State-of-art retrieval-augmented LLM: bge-large-en-v1.5

Introduction
Are you intrigued by the cutting-edge retrieval-augmented LLM ‘bge-large-en-v1.5’? Join us in this blog as we explore this model in depth. You’ll uncover the role of embedding models and their practical applications. We’ll walk you through deploying ‘bge-large-en-v1.5’ in code, fine-tuning it, and integrating it seamlessly with LLM API. Get ready to unlock new possibilities at the intersection of embedding models and LLMs!
What Is bge-large-en-v1.5?
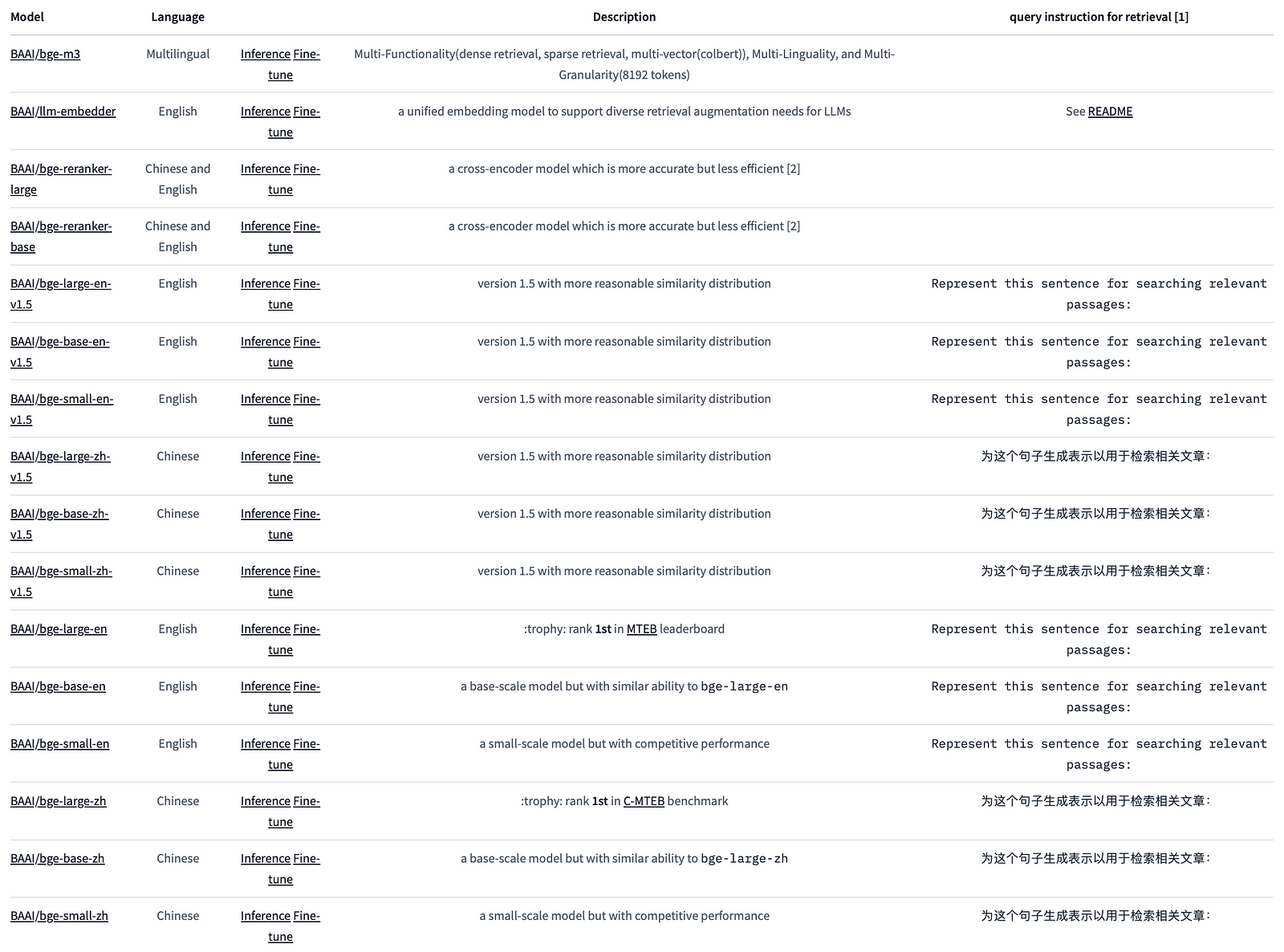
In brief, bge-large-en-v1.5 is an open-source embedding model created by BAAI.
