How to Make LLMs Better at Translation?

Introduction
In this blog, we delve into the fascinating world of large language models (LLMs) and their capabilities in performing translation tasks. Inspired by the academic paper titled “Adaptive Machine Translation with Large Language Models,” we will explore the following questions:
- How do LLMs accomplish translation without any additional training or fine-tuning?
- What strategies can be employed to enhance their translation performance?
- How can we adopt these strategies to get our own LLM skilled at translation?
- What future directions hold promise for improving translation with LLMs?
If you are interested, just keep reading!
How Do Large Language Models Do Translation Tasks?
Pre-Training:
LLMs start with a phase called pre-training, where they are exposed to a vast amount of text data in multiple languages. This helps them learn patterns, grammar, vocabulary, and the relationships between words and phrases across languages.
Understanding Context:
When given a sentence to translate, the LLM uses its understanding of context to interpret the meaning of the words and the overall sentence structure.
Sequence Generation:
The model then generates a translation by predicting the most likely sequence of words in the target language that corresponds to the input sentence.
Autoregressive Nature:
LLMs often use an autoregressive approach, where they predict the next word in the sequence based on the previously generated words. This continues until the model generates an end-of-sentence token or reaches a predefined length.
Beam Search:
To improve the quality of translation, LLMs may use techniques like beam search, which expands multiple translation hypotheses simultaneously and selects the most probable one based on a scoring function.
Handling Ambiguity:
LLMs are designed to handle ambiguity in language by choosing translations that are statistically more likely given the context, even if multiple translations are grammatically correct.
Post-Processing:
After generating a translation, some models may apply post-processing steps to refine the output, such as correcting grammar, adjusting word order, or resolving any anomalies.
How Can Large Language Models Do Translation Task Better?
The experiments in the paper “Adaptive Machine Translation with Large Language Models” were conducted using the GPT-3.5 textdavinci-003 model via its official API. The setup included various parameters like top-p 1, temperature adjustments, and token length multipliers for different languages. The context dataset TICO-19, with 3070 unique segments, was used to simulate domain-specific scenarios. The study involved five diverse language pairs: English-to-Arabic, English-to-Chinese, English-to-French, English-to-Kinyarwanda, and English-to-Spanish.
The paper explores several strategies to improve the performance of LLMs in translation tasks:
Adaptive MT with Fuzzy Matches:
- Objective: To assess the capability of LLMs to adapt translations in real-time by leveraging context from similar, previously translated segments (fuzzy matches).
- Method: Utilized embedding similarity-based retrieval to extract fuzzy matches from a dataset and presented them alongside a new sentence to be translated.
- Example: If the new sentence to translate is “The quick brown fox jumps over the lazy dog,” the system might retrieve similar sentences from the dataset and use them to influence the translation style.
Comparison with Encoder-Decoder MT Models:
- Objective: To evaluate the translation quality of GPT-3.5 against established encoder-decoder models.
- Method: Compared translation outputs from GPT-3.5 with those from various APIs and models using the same source text.
- Example: For a given sentence in English, each model (GPT-3.5, DeepL, Google Cloud, etc.) would generate a translation in the target language, and the quality metrics (spBLEU, chrF++, etc.) would be compared.
Incorporating Encoder-Decoder MT:
- Objective: To explore if combining the outputs of encoder-decoder models (e.g. DeepL) with the in-context learning of LLMs could enhance translation quality.
- Method: Appended the translation from an encoder-decoder model to the fuzzy matches used in the context prompt for GPT-3.5.
- Example: If the fuzzy matches and the new segment to be translated are provided to GPT-3.5, also include the translations from an encoder-decoder model for those segments to enrich the context.
Bilingual Terminology Extraction:
- Objective: To automatically extract and utilize domain-specific terms to improve the consistency and accuracy of translations.
- Method: Trained GPT-3.5 to identify and extract key terms from sentence pairs and then use these terms to constrain translations.
- Example: Given a sentence pair containing medical terms, GPT-3.5 would extract terms like “influenza” and “vaccination” and ensure these terms are consistently used in the translation.
