Claude 3 Haiku and Other Budget King LLMs

Introduction
Are you on the lookout for a budget-friendly yet powerful LLM API that can keep up with your dynamic needs? What if I told you that Claude 3 Haiku, the most compact and swift model from Anthropic, could be the answer?
In this blog, we’ll uncover the essence of Claude 3 Haiku, exploring its key features, technical details, and how it performs against benchmarks. We’ll delve into real-life scenarios where Claude 3 Haiku shines and discuss its pricing strategy and other budget king LLMs.
So, if you’re curious about harnessing the power of LLM without breaking the bank, keep reading!
What Is Claude 3 Haiku: An Overview
Claude 3 Haiku is the most compact and fastest model in the Claude 3 family by Anthropic, designed for near-instant responsiveness. It is tailored for applications that require quick and accurate answers to simple queries and requests. With its unmatched speed, Claude 3 Haiku is poised to deliver seamless AI experiences that closely mimic human interactions, making it an ideal choice for customer interactions, content moderation, and cost-saving tasks.

What Are the Key Features of Claude 3 Haiku?
Key features of Claude 3 Haiku include:
Affordability
Claude 3 Haiku is the fastest and least expensive model in the Claude 3 family.
Multimodal Capabilities
It includes vision capabilities to process and analyze image data, allowing for richer context in use cases.
Performance
Demonstrates strong performance in text-based tasks such as reasoning, math, and coding, outperforming previous models in the Claude series.
Multilingual Fluency
Enhanced fluency in non-English languages, making it versatile and effective for a global audience.
What Are the Technical Details of Claude 3 Haiku?
Training Dataset
Claude 3 Haiku was trained on a diverse and comprehensive dataset, which includes:
- Publicly Available Internet Data: Information available on the web as of August 2023.
- Non-Public Third-Party Data: Specialized datasets obtained from various third-party sources.
- Data Labeling Services: Data curated and labeled by professional data labeling services.
- Paid Contractors: Contributions from contractors hired specifically for data collection and preparation.
- Internally Generated Data: Data created and managed internally by Anthropic for training purposes.
To ensure high-quality data, several data cleaning and filtering methods were applied, such as deduplication and classification. Notably, no user-submitted data (prompts or outputs) from Claude users were used in training.
Training Techniques
Claude 3 Haiku employs several advanced training techniques:
- Unsupervised Learning: This foundational technique allows the model to learn language patterns and structures by predicting the next word in a sequence.
- Constitutional AI: A unique approach to align the model with human values. The model is guided by a constitution consisting of ethical and behavioral principles derived from sources like the UN Declaration of Human Rights. This method ensures that the model’s responses are helpful, harmless, and honest.
- Reinforcement Learning from Human Feedback (RLHF): This technique uses feedback from human evaluators to fine-tune the model’s behavior. Evaluators rate the model’s responses, and this feedback is used to improve the model’s performance.
Context Window
Claude 3 Haiku supports a substantial context window of up to 200k tokens.
Core Frameworks and Infrastructure
The training and operation of Claude 3 Haiku leverage robust cloud infrastructure and machine learning frameworks:
- Hardware: Utilizes the computing power of Amazon Web Services (AWS) and Google Cloud Platform (GCP).
- Core Frameworks: The model is built using leading machine learning frameworks, including:
- PyTorch: A popular open-source machine learning library for training and developing deep learning models.
- JAX: A library designed for high-performance numerical computing and machine learning, known for its ability to handle complex mathematical computations efficiently.
- Triton: An optimization framework that enhances the performance of machine learning models on modern hardware.
Benchmark Performance Comparison: Claude 3 Haiku vs Llama 3
MMLU (5-shot)
Massive Multitask Language Understanding measures the model’s performance across a wide range of academic subjects and tasks using a few provided examples (5-shot learning).
- Meta Llama 3 8B: 68.4
- Meta Llama 3 70B: 82.0
- Claude 3 Haiku: 65.2
GPQA (0-shot)
Graduate-Level Performance Question Answering evaluates the model’s ability to answer complex, graduate-level questions without any prior examples (0-shot learning).
