into existing systems and applications.
- API Compatibility: It includes an OpenAI-compatible server, ensuring being easily integrated into existing systems that utilize OpenAI’s API.
- Quantization Support: VLLM uses quantization techniques like GPTQ, AWQ, SqueezeLLM, and FP8 KV Cache to enable models to operate efficiently with lower precision without compromising performance.
- Scalability: VLLM supports scaling deployments for various use cases like customer support and summarization, adjusting effectively to different deployment sizes.
What is Llama 3?
LLaMA 3, developed by Meta, this advanced language model series aims to enhance AI’s abilities in understanding and generating human-like text. It builds upon the previous version Llama 2, leveraging large datasets and advanced architectures to achieve higher accuracy and more nuanced text generation. Llama 3 is designed to be versatile, serving applications in various fields such as research, content creation, and more.
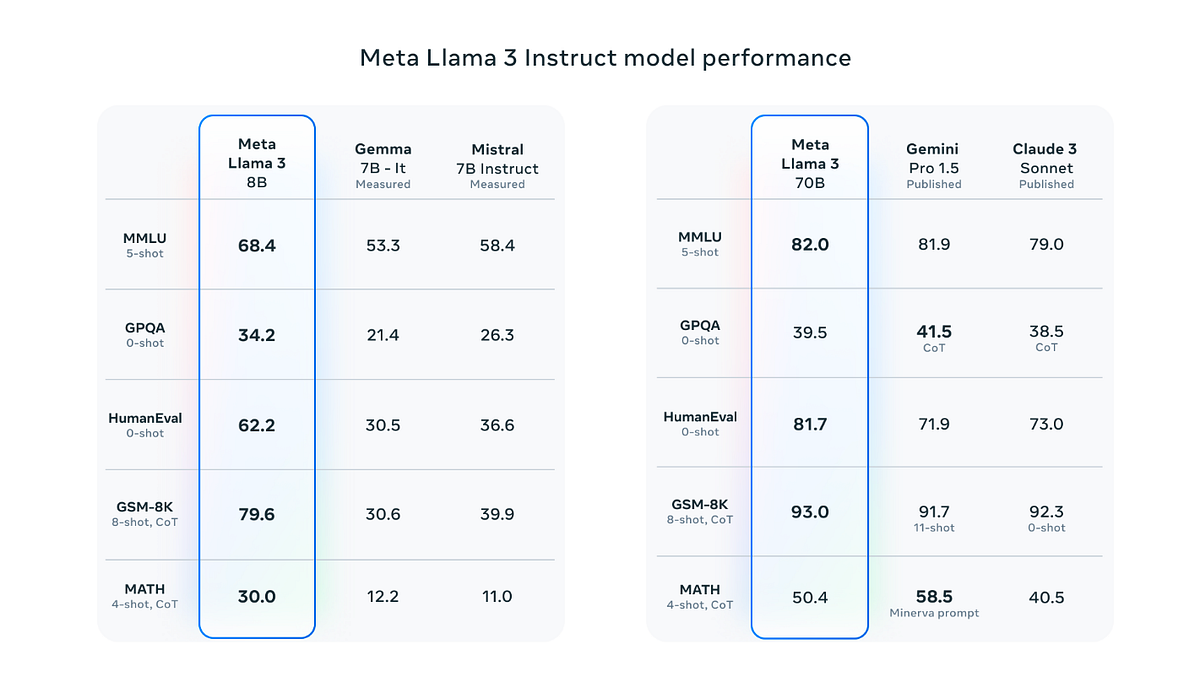
There are several versions of Llama 3: Llama 3 8B, Llama 3 8B-Instruct, Llama 3 70B, Llama 3 70B-Instruct. Llama 3 8B Instruct outperforms Gemma 7b-it, Mistral 7B Instruct while Llama 3 70B Instruct show better performance than Gemini and Claude.
Key Features of Llama 3
- Enhanced Accuracy: Llama 3 is accurate compared to previous models, especially the 70 billion parameter version (Llama 3 70B). It excels in chat interactions, code generation, summarization, and retrieval-augmented generation.
- Increased Training Data: Llama 3 benefits from increased training data, including diverse text sources and languages.
- Advanced Technologies: The model uses technologies like OpenAI’s Tiktoken tokenizer and data parallelization for enhanced efficiency.