Terminology-Constrained MT:
- Objective: To integrate domain-specific terminology into the translation process to improve adherence to specific styles and vocabularies.
- Method: Used a predefined glossary or extracted terms from fuzzy matches to constrain the translations.
- Example: For a sentence to be translated within a medical context, the system would use terms from a medical glossary, such as “malignant” or “benign,” to ensure the translation uses the correct terminology.
How Much Better Can Large Language Models Be At Translation?
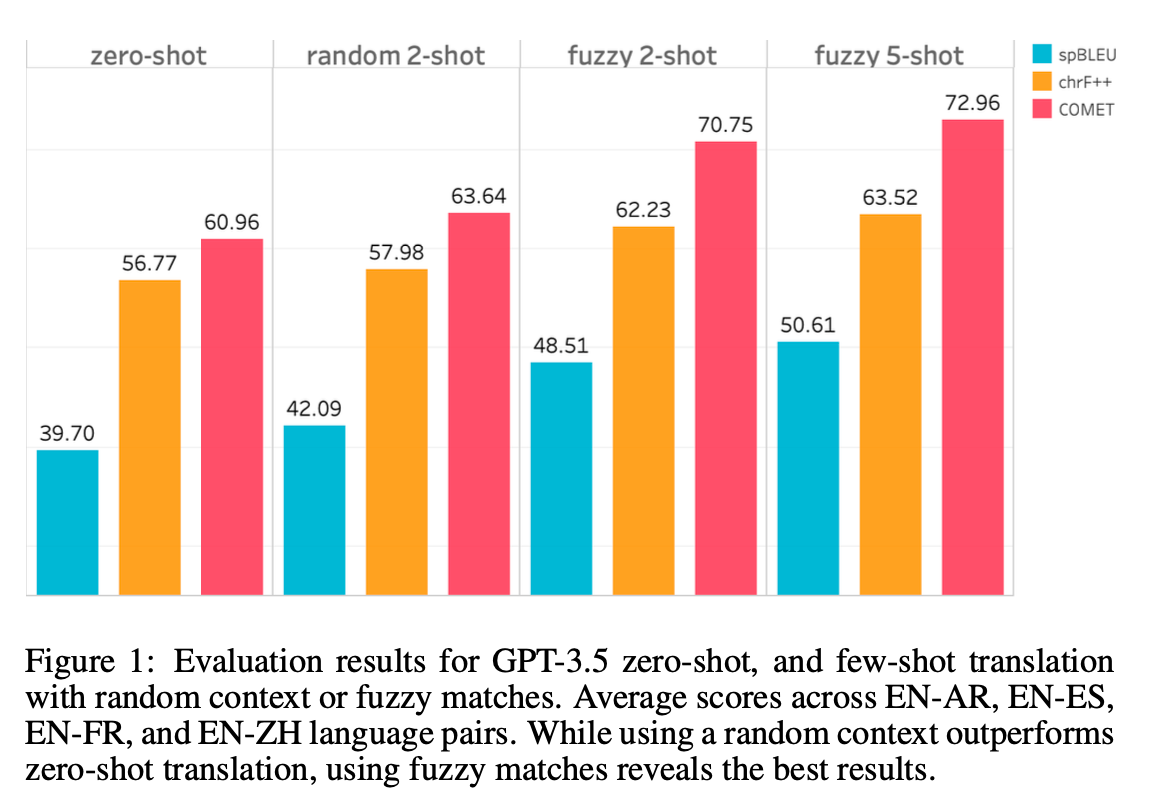
Adaptive MT with Fuzzy Matches:
The paper demonstrated that using fuzzy matches (previously translated segments with high similarity to the source text) as context significantly improved the translation quality of LLMs like GPT-3.5.
For example, in the English-to-Arabic (EN-AR) pair, using a single fuzzy match improved spBLEU scores from 27.6 (zero-shot) to 36.38. With two fuzzy matches, the score further increased to 38.41. Similar improvements were observed across other language pairs, showing the effectiveness of in-context learning with fuzzy matches.