- Meta Llama 3 8B: 34.2
- Meta Llama 3 70B: 39.5
- Claude 3 Haiku: 33.3
HumanEval (0-shot)
This benchmark assesses the model’s capability to generate correct and functional code snippets based on given programming problems without any prior examples (0-shot learning).
- Meta Llama 3 8B: 62.2
- Meta Llama 3 70B: 81.7
- Claude 3 Haiku: 75.9
GSM-8K (8-shot, CoT)
Grade School Math tests the model’s ability to solve grade school-level math problems using multiple examples (8-shot) and a step-by-step reasoning approach (Chain of Thought).
- Meta Llama 3 8B: 79.6
- Meta Llama 3 70B: 93.0
- Claude 3 Haiku: 88.9
MATH (4-shot, CoT)
The MATH benchmark evaluates the model’s proficiency in solving high school-level math problems with a few provided examples (4-shot) and a structured reasoning process (Chain of Thought).
- Meta Llama 3 8B: 30.0
- Meta Llama 3 70B: 50.4
- Claude 3 Haiku: 40.9
Summary
Meta Llama 3 70B consistently outperforms both Meta Llama 3 8B and Claude 3 Haiku across all benchmarks. Claude 3 Haiku performs better than Meta Llama 3 8B in certain tasks, like HumanEval, but generally falls between the two Llama models in overall performance.
What Are the Real-life Scenarios of Using Claude 3 Haiku?