- Resource Allocation: Llama 3 utilizes new scaling laws for improved performance prediction and resource allocation, maximizing computational efficiency and reducing runtime.
- Versatility: Llama 3’s enhancements make it ideal for various applications in e-commerce, finance, healthcare, and education.
- Scalability and Maintenance: Llama 3 features advanced training stacks for automated error detection, handling, and maintenance to ensure usability and scalability.
Llama 3 Models Performance and Cost Efficiency
Technical Features and Performance
Llama 3 8B
- Parameters: 8 billion
- Context Length:8K tokens
- Training Data: 15T tokens
Llama 3 70B
- Parameters:70 billion
- Context Length:8K tokens
- Training Data:15T tokens
These two models were released before the latest Llama 3.1 405B.
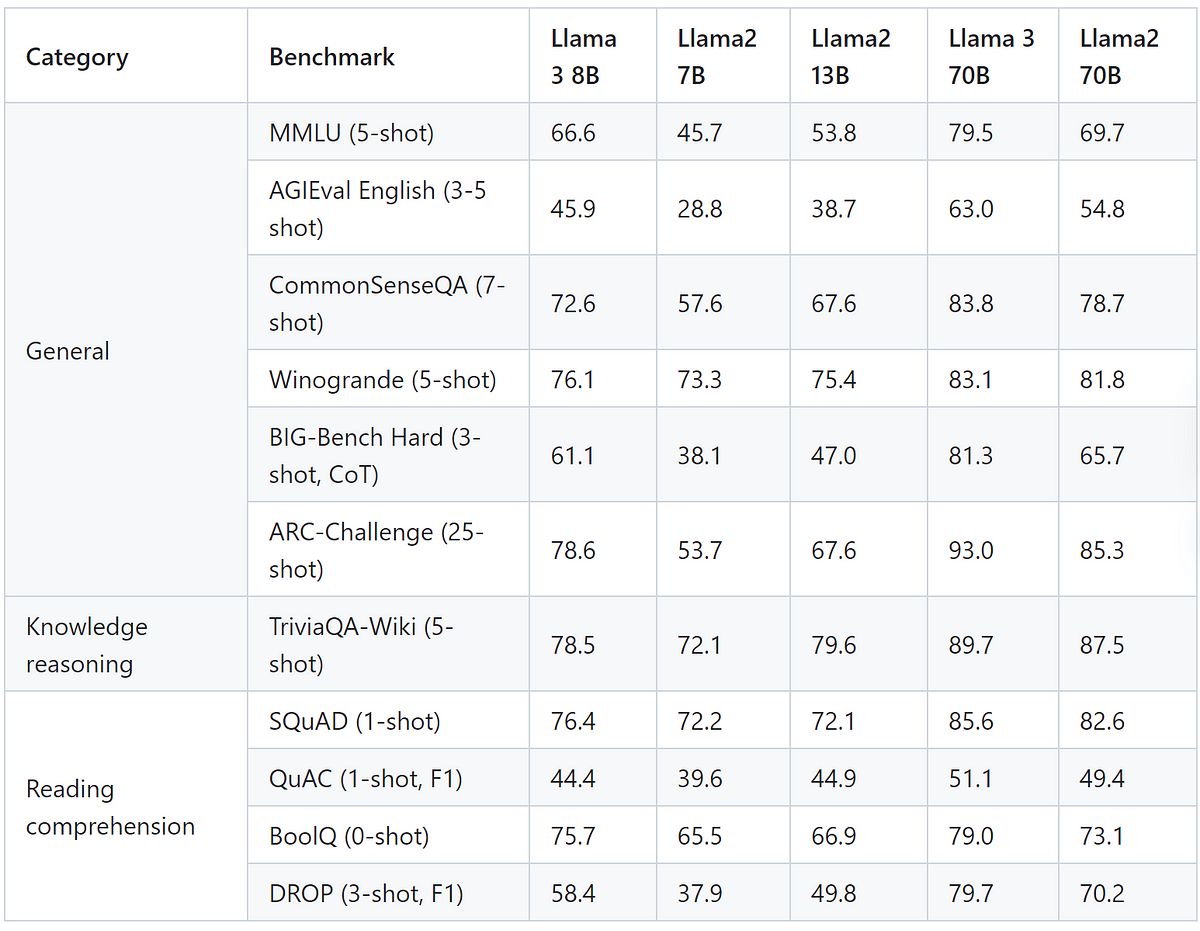
The following is a graph of the performance of base pre-trained models.
