Red Pajama LLM: Public Dataset Analysis Revealed

Key Highlights
- Red Pajama 2 is open-source language model pre-training dataset containing a massive 30 trillion tokens, it the largest public dataset for language model pre-training.
- The dataset includes over 100 billion text documents from 84 CommonCrawl snapshots, covering English, German, French, Italian, and Spanish.
- Red Pajama 2 provides high-quality datasets for training large language models and offers over 40 pre-computed data quality annotations for further filtering and weighting.
- The dataset is open source and available on Hugging Face, with the data processing scripts available on GitHub, making it easily accessible for developers and researchers.
- Red Pajama 2 aims to simplify the process of filtering and preprocessing raw data, reducing the time and energy required for model development.
- It is suitable for commercial use and encourages developers to enrich their data mixtures with other resources like the Stack by BigScience and s2orc by AI2.
Introduction
AI startup Together has recently released Red Pajama 2, an open dataset containing an impressive 30 trillion tokens for training large language models. This dataset is considered the largest public dataset specifically designed for language model pre-training. Building on the success of Red Pajama 1, which offered a 1.2 trillion token dataset, Red Pajama 2 aims to expedite the process of model training by providing preprocessed data from the HuggingFace platform.

Red Pajama 2 is open source and available on Hugging Face, a popular platform for sharing and using natural language processing models and datasets. Additionally, the data processing scripts used to create the dataset are available on GitHub, making it accessible and customizable for developers and researchers.
This blog post will delve into the details of Red Pajama 2, exploring its features, advantages, and potential applications. Furthermore, it will highlight the efforts made by Together to ensure data quality, ethical use, and the responsible development of large language models. Overall, Red Pajama 2, also known as Falcon, represents a significant milestone in the field of open-source language models and provides a valuable resource for researchers and developers alike, covering a small portion of the CommonCrawl crawls.
The Red Pajama Dataset: A Milestone in Open-Source Language Models
The Red Pajama base dataset has established itself as a milestone in the realm of open-source language models. With Red Pajama 2, Together has taken this accomplishment to new heights, creating the largest public dataset specifically designed for language model pre-training. This dataset, also known as the RedPajama-V2 corpus, offers researchers and developers access to a vast amount of high-quality data, allowing them to train and fine-tune large language models more efficiently. By making this dataset open source and providing comprehensive data quality annotations, Together aims to foster innovation and collaboration in the field of natural language processing with the use of their Pythia architecture.
Red Pajama 2: Reproducing the Llama Training Data Set
Red Pajama 2 builds upon the success of its predecessor, Red Pajama 1, which introduced the Llama training dataset. The Llama dataset, named after the popular animal, includes 1.2 trillion tokens and has been widely used for training large language models. With Red Pajama 2, Together has reproduced and expanded upon the Llama dataset, offering an impressive 30 trillion tokens for training purposes. This substantial increase in token count provides researchers and developers with a wealth of data to explore and utilize in their language model training, specifically for LLM training data. Red Pajama 2 sets a new standard in the availability and scale of training data for large language models, further advancing the field of natural language processing with its inclusion of plain text data.

Three Key Components of the Red Pajama Dataset
The Red Pajama dataset consists of three key components that contribute to its significance and usefulness for training large language models:
- Base Model: The Red Pajama dataset serves as a foundation for developing and fine-tuning large language models. Its extensive token count provides a robust base for training models with improved language understanding and generation capabilities.
- Data Sources: The dataset is sourced from 84 CommonCrawl snapshots, covering a wide range of topics and languages. This diverse range of data sources ensures the dataset’s versatility and broad applicability.
- Quality Annotations: Red Pajama includes over 40 pre-computed data quality annotations, allowing researchers and developers to filter and weigh the data based on specific criteria. These annotations enable the creation of high-quality training datasets tailored to specific language model development needs.
By incorporating these key components, Red Pajama offers a comprehensive and versatile dataset for training large language models, empowering researchers and developers to push the boundaries of natural language processing.
Why RedPajama-Data-v2 and How to Use it?
RedPajama-Data-v2 is a game-changer in the world of open training datasets for large language models. Its impressive token count and high-quality data make it an invaluable resource for researchers and developers. Here are a few reasons why RedPajama-Data-v2 stands out:
To use RedPajama-Data-v2, developers can access the dataset on Hugging Face and refer to the provided data processing scripts on GitHub. This ensures ease of use and flexibility for incorporating RedPajama-Data-v2 into AI projects.
Why Red Pajama Dataset stands out?
The Red Pajama dataset stands out for several reasons, making it a valuable resource for training large language models:
- Open Source: Red Pajama is an open-source dataset, allowing researchers and developers to freely access and use the data for their projects. This fosters collaboration and innovation in the field of natural language processing.