Interactive Coding Assistance:
Developers can interact with Claude 3 Haiku to receive real-time coding support, including error diagnosis, code optimization suggestions, and implementation of new features across different programming languages.
Financial Forecasting:
The model can be employed to predict future market trends by analyzing historical financial data and identifying patterns that may not be immediately apparent to human analysts.
Market Strategy Development:
By reviewing and synthesizing information from various sources, Claude 3 Haiku can help in developing market entry strategies, competitive analysis, and growth planning.
Database Management:
It can assist in automating database queries, data extraction, and transformation processes, making it easier to manage large volumes of information.
R&D Hypothesis Testing:
In research environments, Claude 3 Haiku can assist in the initial stages of hypothesis generation and provide a foundation for experimental design and testing.
Drug Discovery Visualization:
With its multimodal capabilities, Claude 3 Haiku can help visualize complex molecular structures and biochemical pathways, aiding researchers in the drug discovery process.
Strategic Financial Analysis:
Claude 3 Haiku can be used to analyze financial statements, assess investment opportunities, and perform risk analysis to support strategic financial planning.
What Is the Pricing of Claude 3 Haiku API?
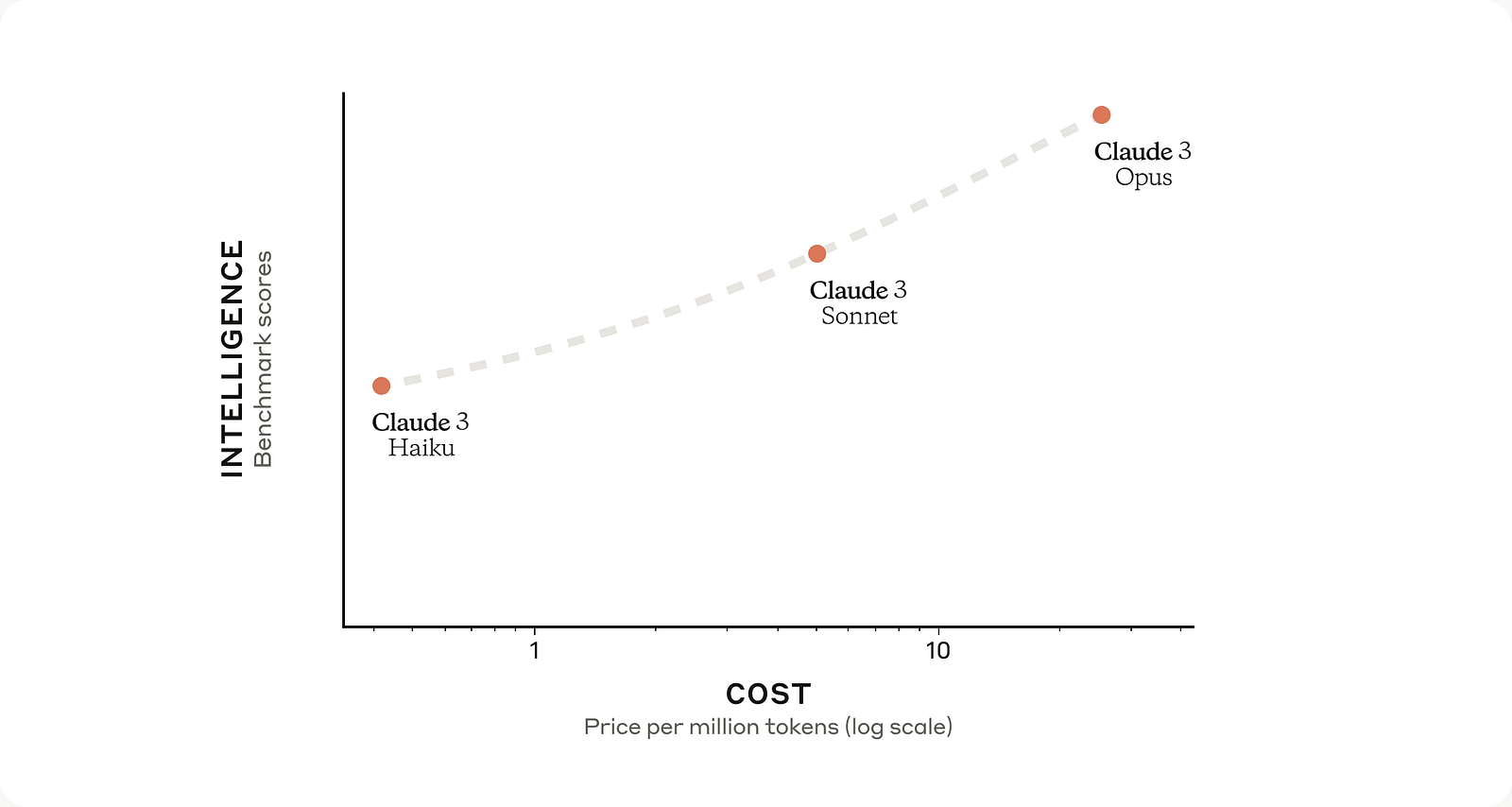
From the pricing details, it’s clear that Claude 3 Haiku is the most cost-effective option in the Claude 3 family, with the lowest input and output costs. It is priced at $0.25 per million input tokens and $1.25 per million output tokens. In comparison, Claude 3 Sonnet costs $3 per million input tokens and $15 per million output tokens, while Claude 3 Opus is priced at $15 per million input tokens and $75 per million output tokens.
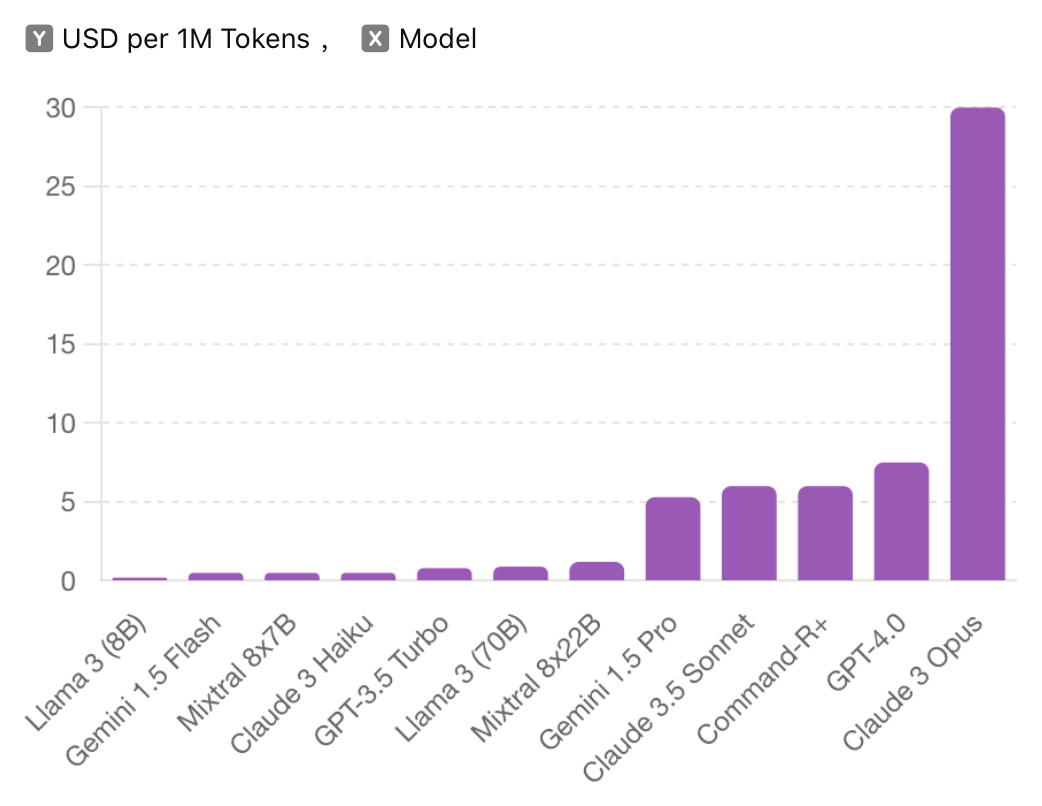
Outside the Claude 3 family, Claude 3 Haiku still deserves the title of budget king. Priced at average with a price of $0.50 per 1M Tokens (blended 3:1), it is notably more affordable than other models such as GPT-3.5 Turbo at $0.8, Llama 3 (70B) at $0.9, and Mixtral 8x22B at $1.2. Additionally, high-end models like Gemini 1.5 Pro, which costs $5.3, Command-R+ at $6, and GPT-4.0 at $7.5 per million tokens, make Claude 3 Haiku an exceptionally cost-effective option.
What Are Other Budget King LLM APIs Besides Claude 3 Haiku?