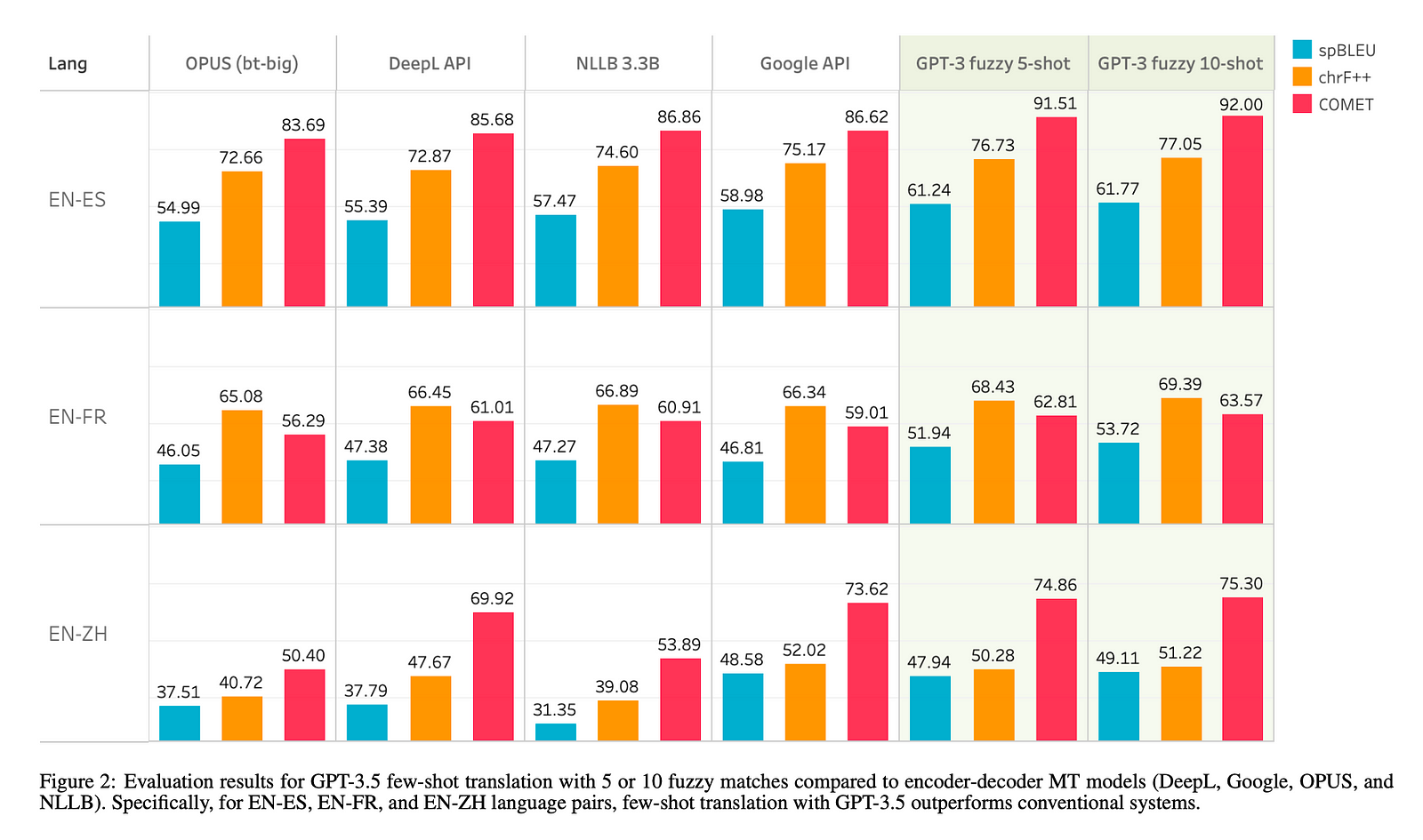
Comparison with Encoder-Decoder MT Models:
GPT-3.5’s few-shot translation quality was compared with several encoder-decoder MT systems, including DeepL, Google Cloud Translation API, OPUS, and NLLB.