- Stanford Hazy Research Group: The Red Pajama dataset is developed by the Stanford Hazy Research Group, renowned for their contributions to the field of AI and language models. Their expertise and dedication ensure the quality and reliability of the dataset.
- Foundation Models: Red Pajama serves as a foundation for training and fine-tuning large language models. By providing a comprehensive dataset, it enables the development of more advanced and sophisticated language models, pushing the boundaries of AI capabilities.

These factors, along with the dataset’s size and quality, make the Red Pajama dataset a standout option for researchers and developers seeking to enhance their language model training and research endeavors.
How to use Red Pajama Dataset with ease?
Using the Red Pajama dataset is made easy through the following steps:
- Access the Dataset: The dataset is available on Hugging Face, a platform for sharing natural language processing models and datasets. Developers can download the dataset from the platform.
- Data Processing Scripts: Red Pajama provides data processing scripts on GitHub, ensuring easy integration into AI projects. These scripts facilitate the preprocessing and filtering of the dataset, saving developers time and effort.
- Python Integration: Developers can leverage Python, a popular programming language in the field of AI, to interact with the Red Pajama dataset. Python libraries and tools such as pandas and numpy can be used to manipulate and analyze the dataset.
By following these steps and utilizing the resources provided, developers can seamlessly incorporate the Red Pajama dataset into their language model training and research workflows.
How Red Pajama LLM works
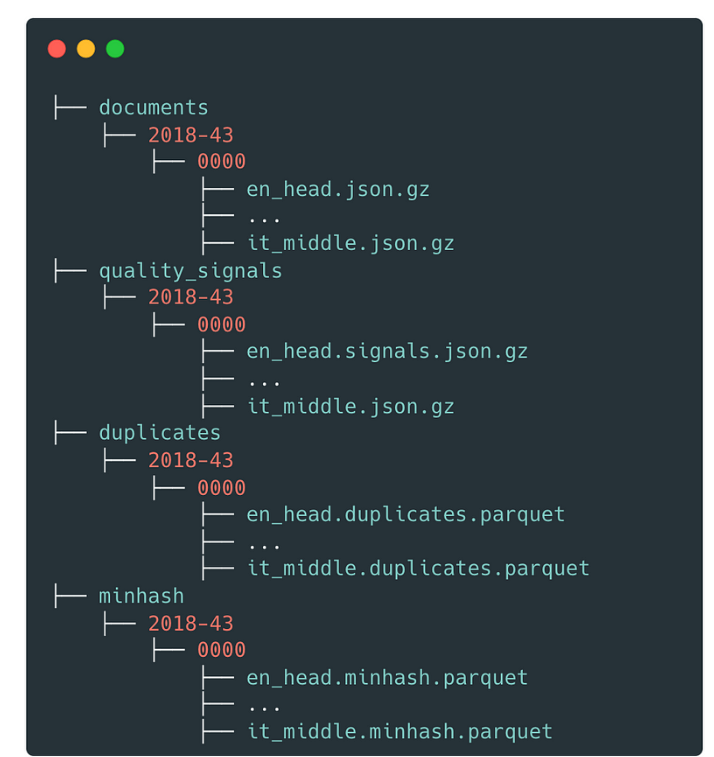
Data Processing Steps
RedPajama-V2 focuses on CommonCrawl. Other data sources such as Wikipedia are available in RedPajama-V1. We also encourage you to enrich your data mixture with the Stack (by BigScience) for code and s2orc (by AI2) for scientific articles. RedPajama-V2 is built from the ground up based on publicly available web data, consisting of 84 crawls provided by CommonCrawl. The core components that this dataset is made of, are the source data (plain text), 40+ quality annotations, and deduplication clusters.
Creating the Source Data
The first processing step in building this dataset is to pass each CommonCrawl snapshot through the CCNet pipeline. We choose this pipeline due to its light processing, aligning with our guiding principle of preserving as much information in the raw dataset as possible and allowing downstream model developers to filter or reweight the dataset. We use the language filter in CCNet and keep five languages in this release: English, French, Spanish, German and Italian. This processing step produces 100 billion individual text documents.