Novita AI aims to provide developers with low-cost LLM APIs with strong performances which enables widespread accessibility, encouraging innovation and experimentation across different industries. Here are some budget king LLM APIs on Novita AI:
meta-llama/llama-3–8b-instruct
Meta’s latest class of model (Llama 3) launched with a variety of sizes & flavors. This 8B instruct-tuned version was optimized for high quality dialogue usecases. It has demonstrated strong performance compared to leading closed-source models in human evaluations.
meta-llama/llama-3–70b-instruct
Meta’s latest class of model (Llama 3) launched with a variety of sizes & flavors. This 70B instruct-tuned version was optimized for high quality dialogue usecases. It has demonstrated strong performance compared to leading closed-source models in human evaluations.
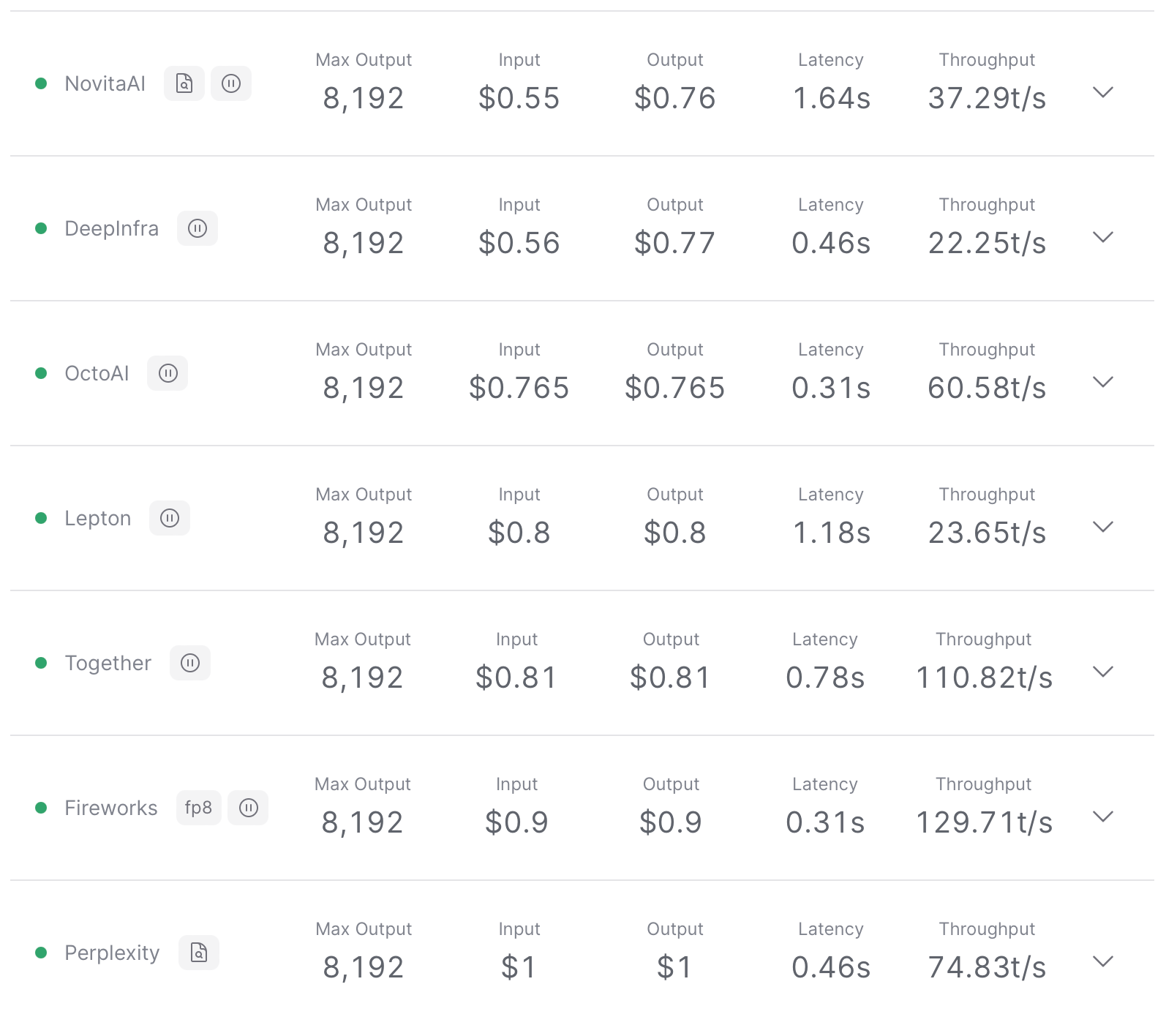
nousresearch/hermes-2-pro-llama-3–8b
Hermes 2 Pro is an upgraded, retrained version of Nous Hermes 2, consisting of an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house.
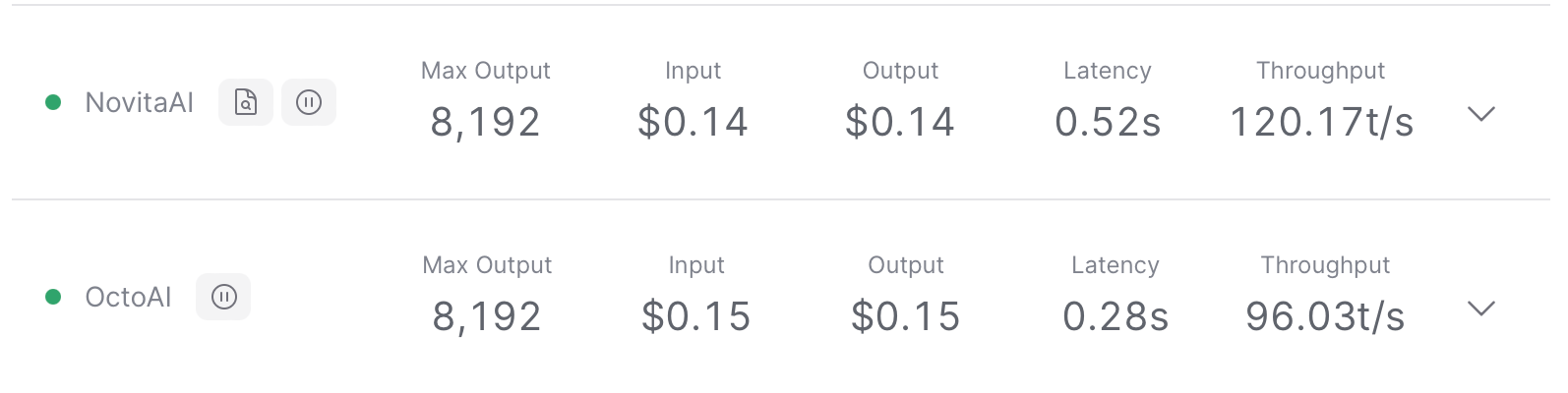
mistralai/mistral-7b-instruct
Mistral 7b instruct is a high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length.