Specifically, ‘bge’ in ‘bge-large-en-v1.5’ stands for ‘BAAI General Embedding’. BAAI, also known as ‘FlagEmbedding’ on Github, is a private non-profit organization dedicated to AI research and development. Focusing on retrieval-augmented large language models (LLMs), BAAI has launched several related projects. These include long-context LLM (Activation Beacon), LM fine-tuning (LM-Cocktail), dense retrieval (BGE-M3, LLM Embedder, BGE Embedding), reranker model (BGE Reranker), and benchmarking (C-MTEB). Bge-large-en-v1.5 belongs to the BGE Embedding model series, specifically developed for dense retrieval purposes.
What Does An Embedding Model for Dense Retrieval Do?

An embedding model for dense retrieval transforms text data into dense, semantic representations that capture the meaning and context of the input. These dense representations are used by a dense retriever to efficiently retrieve relevant information. Here’s how it works and some examples:
Transforming Text to Dense Representations
The embedding model takes sentences, paragraphs, or entire documents as input and converts them into fixed-length vectors (embeddings). These vectors encode semantic information about the text, allowing for more nuanced understanding beyond simple keyword matching.
LLMs often incorporate embedding models as part of their architecture. For instance, BERT uses embedding techniques to represent words and input sequences before processing them through its transformer layers. LLMs benefit from embedding models by leveraging their ability to capture semantic relationships and contextual nuances, which are crucial for generating coherent and contextually appropriate responses in tasks such as dialogue generation or machine translation.
Role of Dense Retriever
The dense retriever utilizes these embeddings to perform retrieval tasks. Unlike traditional sparse retrieval methods that rely on exact keyword matches or indices, a dense retriever computes similarity scores directly between query embeddings and document embeddings. This approach allows for more accurate retrieval across various lengths of text inputs, from short sentences to lengthy documents.
Examples of Applications
In information retrieval tasks, such as search engines or question answering systems, these dense representations enable efficient and accurate retrieval of relevant documents or passages.
For example, a query like “What are the symptoms of COVID-19?” can be transformed into an embedding vector. Similarly, documents discussing COVID-19 symptoms are also converted into embeddings. By comparing the similarity between the query embedding and document embeddings (using techniques like cosine similarity), the most relevant documents can be quickly identified and ranked.
Another example is recommendation systems. In this case, embeddings help in recommending products, articles, or videos by understanding user preferences and content similarities.
Overall, embedding models for dense retrieval, coupled with dense retrievers, play a crucial role in modern AI applications by transforming text into meaningful representations and efficiently retrieving relevant information based on semantic similarity.
How Can I Use bge-large-en-v1.5 In Code?
Using bge-large-en-v1.5 with Langchain
You can use bge in langchain like this:
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="Generate a representation for this sentence to be used for retrieving relevant articles:"
)
model.query_instruction = "Generate a representation for this sentence to be used for retrieving relevant articles:"Using bge-large-en-v1.5 with Huggingface Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["Sample Data-1", "Sample Data-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-en-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-en-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)For more info about usage of bge models, you can visit FlagEmbedding on Github.
How Can I Fine-Tune bge-large-en-v1.5?
Step 1 Installation
- Install using pip:
pip install -U FlagEmbedding - Or install from source after cloning the repository and navigating into it:
pip install . - For development, use editable install:
pip install -e .
Step 2 Data Preparation
- The training data should be in JSON format with each line as a dictionary containing
query,pos(list of positive texts), andneg(list of negative texts). - If negative texts are not available, they can be sampled randomly from the corpus.
Step 3 Mining Hard Negatives
- Use a script to mine hard negatives to improve sentence embedding quality.