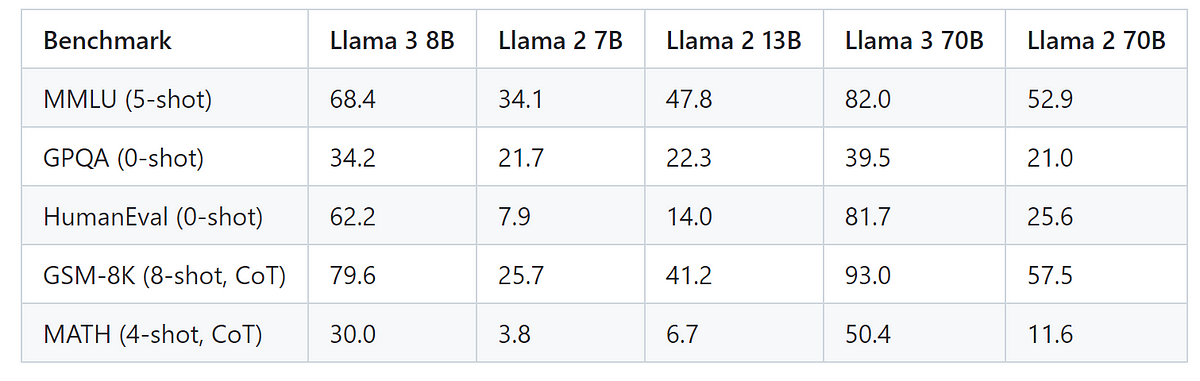
Here is the performance of instruction-tuned models that have been fine-tuned to better comprehend and follow human-provided instructions.
Llama 3 Cost Efficiency
Having analyzed its performance, we need to consider its actual cost. Taking llama 3 8b as an example, the deployment cost of customer support is as follows.
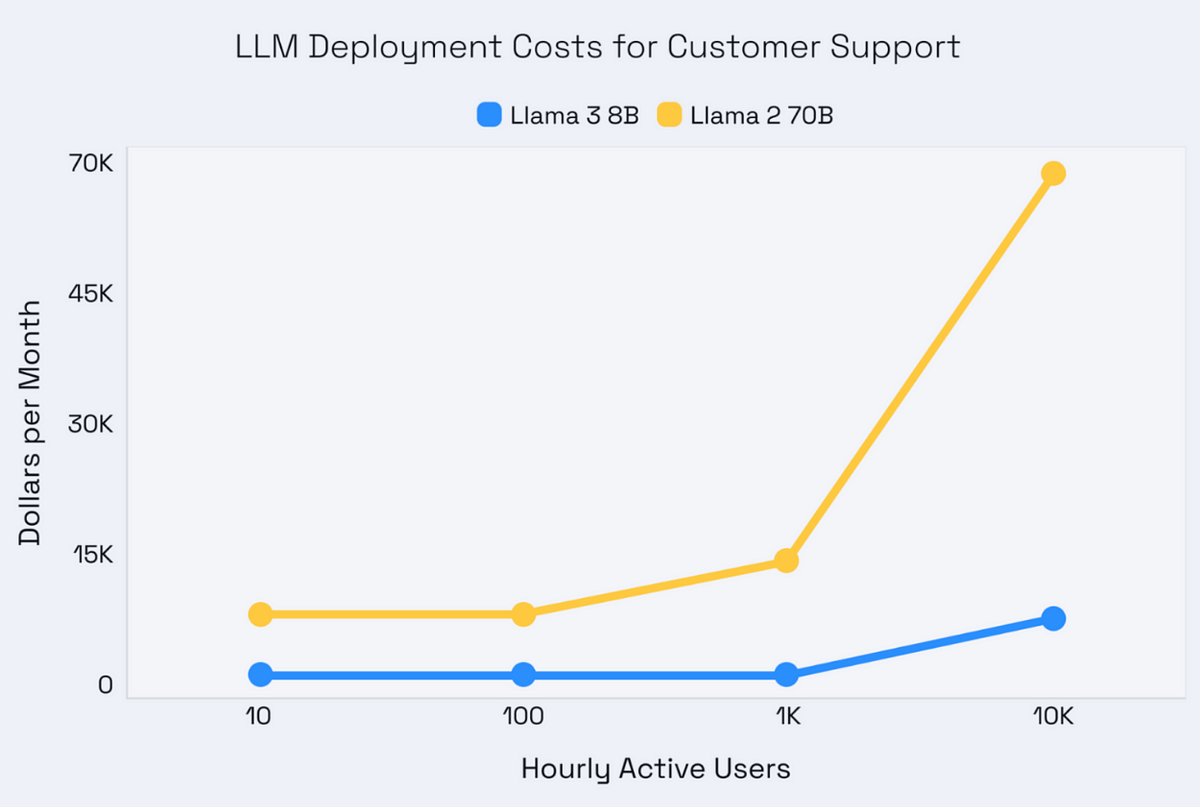
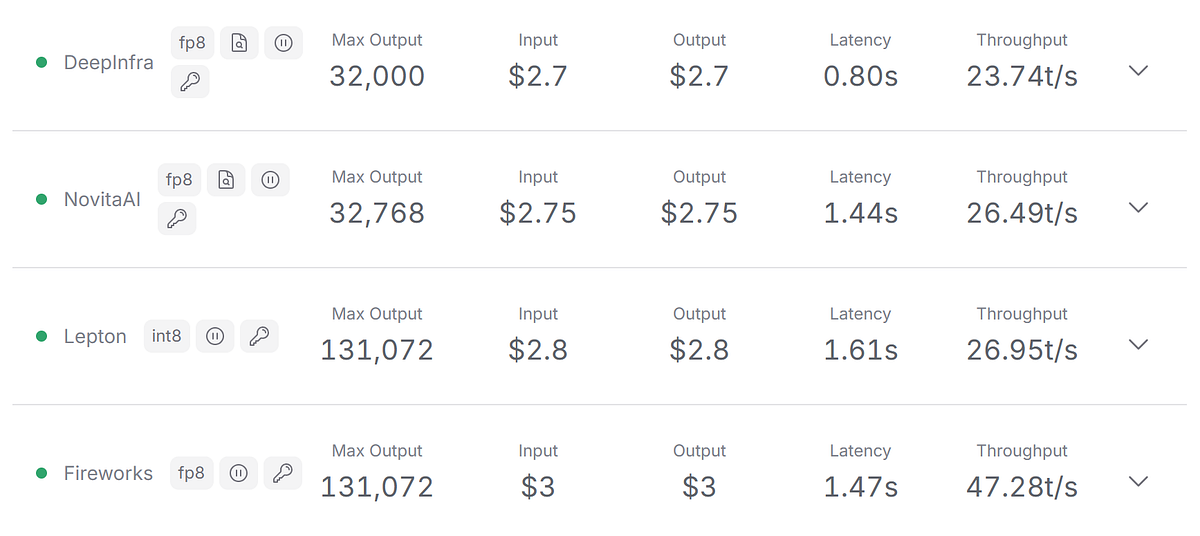
As a perfect cost-effective choice, Novita AI provides the meta-llama/llama-3–8b-instruct and meta-llama/llama-3–70b-instruct with no more than $1/M for input tokens and out tokens. You can view more models on LLM Model API.

We also offer the newest version meta-llama/llama-3.1–405b-instruct. Recently we cut the price of Llama 3.1 405B to $2.75 per million tokens!
Get Started with VLLM Llama 3
Technical Prerequisites
Ensure the following requirements before starting:
- A server with a compatible GPU (like NVIDIA A100 provided by Novita AI).
- Install Python in your system in the right directory.
- Ensure access to smooth Internet.
Deploy vLLM Llama 3
1. Install vLLM: Set up the vLLM environment on your server. You can use pip to install vLLM like:
pip install vllm2. Load the Model: Load the Llama 3 8B model into vLLM:
from vllm import LLM
model = LLM("meta-llama/Meta-Llama-3–8B-Instruct")3. Run LLM Inference: Use the model for inference:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3–8B-Instruct")
messages = [{"role": "user", "content": "What is the capital of France?"}]
formatted_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
output = model.generate(formatted_prompt)
print(output)Advanced Tips
- Customizing Llama3 serving is essential to meet various needs. The framework allows flexibility in configuration, such as resource allocation and model parameters.