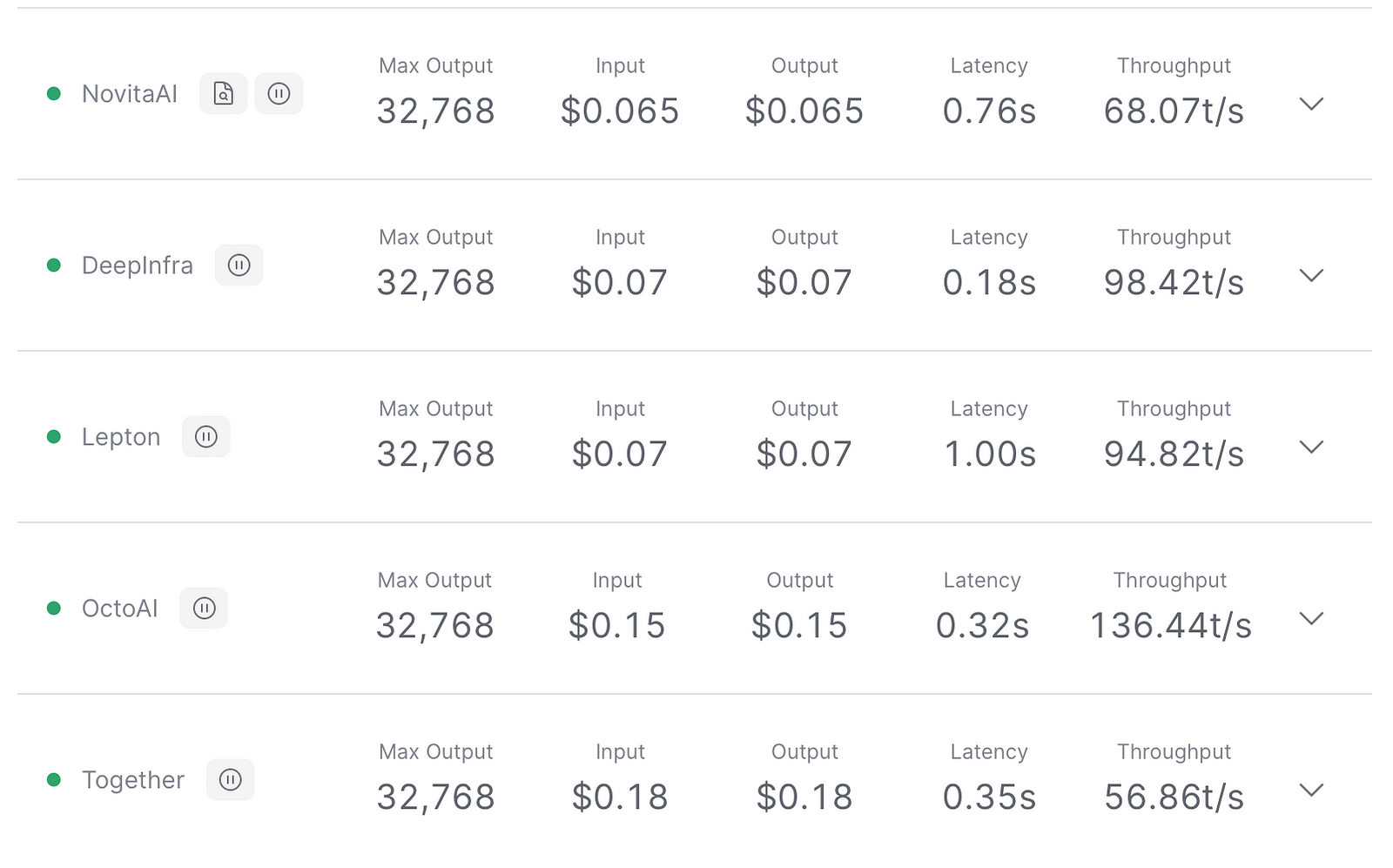
teknium/openhermes-2.5-mistral-7b
Openhermes-2.5-mistral-7b is a continuation of OpenHermes 2 model, trained on additional code datasets. Potentially the most interesting finding from training on a good ratio (est. of around 7–14% of the total dataset) of code instruction was that it has boosted several non-code benchmarks, including TruthfulQA, AGIEval, and GPT4All suite. It did however reduce BigBench benchmark score, but the net gain overall is significant.
