How Can Large Language Models Be Used in Medicine?

Introduction
How are large language models developed? How can they be used in medicine? What are some popular LLMs in medicine? How to train my own LLM in medicine? What are the limitations of LLM in medicine? In this blog, we will explore these questions one by one.
How Are Large Language Models Developed?
The development of large language models (LLMs) involves several key components (Thirunavukarasu et al., 2023):
Model Architecture
LLMs typically use neural network architectures that leverage deep learning techniques to represent the complex associative relationships between words in the text training data. The most well-known architecture is the Transformer, used in models like GPT (Generative Pre-trained Transformer).
Training Data
LLMs are trained on massive datasets containing billions of words from diverse sources like websites, books, and articles. For example, GPT-3 was trained on a 45 terabyte dataset comprising Common Crawl web pages, WebText, books, and Wikipedia.
Pretraining
The initial training process is called pretraining, which is usually unsupervised. It involves training the model on a language modeling task, where it learns to predict the next word in a sequence based on the previous words. Common pretraining approaches include causal language modeling, masked language modeling, and denoising autoencoders.
Model Scaling
As LLMs become larger (more parameters) and are trained on larger datasets with increasing computational resources, they develop improved few-shot and zero-shot capabilities, allowing them to perform well on unseen tasks with little or no task-specific training data.
Fine-tuning
After pretraining, LLMs undergo fine-tuning, where they are trained on specific tasks or datasets to optimize performance. For ChatGPT, fine-tuning involved exposing GPT-3 to prompts and responses from humans, and using reinforcement learning from human feedback (RLHF) to improve response quality. For LLMs in medicine, fine-tune on question-answering using medical exam questions, or on summarization using clinical notes.