- You can mine hard negatives following this command:
python -m FlagEmbedding.baai_general_embedding.finetune.hn_mine \
--model_name_or_path BAAI/bge-base-en-v1.5 \
--input_file toy_finetune_data.jsonl \
--output_file toy_finetune_data_minedHN.jsonl \
--range_for_sampling 2-200 \
--negative_number 15 \
--use_gpu_for_searching- Input File: A JSON file containing data for fine-tuning, where the script identifies the top-k documents per query and then randomly selects negative examples from these top-k results, excluding any positive examples already provided.
- Output File: The destination where the JSON file, now enriched with the newly sampled hard negatives, will be stored for use in the fine-tuning process.
- Number of Negatives: Specifies how many negative samples to gather.
- Sampling Range: Defines the scope from which to draw the negative samples. For instance, a range of 2–100 indicates that negatives will be taken from the top 2 to top 200 documents. Broadening this range, such as to 60–300, makes the selection of negatives less challenging by considering a wider set of documents.
- Retrieval Pool: The source from which the script will draw documents for retrieval. By default, this is the set of all negatives in the input file, formatted like the pre-training data. If a specific retrieval pool is designated, the script will use this set instead to find negative examples.
- GPU-Based Searching: An option to indicate if GPU-accelerated faiss-gpu should be utilized to enhance the efficiency of the negative retrieval process.
Step 4 Training
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.baai_general_embedding.finetune.run \
--output_dir {path to save model} \
--model_name_or_path BAAI/bge-large-en-v1.5 \
--train_data ./toy_finetune_data.jsonl \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size {large batch size; set 1 for toy data} \
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len 64 \
--passage_max_len 256 \
--train_group_size 2 \
--negatives_cross_device \
--logging_steps 10 \
--save_steps 1000 \
--query_instruction_for_retrieval ""- Training Batch Size per Device: The quantity of samples processed in each training batch. Typically, an increased batch size enhances model performance. You can augment this size by utilizing options such as half-precision training (
--fp16), DeepSpeed configuration (--deepspeed ./df_config.json, wheredf_config.jsonmight also be denoted asds_config.json), and gradient checkpointing (--gradient_checkpointing). - Training Group Size: Determines the total count of examples, both positive and negative, used for each query during training. As there’s a guaranteed positive example, this setting dictates the negative example count (calculated as
train_group_size - 1). Be aware that this number should not exceed the available negatives in your data'sneglist. In addition to these group negatives, other negatives within the batch are also incorporated into the fine-tuning process. - Cross-Device Negative Sharing: Enables the distribution of negative examples across all available GPUs, effectively increasing the total number of negatives utilized in training.
- Learning Rate: Choose a value that suits your specific model. For large, base, or small-scale models, values like 1e-5, 2e-5, or 3e-5 are typically recommended.
- Temperature: Affects the spread of the similarity score distribution. Suggested values range from 0.01 to 0.1.
- Maximum Query Length: The upper limit for query length, which should correspond to the average query length in your dataset.
- Maximum Passage Length: The upper limit for passage length, set according to the average length of passages in your data.
- Retrieval Query Instruction: An optional directive appended to each query for retrieval purposes. You can leave it blank by setting it to an empty string if no additional context is needed.
- In-Batch Negative Usage: A flag indicating whether to consider passages from the same batch as negative examples in training. The default setting is enabled (True).
- Checkpoint Save Interval: Defines the frequency of saving model checkpoints based on the number of training steps completed.
Step 5 Model Loading
Once the BGE model has been fine-tuned, you can effortlessly load it as demonstrated in this example. If you specified a unique value for the --query_instruction_for_retrieval hyperparameter during the fine-tuning phase, ensure to substitute the query_instruction_for_retrieval accordingly.
Step 6 Model Loading
For model evaluation, you can run this script provided by FlagEmbedding.
Adjusting the foundational bge model through fine-tuning can result in better task-specific performance, but it might also cause a notable decline in the model’s overall effectiveness outside of the targeted domain (for instance, a drop in performance on c-mteb tasks). For information about the solution (using LM-Cocktail) as well as the fine-tuning process, check out “FlagEmbedding/examples/finetune” on Github.