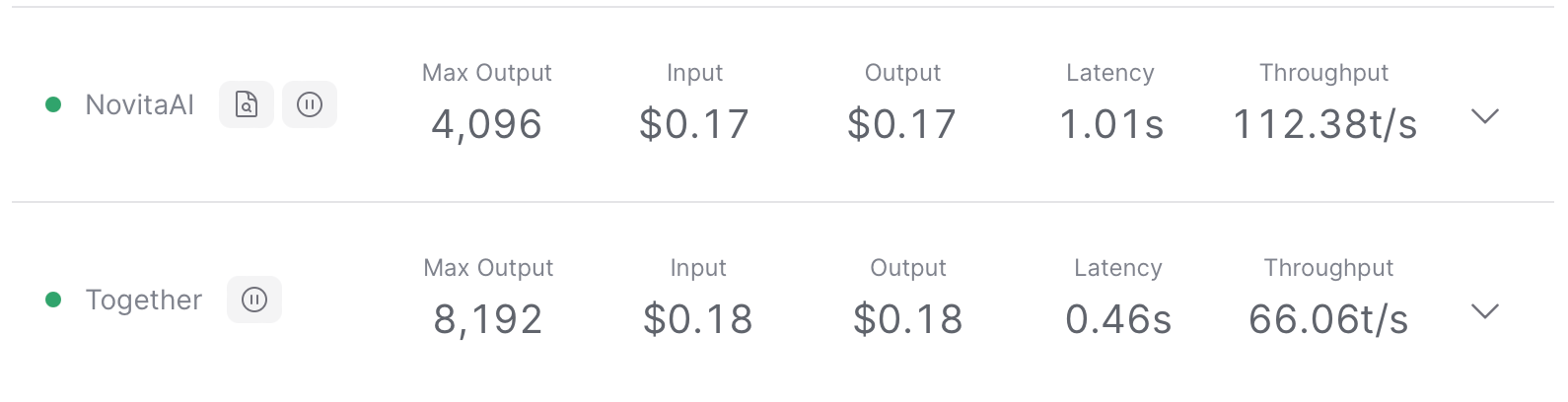
Conclusion
To wrap up, our exploration of Claude 3 Haiku has highlighted its exceptional standing as a budget king in the realm of AI, offering remarkable value with its cost-effective pricing and robust capabilities. It has proven to be a versatile asset for a variety of tasks, from coding to content moderation, all while maintaining a swift response time that is crucial for real-time interactions.
Moreover, the landscape of budget-friendly LLMs is expanding, with other models like Meta’s Llama 3, Nous Research’s Hermes 2 Pro, and MistralAI’s Mistral 7b Instruct joining the ranks. These models, available through platforms such as Novita AI, are not only accessible but also encourage innovation by providing powerful AI tools to a broader audience.
Frequently Asked Questions
1. Is Claude 3 better than ChatGPT?
Claude exhibits a distinctly more “human” and empathetic demeanor compared to ChatGPT, which often appears more robotic and logical. Although both models excel in analytical tasks, Claude’s larger context window enhances its ability to handle longer documents more effectively.
2. Is Claude good for coding?
Yes, Claude is highly effective for coding. The model’s ability to accurately translate instructions into functional code makes it a reliable choice for coding tasks.
Novita AI is the all-in-one cloud platform that empowers your AI ambitions. With seamlessly integrated APIs, serverless computing, and GPU acceleration, we provide the cost-effective tools you need to rapidly build and scale your AI-driven business. Eliminate infrastructure headaches and get started for free — Novita AI makes your AI dreams a reality.
Recommended Reading
Claude 3 Opus API vs. Novita AI LLM API: A Comparison Guide
Claude LLM - Pros and Cons Compared with Other LLMs