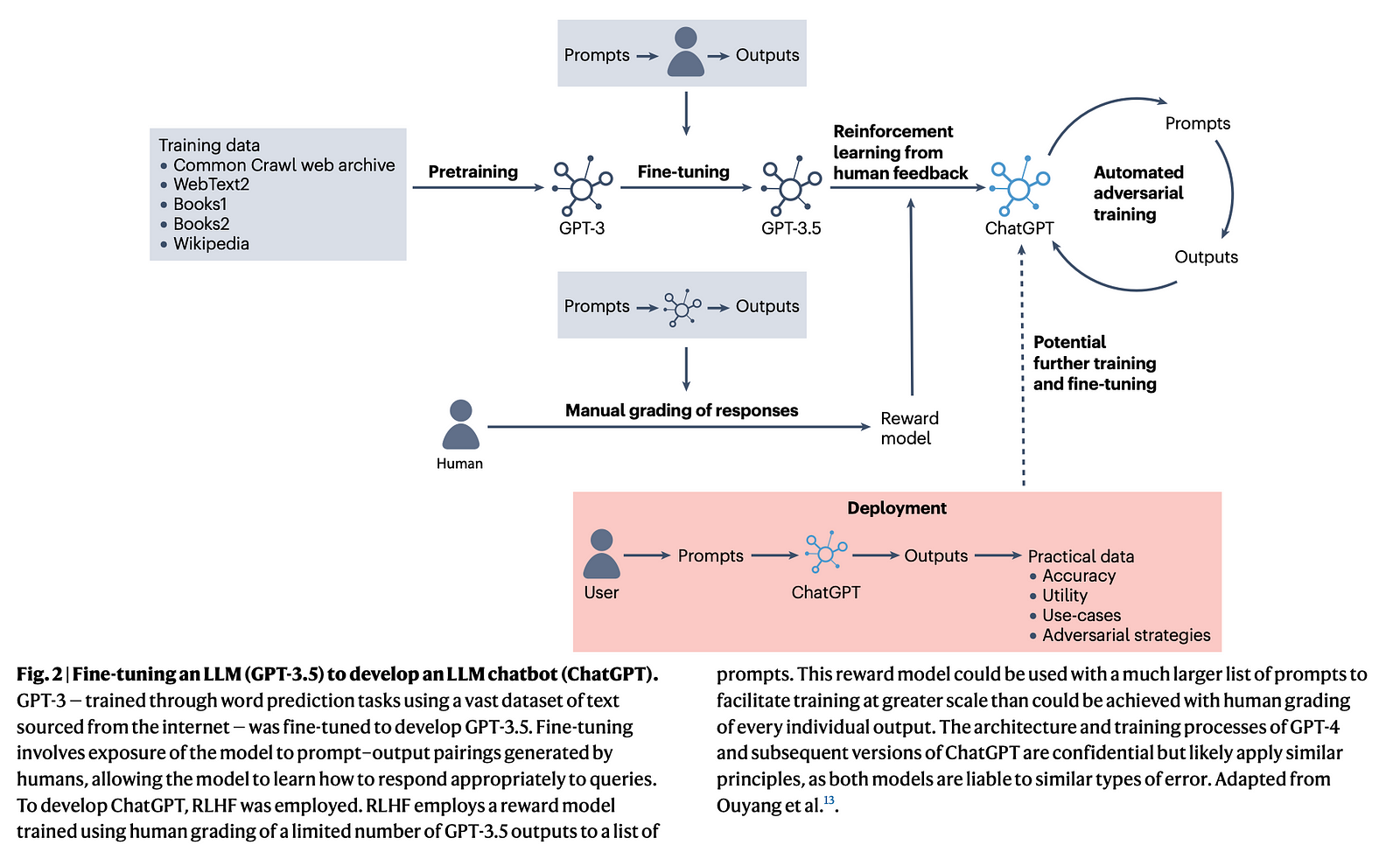
Continued Training
Some LLM applications like ChatGPT may undergo continued training and fine-tuning as they are deployed and interact with users, allowing them to learn and improve from real-world data and feedback.
How Can Large Language Models Be Used in Medicine?
Thirunavukarasu et al. (2023) discuss several scenarios and applications where large language models (LLMs) are being used or could potentially be leveraged in medicine:
Clinical Decision Support
LLMs like ChatGPT have demonstrated ability to achieve passing scores on medical licensing exams, suggesting potential for use in clinical decision making and providing diagnostic/treatment recommendations to healthcare providers.
Patient Education
LLMs could be used to generate personalized patient education materials, instructions, and explanations in plain language tailored to the patient’s health condition and background.
Medical Research
LLMs can assist researchers by summarizing scientific literature, generating hypotheses, analyzing data, and even helping to write research papers and grant proposals.
Medical Education
LLMs are being explored as virtual tutors or assistants for medical students and trainees to help with question answering, knowledge reinforcement, and practice for exams.
Clinical Documentation
LLMs could potentially improve efficiency by automating aspects of clinical documentation like note-taking and record summarization based on patient-provider dialogue.
Biomedical Question Answering
LLMs can rapidly retrieve and synthesize information from large medical knowledge bases to answer practitioners’ clinical queries.
Medical Coding and Billing
LLMs could assist with coding patient encounters accurately for billing by understanding clinical notes and mapping them to standardized codes.