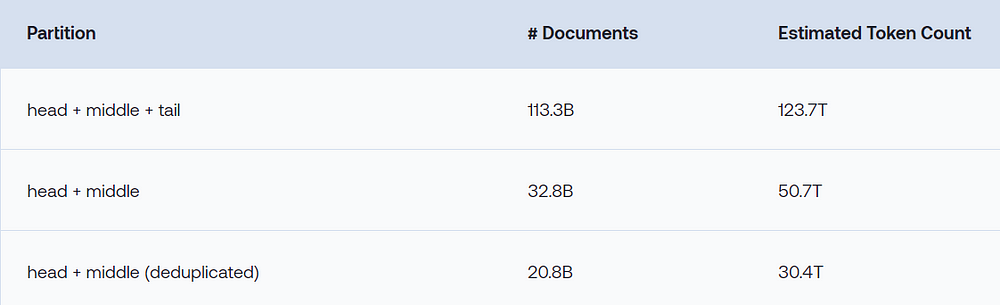
Dataset Statistics
RedPajama-v2 processed 84 CommonCrawl crawls and consists of 113B documents in the five languages (English, German, French, Spanish, and Italian). While we keep the tail partition of the resulting data, consisting of an estimated 80B documents, we also compute the number of documents and tokens for the head and middle partitions (before and after deduplication). Interestingly, while this reduces the token count by 60%, the number of documents decreases disproportionately more by 71%, indicating that the tail documents are generally shorter.
Updating and Expanding the Dataset
Red Pajama 2 is a living project, continuously evolving and expanding to meet the needs of researchers and developers. The dataset is updated and expanded regularly, incorporating new data from CommonCrawl dumps and incorporating fuzzy deduplication techniques to ensure data integrity.
In addition to expansion, Red Pajama 2 includes a wide range of quality signals to further enhance the dataset’s usefulness. These quality signals enable researchers and developers to filter and weigh the data based on specific criteria, ensuring the creation of tailored and high-quality training datasets.
By continuously updating and expanding the dataset, Red Pajama 2 remains a valuable resource for the AI community and contributes to the advancement of large language models and natural language processing research.
Practical Applications: How to Leverage Red Pajama 2 for Your Projects
Red Pajama 2 offers numerous practical applications in the field of artificial intelligence and large language models. Here are a few ways developers and researchers can leverage Red Pajama 2 for their projects:
- AI Development: Red Pajama 2 provides a comprehensive dataset for training and fine-tuning large language models. Developers can utilize this dataset to enhance the capabilities of their AI models and improve performance.
- Language Model Research: Red Pajama 2 serves as a valuable resource for conducting research on language models. Researchers can explore various aspects of language understanding, generation, and analysis using this extensive dataset.
- Use Cases: Red Pajama 2 can be applied to various use cases, including chat-completion, code generation, and scientific article analysis. Its versatility and size make it suitable for a wide range of applications in the AI domain.
By leveraging Red Pajama 2 in their projects, developers and researchers can unlock new possibilities and advancements in natural language processing and AI development.
From Theory to Practice: Implementing Red Pajama 2 in Real-World Scenarios
Red Pajama 2, with its vast dataset, offers practical application avenues bridging theory to real-world scenarios. Implementing Red Pajama 2 involves leveraging its open-source nature for diverse AI projects. Through direct usage and quality annotations, this dataset becomes a powerhouse for AI development, providing a pool of web data and high quality datasets for LLM training. The transition from theoretical concepts to practical implementation signifies a significant stride in the realm of AI applications. Red Pajama 2 enhances the potential for innovation by providing a robust framework for real-world AI utilization.
Case Simulation: Enhancing Chat-completion with Novita.ai Using Red Pajama 2
One practical application of Red Pajama 2 is enhancing chat-completion systems.
Here is a simulating example:
Novita.ai, a leading provider of chat-completion solutions, can successfully leveraged Red Pajama 2 to improve the accuracy and fluency of their chatbot models.
By training their models on the extensive and diverse data from Red Pajama 2, Novita.ai could achieve significant improvements in natural language understanding and response generation. You can try Chat-completion for free now.

The collaboration between Red Pajama 2 and Novita.ai showcases the practical applications of the dataset and its impact on real-world AI solutions. Through such case simulations, developers and researchers can gain insights into the potential of Red Pajama 2 and its ability to drive advancements in chat-completion and similar domains.
Navigating Challenges: Ensuring Quality and Ethical Use
While Red Pajama 2 offers numerous benefits, it also presents challenges related to data quality and ethical use. Together, the developer of Red Pajama 2, recognizes the importance of addressing these challenges to ensure the responsible and ethical development of large language models. Measures are taken to ensure data quality and integrity through rigorous quality assessments and deduplication techniques. Additionally, ethical considerations, such as responsible use and commercial use guidelines, are emphasized to promote the ethical use of the dataset. By navigating these challenges, Red Pajama 2 aims to foster the responsible development and deployment of large language models in the AI community.