For high-resource languages, GPT-3.5 with 5 or 10 fuzzy matches outperformed conventional systems in certain language pairs. For instance, in English-to-Spanish (EN-ES), GPT-3.5 with 5-shot translation achieved a spBLEU score of 61.77, surpassing the scores of other systems.
Incorporating Encoder-Decoder MT:
By appending the machine translation of the new segment from an encoder-decoder model to fuzzy matches, the paper observed substantial improvements in translation quality.
For instance, in English-to-Arabic, appending OPUS MT to 5 fuzzy matches improved the spBLEU score from 41.33 to 45.9.
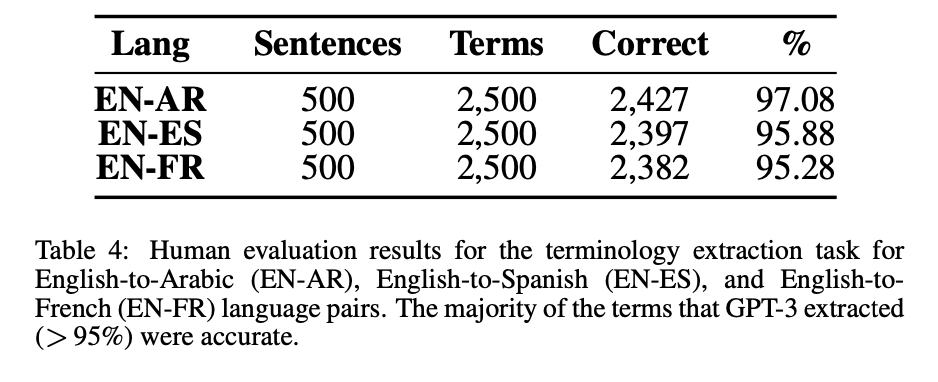
Bilingual Terminology Extraction:
GPT-3.5 was tasked with extracting 5 bilingual terms from each sentence pair in the context dataset. Human evaluation showed that the majority of terms (over 95%) extracted by GPT-3 for EN-AR, EN-ES, and EN-FR language pairs were accurate.
Terminology-Constrained MT:
The paper found that integrating terms from a glossary into the translation process improved translation quality, especially in zero-shot scenarios. For example, in English-to-Arabic, zero-shot translation with glossary terms improved the spBLEU score from 27.6 to 35.38.
The human evaluation of terminology-constrained MT showed that the model successfully transferred glossary terms into the target more often than without terminology incorporation.
ChatGPT Models, BLOOM and BLOOMZ Models:
The paper briefly compared GPT-3.5 with newer conversational models like GPT-3.5 Turbo and GPT-4. GPT-4 showed better zero-shot translation quality, while GPT-3.5 Turbo was more efficient but had comparable quality for few-shot translation.
When comparing GPT-3.5 with open-source multilingual models BLOOM and BLOOMZ, GPT-3.5 generally outperformed both for most language pairs, except for English-to-Arabic, where BLOOM showed comparable performance.
How Do I Get an LLM Skilled in Translation?
Following the approaches presented by the author, here is a step-by-step for you!
Step 1 Obtain Access to an LLM API:
- Sign up for an API key to access a large language model (LLM). Novita AI LLM API provides developers with a lot of cost-effective LLM options, including Llama3–8b, Llama3–70b, Mythomax-13b, etc.