How Can I Integrate bge-large-en-v1.5 with LLM API?
Integrating an embedding model with an LLM enriches the AI’s natural language processing capabilities, enabling more sophisticated semantic search, contextual understanding, and personalized interactions. This integration is particularly useful for enhancing tasks such as content-based recommendations, document clustering, anomaly detection, cross-lingual processing, and knowledge graph construction. It also supports advanced text summarization and feature enhancement for machine learning models, leading to improved performance in sentiment analysis and topic classification.
Step 1: Set Up Your Environment
First, ensure you have the necessary Python environment with the required packages installed.
pip install openai
# Install other necessary packages, e.g., requests, numpy, etc.Step 2: Initialize the Novita AI API Client
You’ve already provided the code to initialize the Novita AI API client. Here it is for reference:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>", # Replace with your actual API key
)
model = "nousresearch/nous-hermes-llama2-13b"Step 3: Get the Embedding Model
Assuming you have access to the bge-large-en-v1.5 model, you would load it. If it's a Hugging Face model, you might use the transformers library like so:
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-large-en-v1.5")
model = AutoModel.from_pretrained("BAAI/bge-large-en-v1.5")Step 4: Define a Function to Get Embeddings
Create a function to get embeddings from the bge-large-en-v1.5 model.
def get_embeddings(text):
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
embeddings = model(**inputs)[0].mean(dim=1)
return embeddings.numpy()Step 5: Integrate with Novita AI LLM API
Now, integrate the embedding model with the LLM API to enhance the API’s responses or perform tasks like semantic search.
def enhanced_llm_response(prompt):
# Get initial response from LLM
response = client.completions.create(
model=model,
prompt=prompt,
stream=True,
max_tokens=512,
)
# Process the response (e.g., extract text)
# This is a placeholder for the actual response processing
response_text = next(response)['choices'][0]['text'].content
# Get embeddings for the response
response_embeddings = get_embeddings(response_text)
# Here, you can use the embeddings for various purposes,
# such as semantic search, filtering, etc.
return response_text, response_embeddingsStep 6: Use the Enhanced Function
Now you can use the enhanced_llm_response function to get responses from the LLM and process them with the embedding model.
prompt = "A chat between a curious user and an artificial intelligence assistant"
response, embeddings = enhanced_llm_response(prompt)
print(response)
# Do something with the embeddings, e.g., store them, search for similar texts, etc.Step 7: Error Handling and Logging
Add error handling and logging to your code to manage API limits, request failures, and other potential issues.
Step 8: Test and Iterate
Test the integration thoroughly and iterate based on the results. You may need to adjust parameters, handle more edge cases, or optimize performance.
Please note that the actual implementation details may vary based on the specific capabilities and requirements of the Novita AI LLM API and the bge-large-en-v1.5 model. You can contact Novita AI Team for technical support: support@novita.ai.
Conclusion
In summary, our exploration of ‘bge-large-en-v1.5’ has highlighted its integral role in dense retrieval tasks, offering a deep dive into its capabilities, applications, and practical implementation. From introducing the model and its significance in the realm of embedding to demonstrating its use in code and its fine-tuning process, we’ve laid out a comprehensive guide. Moreover, the integration with the Novita AI LLM API exemplifies the model’s potential to amplify LLMs’ semantic understanding and retrieval accuracy.
Stay tuned for more updates on LLMs!
Frequently Asked Questions
1. How does a BGE reranker work?
By inputting a query and a passage into the reranker, you can obtain a relevance score. This score can be transformed into a floating-point value within the range of [0, 1] using a sigmoid function. This process aims to ensure that the top-ranked results are more relevant and of higher quality, improving overall system performance.
2. What is the context length of BGE?
The latest model bge-m3 has a context length of 8kb.
3. What is the size of bge m3 embedding?
It can handle inputs of varying lengths, from short sentences to lengthy documents containing up to 8192 tokens.
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.
Recommended Reading
What is LLM Embeddings: All You Need To Know
Unveiling the Power of BGE Large: The Future of Text Embedding