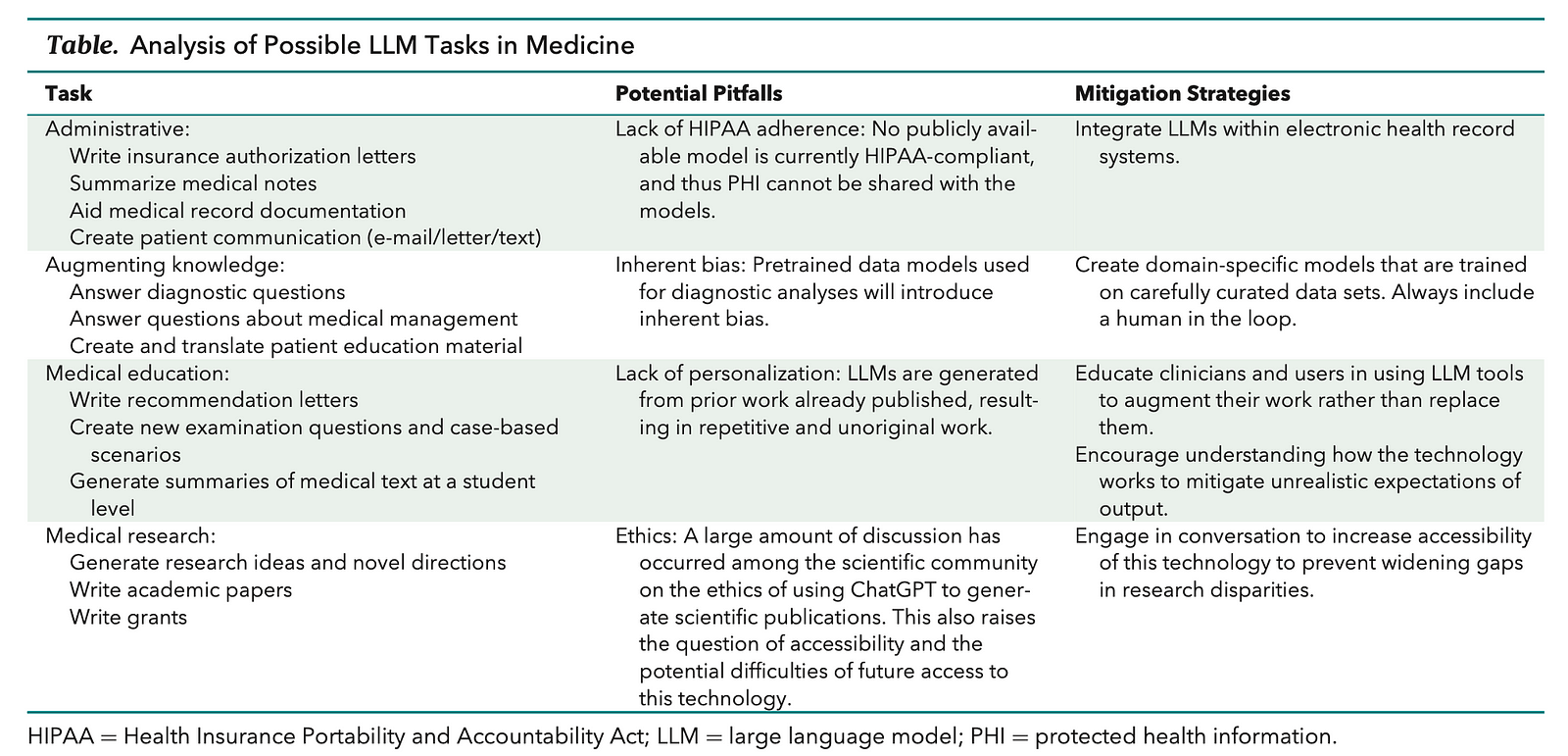
What Are Some Popular LLMs in Medicine?
GPT (Generative Pretrained Transformer) Series:
- GPT-3: A large model with about 175 billion parameters, known for its ability to generate human-like text and has been fine-tuned for various tasks.
- GPT-4: The latest version at the time of the articles, with enhanced capabilities including handling multimodal input such as images, text, and audio.
BERT (Bidirectional Encoder Representations from Transformers):
- BioBERT: Pretrained on biomedical literature, it is tailored for biomedical text mining.
- PubMedBERT: Similar to BioBERT but specifically trained on PubMed abstracts.
- ClinicalBERT: Adapted for clinical notes and trained on electronic health records.
PaLM (Pathways Language Model):
- Flan-PaLM: Fine-tuned version of PaLM for medical question answering, achieving state-of-the-art results.
- Med-PaLM: An instruction-tuned model demonstrating capabilities in clinical knowledge, scientific consensus, and medical reasoning.
BioGPT:
- A model pretrained on PubMed abstracts for tasks including question answering, relation extraction, and document classification.
BioMedLM (formerly known as PubMedGPT):
- Pretrained on both PubMed abstracts and full texts, showcasing advancements in biomedical LLMs.
LLaMA (LLMs for Academic Medicine):
- An open-source family of models with varying sizes, designed for academic and medical applications.
Clinical Foundation Models:
- These are models trained from scratch using electronic health record data, which can require fewer labeled data and handle multimodal data effectively.
InstructGPT:
- A model that has been fine-tuned to follow instructions and has been evaluated for healthcare utility.
Megatron-LM:
- A large-scale language model developed by NVIDIA, known for its size and computational requirements.
How to Train My Own LLM in Medicine?