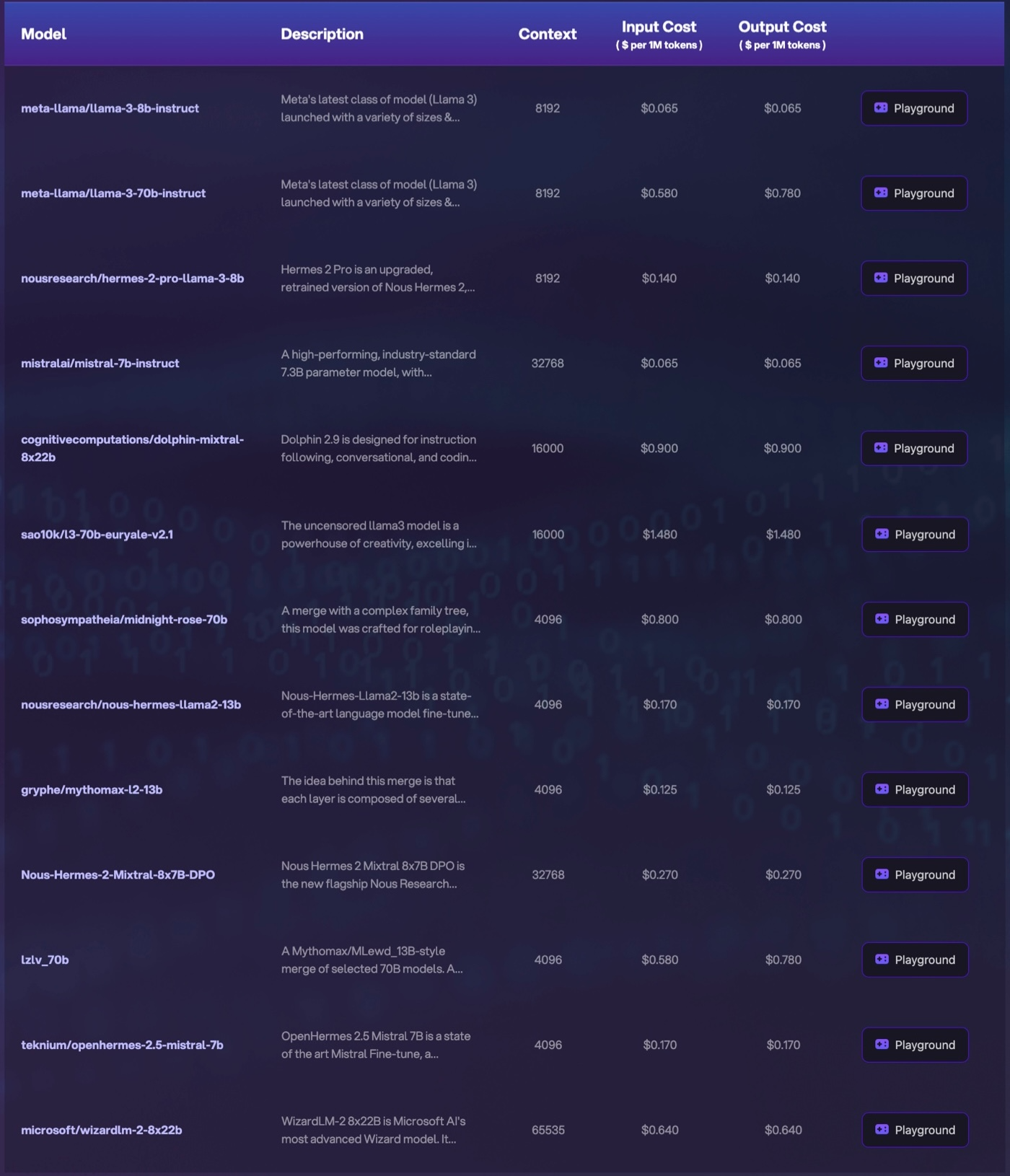
Step 2 Prepare a Domain-Specific Translation Memory (TM):
- Collect a set of approved translation pairs (called “fuzzy matches”) in your domain of interest.
- Structure the TM data with the source language sentence followed by the corresponding target language sentence.
Step 3 Implement In-Context Learning for Translation:
- When you need to translate a new source sentence, construct a prompt for the LLM that includes: 1. The new source sentence in the original language that you want to translate; 2. The relevant “fuzzy match” translation pairs from your TM
- Arrange the prompt with the source and target language pairs in descending order of similarity to the new source sentence.
- Pass this prompt to the LLM’s API and let it generate the translated output. The LLM will adapt its translation to match the style and terminology used in the TM.
Step 4 Optimize the In-Context Learning:
- Experiment with the number of “fuzzy match” translation pairs to include in the prompt, aiming for 5–10 relevant pairs.
- Monitor the translation quality and make adjustments to the prompt format, number of examples, and other parameters to achieve the best results.