- By adjusting API parameters, developers can customize the model’s behaviour and outputs for diverse use cases.
- Auto-tuning is crucial in machine learning. vLLM Llama3 leverages this technology to enhance performance by adjusting settings using AI and ML algorithms. This feedback loop continuously refines factors like latency and throughput for optimal user performance without manual intervention.
- You can also use the Docker image for efficiency. Improve the performance with techniques like quantization.
Developer’s Guide to Leveraging Llama 3: LLM API
Deploying Llama 3 is complex. To utilize Llama 3 effectively, developers can understand its functionality and APIs. We recommend Novita AI for cost-effective LLM API integration, as this AI API platform is equipped with featured models and affordable LLM solutions.
Get started with Novita AI API
- Step 1: Enter Novita AI and Create an account. You can log in with Google or GitHub. Your first login will create a new account. It’s okay to sign up for things using your email address.
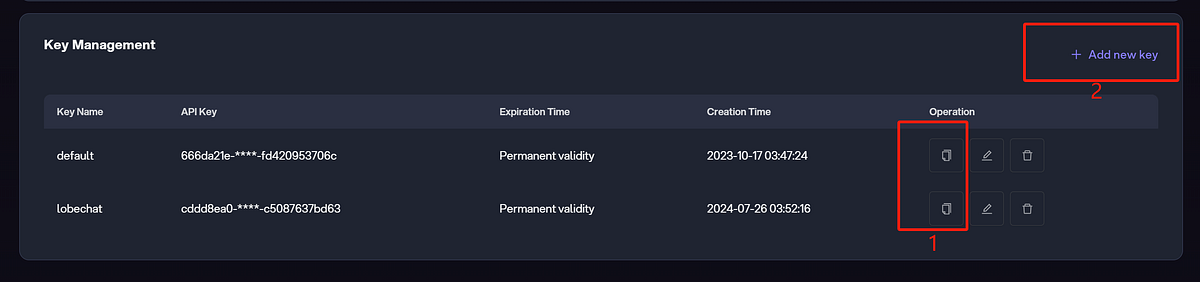
- Step 2: Manage API Key. Novita AI authenticates API access using Bearer authentication with an API Key in the request header. Go to “Key Management” to manage your keys. Once you log in first, a default key is automatically created. You can also click “+ Add new key”.
- Step 3: Make an API call. Enter your API key in the backend to continue the following tasks.
Here’s an example with a Python client using Novita AI Chat Completions API.
pip install 'openai>=1.0.0'from openai import OpenAIclient = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)For more info, you can visit Model API Reference.
- Step 4. Top up credit. As mentioned in the first step, you have a voucher with credits to try our products, but it’s limited. To add more credit, please visit Billing and Payments and follow the guide on Payment Methods.
Conclusion
In summary, vLLM Llama3 is a great solution that makes work easier and reduces costs. By knowing how it works, improving performance, and keeping up with changes in setting up requirements, developers can get the most out of it. The Llama3 model keeps getting better, showing a strong commitment to quality. With plans looking ahead and advanced tuning methods, vLLM Llama3 leads the way for new ideas in AI and ML technologies. Look out for new features and long-term plans that will help shape the future of model serving.
Frequently Asked Questions
What is vLLM vs TGI?
VLLM is an open-source LLM inference and serving engine that uses the PagedAttention memory allocation algorithm. It offers up to 24x higher throughput than Hugging Face Transformers and up to 3.5x higher throughput than Hugging Face Text Generation Inference.
How does vLLM batching work?
According to vLLM’s documentation, they use continuous batching, allowing the batch size to adjust dynamically as tokens are generated.
Is Llama 3 free?
Llama 3 is open source and available for free. However, for its API use, it may cost about $0.1/M for input and output tokens.
Can I use Llama 3 for business?
The latest version Llama 3 is covered by the “Meta LLama 3 Community License Agreement,” allowing for nearly all commercial purposes. Corporations utilize Llama3 to generate educational content, offer medical details and more.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended Reading
1.Introducing Llama3 405B: Openly Available LLM Releases