Step 1: Choose an API and Setup
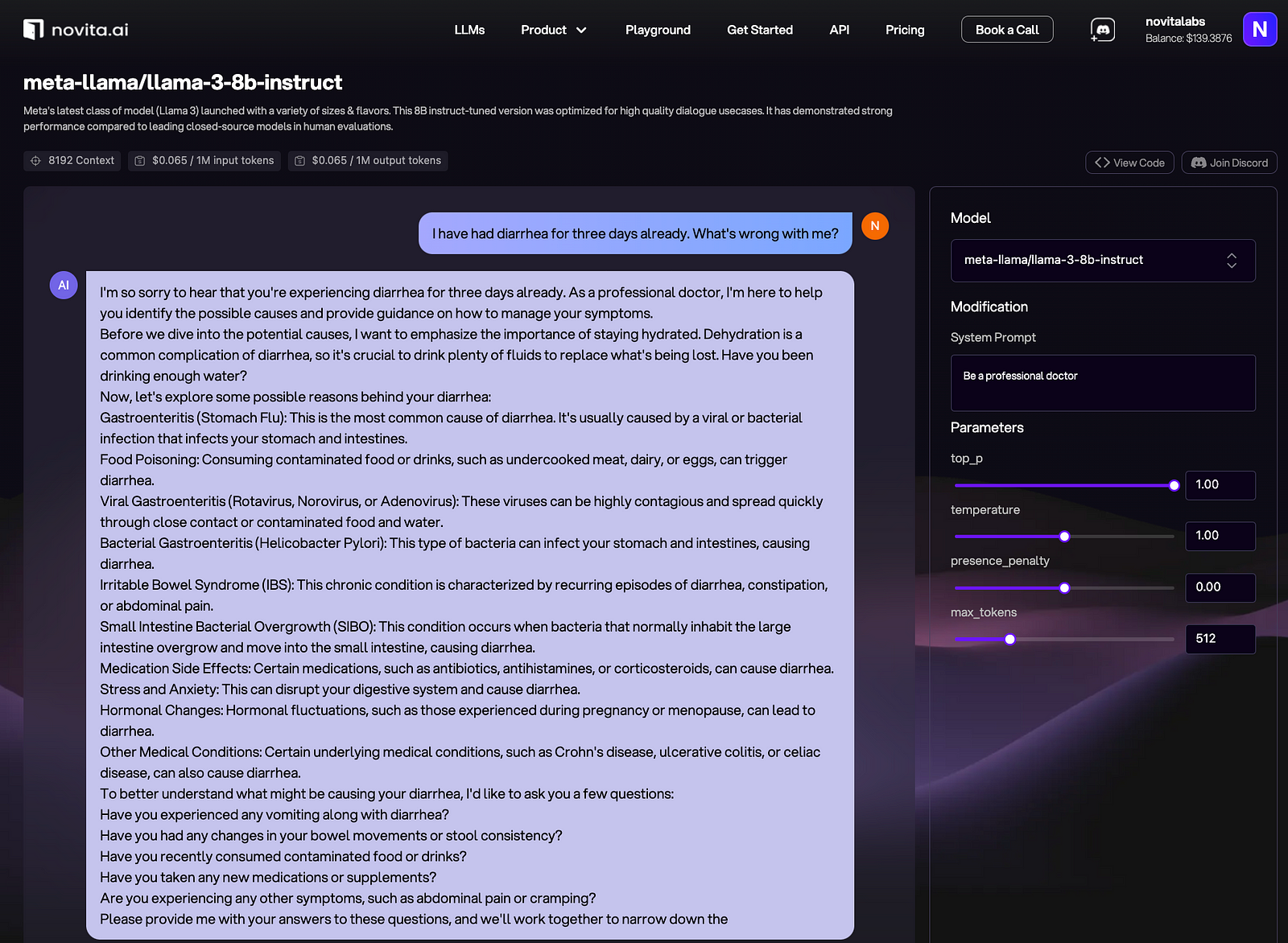
Select an API that supports training custom models, such as Novita AI LLM API which provides powerful pre-trained models and tools for customization, including Llama 3 8B and 70B. Novita AI provides compatibility for the OpenAI API standard, allowing easier integrations into existing applications.
Before integrating APIs, you should evaluate the performances of available LLMs so that you can decide which ones are up to your expectations for your own medical LLM.
Step 2: Gather and Prepare Data
Collect a large dataset of medical text relevant to your specific domain (e.g., clinical notes, research papers, medical literature). Ensure your dataset is diverse and representative of the language and topics you want your model to understand.