Step 5 Combine with Encoder-Decoder MT Models:
- If available, incorporate the output of a strong encoder-decoder machine translation (MT) model into the prompt, along with the “fuzzy match” translation pairs.
- This can help further improve translation quality, especially for language pairs where the LLM alone may not yet match the performance of the encoder-decoder model.
Step 6 Continuously Refine and Expand the TM:
- Update your TM with new approved translation pairs as you translate more content.
- Periodically review and curate the TM to ensure it remains relevant and accurate for your domain-specific needs.
You can find the exact codes for approaches mentioned in the paper (e.g. extracting the fuzzy matches) here: https://github.com/ymoslem/Adaptive-MT-LLM
What Are the Future Directions for Translation With Large Language Models?
The paper “Adaptive Machine Translation with Large Language Models” suggests several future directions for translation with large language models (LLMs). Here are some key areas identified for further exploration and development:
Dynamic Few-Shot Example Selection:
Instead of using a fixed number of fuzzy matches, the selection process could be dynamic, choosing only high-quality matches above a certain similarity score. This could potentially enhance the performance by providing more relevant context.
Incorporating Glossary Terms or MT Outputs Based on Quality:
When integrating terms from a glossary or machine translation outputs from other systems, selecting those with specific quality characteristics could be beneficial. This selective integration could lead to better translation quality.
Phrase-Based Terminology Extraction:
The paper suggests exploring the use of longer phrases instead of individual terms for terminology extraction. This could be particularly useful for low-resource languages where longer context may improve translation accuracy.
Fine-Tuning for Low-Resource Languages and Rare Domains:
While the paper focuses on out-of-the-box performance, future work could involve fine-tuning the models for low-resource languages and specific domains. This could help in enhancing both the quality and efficiency of translations in these areas.
Experimentation with Open-Source LLMs:
The authors propose expanding experiments with open-source LLMs like BLOOM and BLOOMZ to cover more aspects of translation tasks. This could provide insights into the performance of these models compared to proprietary models like GPT-3.5.
Quality Estimation and Automatic Selection:
Developing automatic quality estimation methods to select the best translation from multiple alternatives could be a valuable area of research. This could involve comparing translations with and without the use of fuzzy matches and/or terminology.
Improving Tokenization for Non-Latin Languages:
Addressing the tokenization issues for non-Latin languages, as noted with GPT-3.5 and Arabic, could be crucial for improving the performance of LLMs across more language pairs.
Investigating Large-Scale Deployment and User Feedback Integration:
Research into how LLMs can be effectively deployed at scale in real-world translation scenarios, including the integration of user feedback to continuously improve translations.
Exploring the Use of Multimodal Inputs:
Future research could look into the use of multimodal inputs (e.g., images, audio) alongside text to provide additional context for translation tasks, especially for tasks involving descriptive or technical content.
Ethical Considerations and Bias Mitigation:
As with all AI applications, it will be important to study and address potential ethical concerns, including bias in translations, and develop methods to mitigate these issues.
Robustness and Generalizability:
Ensuring that LLMs can generalize well across different domains and maintain robust performance even with limited data for certain language pairs.
Conclusion
In conclusion, the journey to optimize large language models for translation tasks is multifaceted and dynamic. Reflecting on insights from “Adaptive Machine Translation with Large Language Models,” we have explored diverse strategies and experiments that underscore the potential for significant improvements in translation quality. From leveraging in-context learning with fuzzy matches to integrating encoder-decoder models and domain-specific terminology extraction, the advancements discussed here pave the way for enhanced accuracy and efficiency in language translation.
Looking ahead, future research directions highlighted in the paper, such as dynamic example selection, multimodal inputs, and ethical considerations, offer promising avenues for further exploration. These endeavors aim not only to refine the technical capabilities of LLMs across various languages and domains but also to address broader societal implications and ensure equitable access to high-quality translation tools.
References
Moslem, Y., Haque, R., Kelleher, J. D., & Way, A. (2023). Adaptive machine translation with large language models. arXiv. https://doi.org/10.48550/arXiv.2301.13294
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.