Quality at Scale: Ensuring Data Integrity and Relevance
Ensuring data quality and integrity at scale is a critical aspect of the Red Pajama 2 dataset. The dataset’s extensive size and diverse sources require robust measures to maintain data integrity and relevance. To achieve this, Red Pajama 2 incorporates thorough quality assessments and deduplication techniques to filter out low-quality or duplicate content. By ensuring the integrity of the dataset, developers and researchers can rely on the data to produce accurate and reliable results in their language model training and research endeavors. The continuous evolution and expansion of the dataset also contribute to its relevance, allowing users to access the most up-to-date and curated data for their projects.
Ethical Considerations: Responsible Use of a Massive Dataset
As an extensive and powerful dataset, Red Pajama 2 raises important ethical considerations. Together, the developer of Red Pajama 2, emphasizes the responsible use of the dataset to ensure ethical and fair practices. Guidelines are provided to promote the responsible development and deployment of large language models trained on the dataset. Commercial use is permitted, but developers are encouraged to adhere to ethical standards and consider the potential impact of their models on society. By fostering responsible use and ethical practices, Red Pajama 2 aims to contribute positively to the AI community and mitigate any potential ethical concerns associated with the dataset’s size and capabilities.
The Future is Open: The Impact of Open-Source Models on AI Development
The open-source nature of Red Pajama 2 reflects the broader trend towards open-source models in the field of AI. Open-source models, like Red Pajama 2, have a significant impact on AI development for several reasons. They foster collaboration and knowledge sharing among researchers and developers, enabling rapid advancements in the field. Open-source models also provide a transparent and accessible foundation for building innovative AI solutions. Red Pajama 2 represents the frontier of open-source language model datasets, pushing the boundaries of AI development and setting the stage for future advancements in natural language processing and large language models. This is evident in the collaboration between various institutions such as Ontocord.ai, ETH DS3Lab, AAI CERC, Université de Montréal, MILA — Québec AI Institute, Stanford Center for Research on Foundation Models (CRFM), Stanford Hazy Research research group and LAION in the development of RedPajama-INCITE-Instruct-3B-v1 and RedPajama model
Democratizing AI: How Open-Source Models are Changing the Game
Open-source models, such as Red Pajama 2 and the EleutherAI project, are playing a crucial role in democratizing AI. By making high-quality datasets and models freely available, open-source initiatives level the playing field for researchers and developers around the world. Open models like these enable access to state-of-the-art resources that were previously exclusive to a few organizations or researchers. This democratization of AI empowers a diverse range of individuals and teams to contribute to AI development, fostering innovation and creating opportunities for groundbreaking research. The game-changing nature of open-source models, like Red Pajama 2 and the Replit code model, is transforming the AI landscape and paving the way for more inclusive and collaborative AI development.
Beyond Red Pajama 2: What’s Next in Open-Source AI?
Red Pajama 2 represents a significant milestone in open-source AI, but it doesn’t mark the end of the journey. The future of open-source AI holds immense potential for further advancements and innovations. The Olmo team, the force behind Red Pajama 2, continues to push the boundaries and explore new frontiers in open-source language model development. The team’s commitment to open training datasets and collaboration sets the stage for future breakthroughs in AI research and development. As the AI community continues to embrace open-source models, the possibilities for advancements in natural language processing and AI as a whole are endless. Red Pajama 2 is just the beginning of an exciting future in open-source AI.
Conclusion
In conclusion, Red Pajama 2 signifies a groundbreaking advancement in open-source language models, boasting an impressive 30 trillion tokens. Its robust technical backbone and continuous evolution make it a standout choice for various projects. Leveraging Red Pajama 2 can enhance chat-completion and fuel real-world scenarios. Quality and ethical considerations remain at the forefront, ensuring responsible and impactful use. The future of open-source models like Red Pajama 2 holds immense potential in democratizing AI development. As we look ahead, the possibilities for innovation and collaboration in the realm of open-source AI are truly limitless.
Frequently Asked Questions
What are the requirements to use Red Pajama 2?
To use Red Pajama 2, you need a system with sufficient computational resources, including a GPU, ample RAM, and a Python environment. These requirements ensure smooth processing and utilization of the dataset for language model training and research.
How does Red Pajama 2 compare to other datasets in terms of size and diversity?
With a massive 30 trillion tokens and data sourced from 84 CommonCrawl snapshots across multiple languages, Red Pajama 2 offers an unparalleled resource for training large language models. Its vast size and diverse sources provide developers and researchers with a comprehensive and versatile dataset for their language model development needs.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
LLM Leaderboard 2024 Predictions Revealed
Unlock the Power of Janitor LLM: Exploring Guide-By-Guide
TOP LLMs for 2024: How to Evaluate and Improve An Open Source LLM