Step 3: Preprocess Data
Clean and preprocess your dataset to remove noise and irrelevant information. This may involve:
- Tokenization: Breaking text into tokens (words or subwords).
- Removing stopwords: Common words that do not contribute much to the meaning.
- Normalizing text: Converting text to lowercase, handling abbreviations, etc.
Step 4: Fine-tune the Pre-trained Model
Most LLM APIs provide pre-trained models that you can fine-tune on your specific dataset. Fine-tuning involves:
- Initializing your model with the pre-trained weights from the API.
- Providing your dataset to the API’s training interface.
- Specifying parameters such as batch size, learning rate, number of epochs, etc.
Step 5: Monitor Training Progress
During fine-tuning, monitor metrics such as loss and accuracy to gauge the model’s performance. Adjust hyperparameters if necessary to improve performance.
Step 6: Evaluate Model Performance
Once training is complete, evaluate your model on a separate validation dataset to assess its generalization ability and accuracy. Use metrics relevant to your specific tasks (e.g., accuracy, F1 score for classification tasks).
Step 7: Iterative Improvement
Iteratively improve your model by:
- Fine-tuning with additional data.
- Adjusting hyperparameters.
- Incorporating feedback from model evaluation.
Step 8: Deploy and Use
After achieving satisfactory performance, deploy your model via the API for inference. Ensure your deployment meets any regulatory or ethical guidelines for medical applications.
Step 9: Maintain and Update
Regularly update your model with new data to keep it current and improve its performance over time. Monitor for drift and retrain as necessary.
Considerations:
- Ethical and Legal Considerations: Ensure compliance with data privacy laws (e.g., HIPAA), ethical guidelines, and regulations governing medical AI applications.
- Resource Requirements: Training an LLM can be resource-intensive (compute power, data storage), so plan accordingly.
- Validation: Validate your model’s predictions with domain experts to ensure reliability and safety in medical applications.
By following these steps, you can effectively train your own medical LLM using an API, leveraging its pre-trained capabilities and customizing it to your specific needs in the healthcare domain.
What Are the Limitations of Large Language Models in Medicine?
Omiye et al. (2024) and Thirunavukarasu et al. (2023) have noticed the following limitations of LLMs in medicine:
Accuracy Issues
The outputs of LLMs rely heavily on the quality and completeness of the training data. Very large datasets cannot be fully vetted, and some information may be outdated.
Lack of Domain-specificity
Most LLMs are trained on general data not specific to healthcare domains. This can result in biased or incorrect outputs for medical tasks.
Lack of True Understanding
LLMs generate outputs based on statistical patterns in the training data, without true comprehension. They can produce nonsensical or fictitious responses.
Bias and Fairness Issues
The training datasets encode societal biases against minority groups, disabilities, genders etc. which get reflected in LLM outputs.
Privacy Concerns
Currently available public LLMs are not HIPAA-compliant, meaning they cannot be directly exposed to protected health information from patient records.
Lack of Explainability
The inner workings and reasoning process of large LLMs are opaque “black boxes”, making it difficult to understand how they arrive at particular outputs for auditing purposes.
Over-Reliance On LLMs
There are ethics concerns around overreliance on LLM outputs, which could promote plagiarism or stifle original thinking in medical research and education if not used judiciously.
Conclusion
In conclusion, large language models (LLMs) offer significant promise in revolutionizing medical applications, from clinical decision support to medical education and research. Despite their potential benefits, challenges such as accuracy limitations, biases, privacy concerns, and the opaque nature of outputs need to be addressed for responsible integration into healthcare. Continued collaboration between AI researchers, healthcare providers, and policymakers is crucial to harnessing LLMs’ potential while ensuring ethical and effective deployment in medical settings.
References
Omiye, J. A., Gui, H., Rezaei, S. J., Zou, J., & Daneshjou, R. (2024). Large Language Models in Medicine: The Potentials and Pitfalls : A Narrative Review. Annals of Internal Medicine, 177(2), 210–220. https://doi.org/10.7326/M23-2772
Thirunavukarasu, A. J., Ting, D. S. J., Elangovan, K., Gutierrez, L., Tan, T. F., & Ting, D. S. W. (2023). Large language models in medicine. Nature Medicine, 29(8), 1930–1940. https://doi.org/10.1038/s41591-023-02448-8
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.